 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing U-Net Network for Efficient Brain Tumor Segmentation in MRI Images
Nov 03, 2022
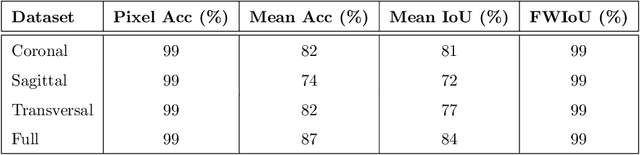
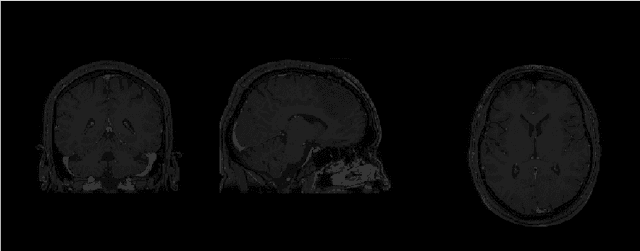
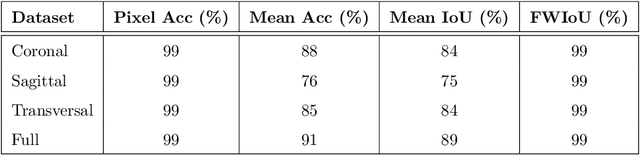
Magnetic Resonance Imaging (MRI) is the most commonly used non-intrusive technique for medical image acquisition. Brain tumor segmentation is the process of algorithmically identifying tumors in brain MRI scans. While many approaches have been proposed in the literature for brain tumor segmentation, this paper proposes a lightweight implementation of U-Net. Apart from providing real-time segmentation of MRI scans, the proposed architecture does not need large amount of data to train the proposed lightweight U-Net. Moreover, no additional data augmentation step is required. The lightweight U-Net shows very promising results on BITE dataset and it achieves a mean intersection-over-union (IoU) of 89% while outperforming the standard benchmark algorithms. Additionally, this work demonstrates an effective use of the three perspective planes, instead of the original three-dimensional volumetric images, for simplified brain tumor segmentation.
On the Relationship Between Ground- and Satellite- Based Global Horizontal Irradiance
Jun 15, 2022



Global horizontal irradiance (GHI) plays a significant role in maintaining the earth's ecological balance and generating electricity in photovoltaic systems. While the satellites have more range, they have been shown to over/under-estimate the true values of GHI that are observed at the ground-based stations. Hence, this study aims at analyzing the relationship between these two sources of GHI data in order to better and effectively utilize the reach of satellites for GHI analysis. The paper identifies a near linear relationship between the two and thereby concludes that an approximate mapping from satellite- to ground-based GHI values can be obtained.
Monitoring Atmospheric Pollutants From Ground-based Observations
Oct 21, 2021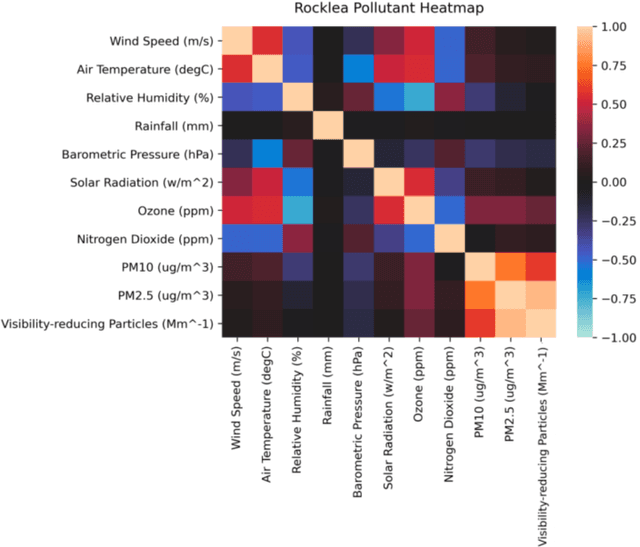
Remote sensing analysts continuously monitor the amount of pollutants in the atmosphere. They are usually performed via satellite images. However, these images suffer from low temporal and low spatial resolution. Therefore, observations recorded from the ground offer us a fantastic alternative. There are low-cost sensors that continuously record the PM$_{2.5}$ and PM$_{10}$ concentration levels in the atmosphere. In this position paper, we provide an overview of the state-of-the-art techniques for pollutant forecasting. We establish the interdependence of meteorological parameters on atmospheric pollutants. Our case study in this paper is based on the island of Australia.
