 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA semantic web approach to uplift decentralized household energy data
Aug 26, 2022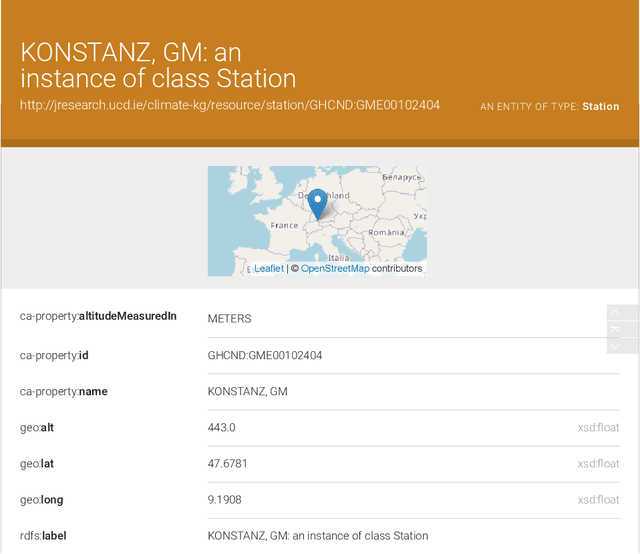

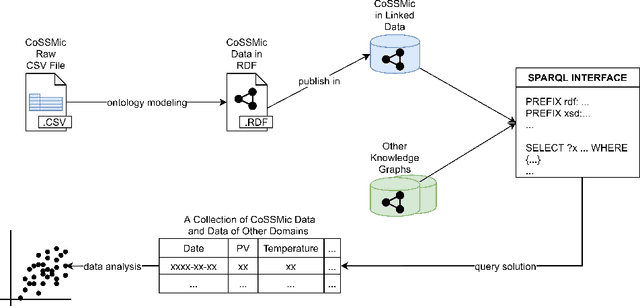

In a decentralized household energy system comprised of various devices such as home appliances, electric vehicles, and solar panels, end-users are able to dig deeper into the system's details and further achieve energy sustainability if they are presented with data on the electric energy consumption and production at the granularity of the device. However, many databases in this field are siloed from other domains, including solely information pertaining to energy. This may result in the loss of information (e.g. weather) on each device's energy use. Meanwhile, a large number of these datasets have been extensively used in computational modeling techniques such as machine learning models. While such computational approaches achieve great accuracy and performance by concentrating only on a local view of datasets, model reliability cannot be guaranteed since such models are very vulnerable to data input fluctuations when information omission is taken into account. This article tackles the data isolation issue in the field of smart energy systems by examining Semantic Web methods on top of a household energy system. We offer an ontology-based approach for managing decentralized data at the device-level resolution in a system. As a consequence, the scope of the data associated with each device may easily be expanded in an interoperable manner throughout the Web, and additional information, such as weather, can be obtained from the Web, provided that the data is organized according to W3C standards.