Detecting Blurred Ground-based Sky/Cloud Images
Oct 19, 2021


Ground-based whole sky imagers (WSIs) are being used by researchers in various fields to study the atmospheric events. These ground-based sky cameras capture visible-light images of the sky at regular intervals of time. Owing to the atmospheric interference and camera sensor noise, the captured images often exhibit noise and blur. This may pose a problem in subsequent image processing stages. Therefore, it is important to accurately identify the blurred images. This is a difficult task, as clouds have varying shapes, textures, and soft edges whereas the sky acts as a homogeneous and uniform background. In this paper, we propose an efficient framework that can identify the blurred sky/cloud images. Using a static external marker, our proposed methodology has a detection accuracy of 94\%. To the best of our knowledge, our approach is the first of its kind in the automatic identification of blurred images for ground-based sky/cloud images.
Using GANs to Augment Data for Cloud Image Segmentation Task
Jun 06, 2021

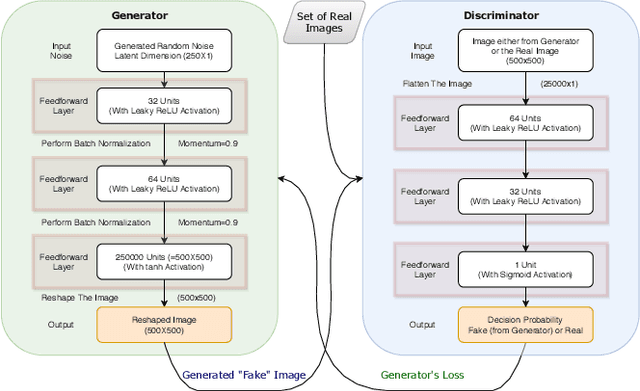

While cloud/sky image segmentation has extensive real-world applications, a large amount of labelled data is needed to train a highly accurate models to perform the task. Scarcity of such volumes of cloud/sky images with corresponding ground-truth binary maps makes it highly difficult to train such complex image segmentation models. In this paper, we demonstrate the effectiveness of using Generative Adversarial Networks (GANs) to generate data to augment the training set in order to increase the prediction accuracy of image segmentation model. We further present a way to estimate ground-truth binary maps for the GAN-generated images to facilitate their effective use as augmented images. Finally, we validate our work with different statistical techniques.
A Clustering Framework for Residential Electric Demand Profiles
May 17, 2021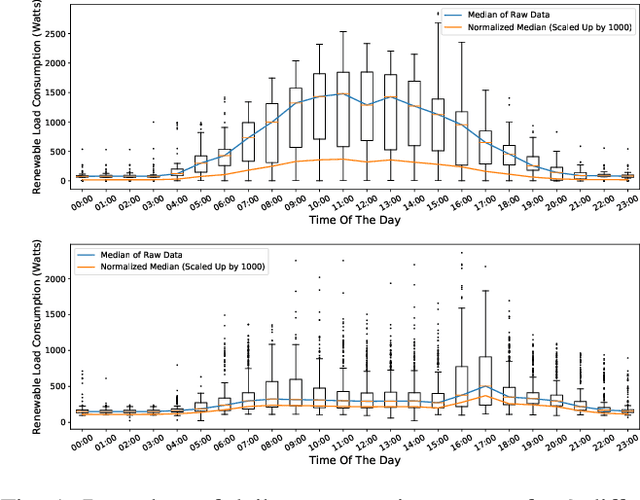
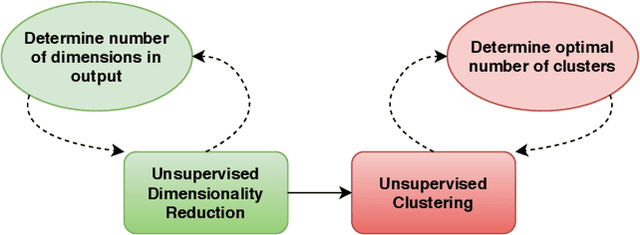
The availability of residential electric demand profiles data, enabled by the large-scale deployment of smart metering infrastructure, has made it possible to perform more accurate analysis of electricity consumption patterns. This paper analyses the electric demand profiles of individual households located in the city Amsterdam, the Netherlands. A comprehensive clustering framework is defined to classify households based on their electricity consumption pattern. This framework consists of two main steps, namely a dimensionality reduction step of input electricity consumption data, followed by an unsupervised clustering algorithm of the reduced subspace. While any algorithm, which has been used in the literature for the aforementioned clustering task, can be used for the corresponding step, the more important question is to deduce which particular combination of algorithms is the best for a given dataset and a clustering task. This question is addressed in this paper by proposing a novel objective validation strategy, whose recommendations are then cross-verified by performing subjective validation.
Validating Clustering Frameworks for Electric Load Demand Profiles
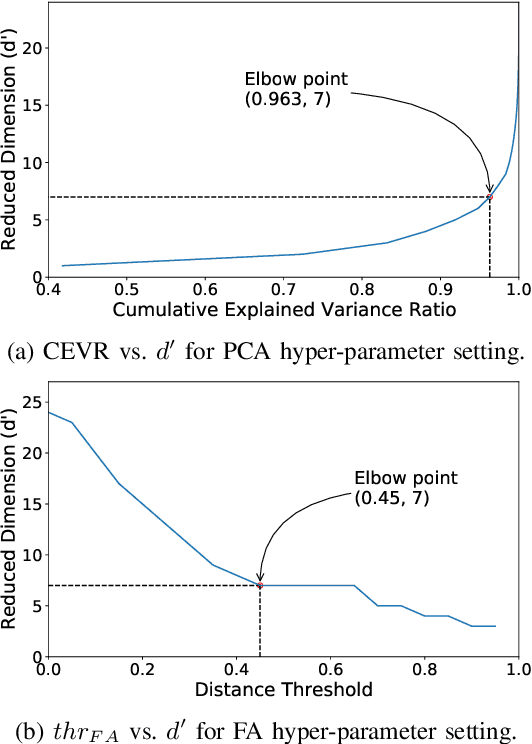
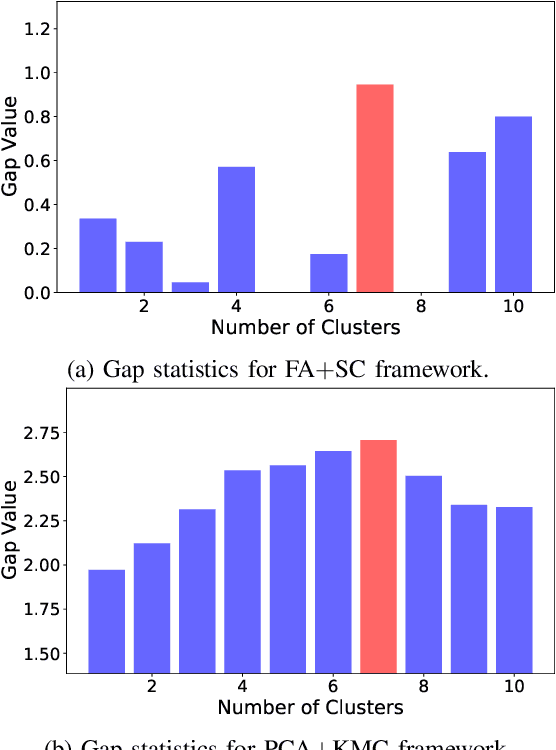