A Clustering Framework for Residential Electric Demand Profiles
May 17, 2021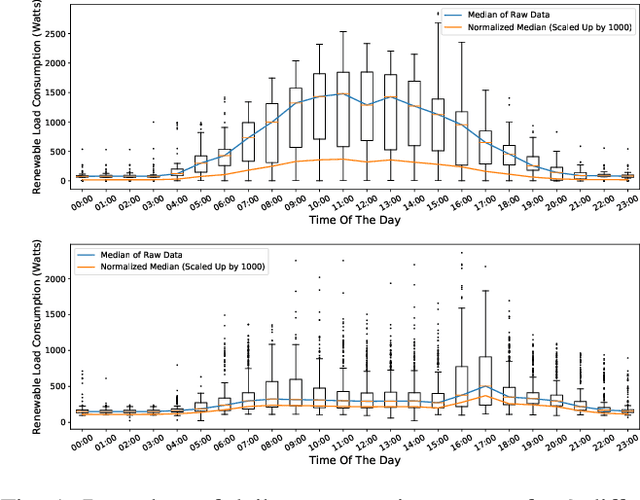
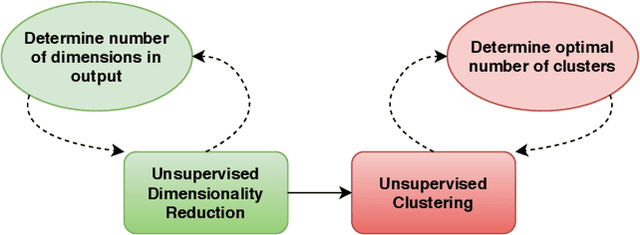
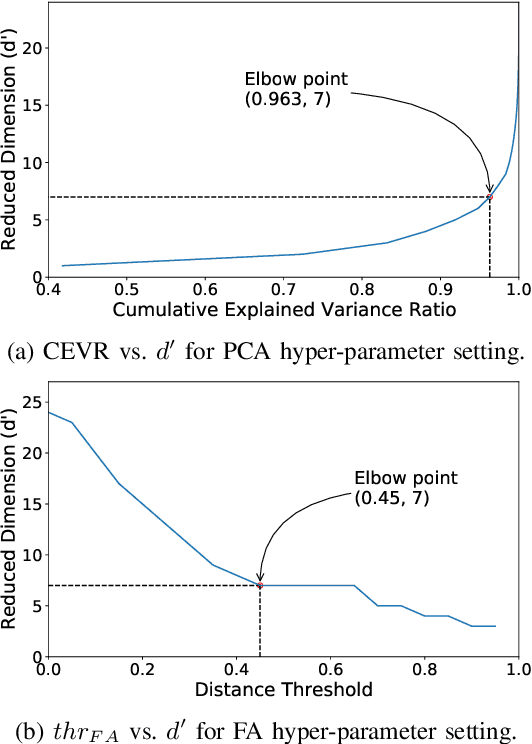
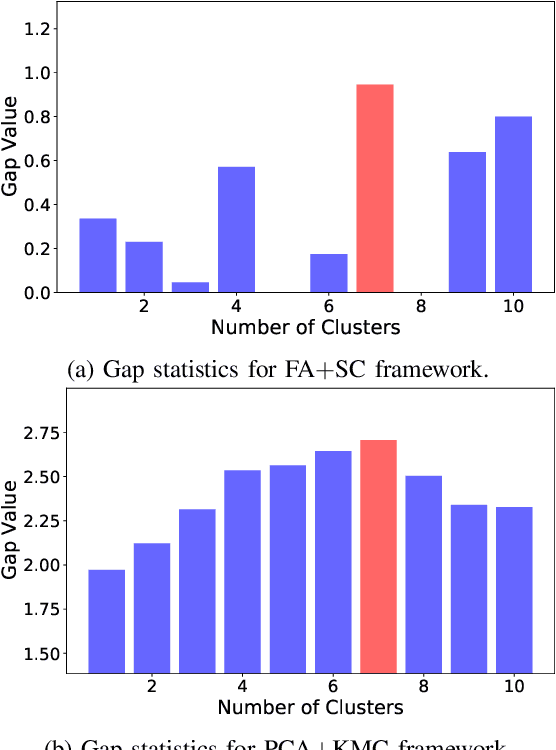
The availability of residential electric demand profiles data, enabled by the large-scale deployment of smart metering infrastructure, has made it possible to perform more accurate analysis of electricity consumption patterns. This paper analyses the electric demand profiles of individual households located in the city Amsterdam, the Netherlands. A comprehensive clustering framework is defined to classify households based on their electricity consumption pattern. This framework consists of two main steps, namely a dimensionality reduction step of input electricity consumption data, followed by an unsupervised clustering algorithm of the reduced subspace. While any algorithm, which has been used in the literature for the aforementioned clustering task, can be used for the corresponding step, the more important question is to deduce which particular combination of algorithms is the best for a given dataset and a clustering task. This question is addressed in this paper by proposing a novel objective validation strategy, whose recommendations are then cross-verified by performing subjective validation.