Feb 26, 2021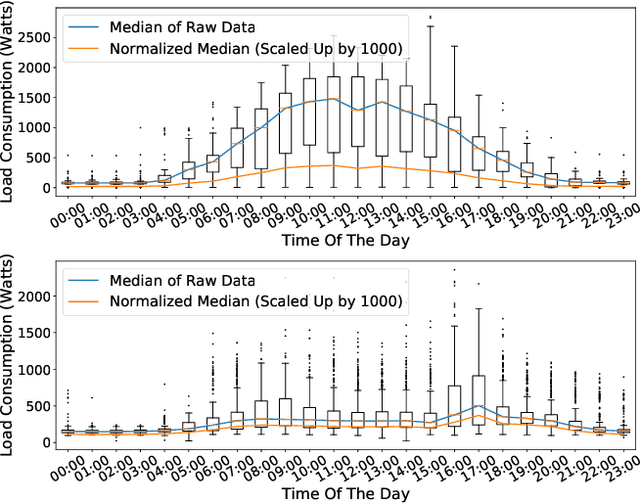
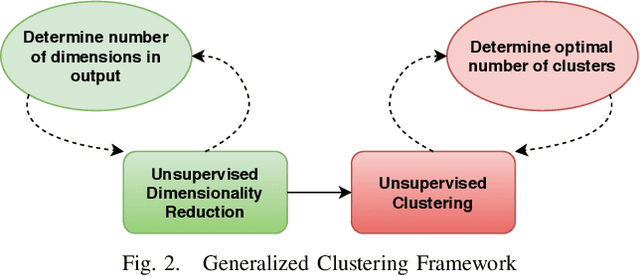
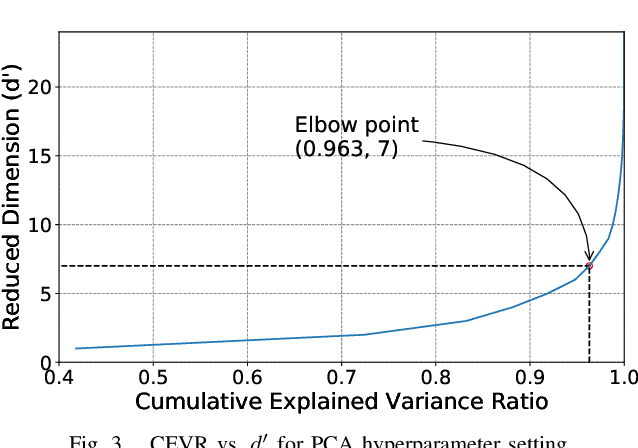

Large-scale deployment of smart meters has made it possible to collect sufficient and high-resolution data of residential electric demand profiles. Clustering analysis of these profiles is important to further analyze and comment on electricity consumption patterns. Although many clustering techniques have been proposed in the literature over the years, it is often noticed that different techniques fit best for different datasets. To identify the most suitable technique, standard clustering validity indices are often used. These indices focus primarily on the intrinsic characteristics of the clustering results. Moreover, different indices often give conflicting recommendations which can only be clarified with heuristics about the dataset and/or the expected cluster structures -- information that is rarely available in practical situations. This paper presents a novel scheme to validate and compare the clustering results objectively. Additionally, the proposed scheme considers all the steps prior to the clustering algorithm, including the pre-processing and dimensionality reduction steps, in order to provide recommendations over the complete framework. Accordingly, the proposed strategy is shown to provide better, unbiased, and uniform recommendations as compared to the standard Clustering Validity Indices.
Automatic Identification of Closely-related Indian Languages: Resources and Experiments
Mar 26, 2018
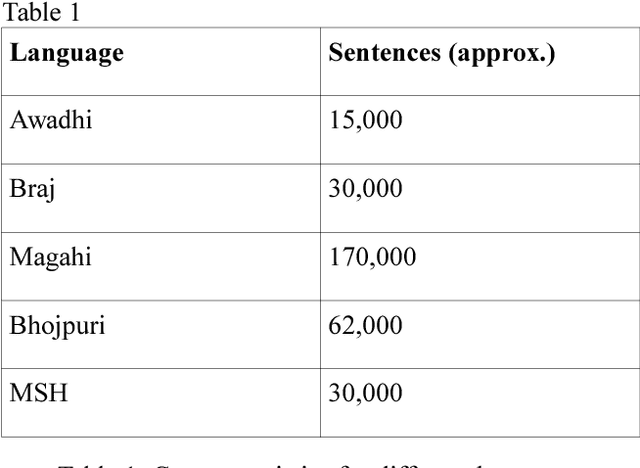
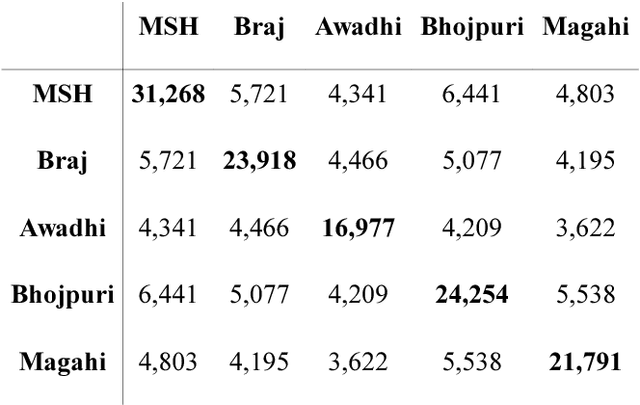
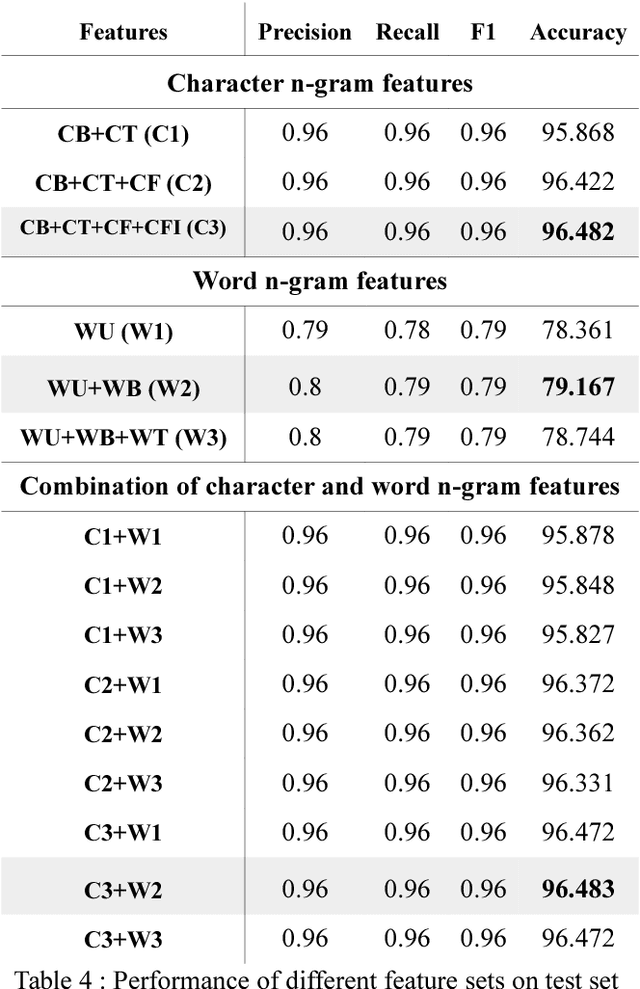
In this paper, we discuss an attempt to develop an automatic language identification system for 5 closely-related Indo-Aryan languages of India, Awadhi, Bhojpuri, Braj, Hindi and Magahi. We have compiled a comparable corpora of varying length for these languages from various resources. We discuss the method of creation of these corpora in detail. Using these corpora, a language identification system was developed, which currently gives state of the art accuracy of 96.48\%. We also used these corpora to study the similarity between the 5 languages at the lexical level, which is the first data-based study of the extent of closeness of these languages.