Validating Clustering Frameworks for Electric Load Demand Profiles
Feb 26, 2021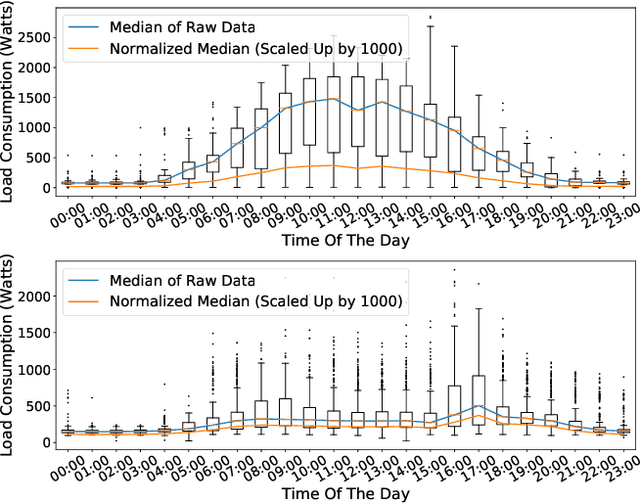
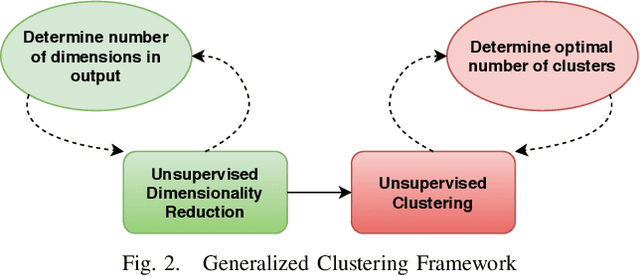
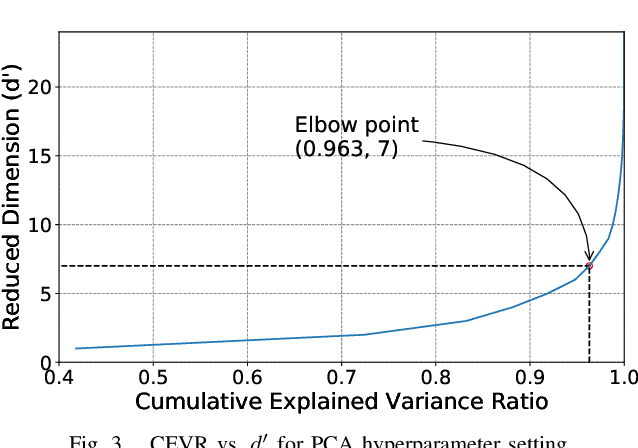

Large-scale deployment of smart meters has made it possible to collect sufficient and high-resolution data of residential electric demand profiles. Clustering analysis of these profiles is important to further analyze and comment on electricity consumption patterns. Although many clustering techniques have been proposed in the literature over the years, it is often noticed that different techniques fit best for different datasets. To identify the most suitable technique, standard clustering validity indices are often used. These indices focus primarily on the intrinsic characteristics of the clustering results. Moreover, different indices often give conflicting recommendations which can only be clarified with heuristics about the dataset and/or the expected cluster structures -- information that is rarely available in practical situations. This paper presents a novel scheme to validate and compare the clustering results objectively. Additionally, the proposed scheme considers all the steps prior to the clustering algorithm, including the pre-processing and dimensionality reduction steps, in order to provide recommendations over the complete framework. Accordingly, the proposed strategy is shown to provide better, unbiased, and uniform recommendations as compared to the standard Clustering Validity Indices.