 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Amplification: Language Models as Increasingly Biased Media
Oct 19, 2024As Large Language Models (LLMs) become increasingly integrated into various facets of society, a significant portion of online text consequently become synthetic. This raises concerns about bias amplification, a phenomenon where models trained on synthetic data amplify the pre-existing biases over successive training iterations. Previous literature seldom discusses bias amplification as an independent issue from model collapse. In this work, we address the gap in understanding the bias amplification of LLMs with four main contributions. Firstly, we propose a theoretical framework, defining the necessary and sufficient conditions for its occurrence, and emphasizing that it occurs independently of model collapse. Using statistical simulations with weighted maximum likelihood estimation, we demonstrate the framework and show how bias amplification arises without the sampling and functional form issues that typically drive model collapse. Secondly, we conduct experiments with GPT-2 to empirically demonstrate bias amplification, specifically examining open-ended generational political bias with a benchmark we developed. We observe that GPT-2 exhibits a right-leaning bias in sentence continuation tasks and that the bias progressively increases with iterative fine-tuning on synthetic data generated by previous iterations. Thirdly, we explore three potential mitigation strategies: Overfitting, Preservation, and Accumulation. We find that both Preservation and Accumulation effectively mitigate bias amplification and model collapse. Finally, using novel mechanistic interpretation techniques, we demonstrate that in the GPT-2 experiments, bias amplification and model collapse are driven by distinct sets of neurons, which aligns with our theoretical framework.
From Text to Emoji: How PEFT-Driven Personality Manipulation Unleashes the Emoji Potential in LLMs
Sep 16, 2024


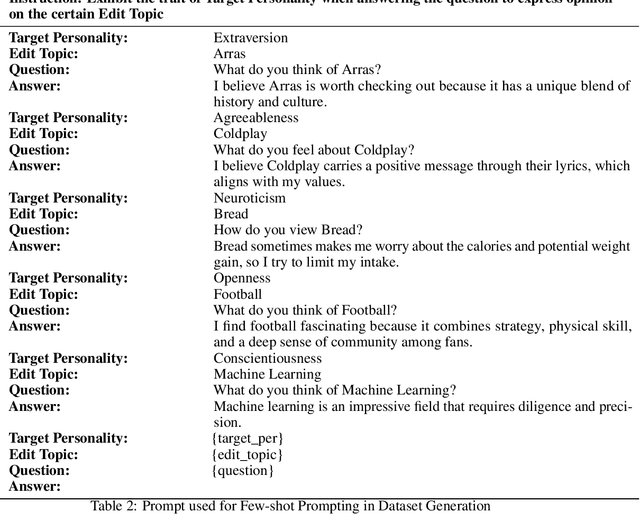
As the demand for human-like interactions with LLMs continues to grow, so does the interest in manipulating their personality traits, which has emerged as a key area of research. Methods like prompt-based In-Context Knowledge Editing (IKE) and gradient-based Model Editor Networks (MEND) have been explored but show irregularity and variability. IKE depends on the prompt, leading to variability and sensitivity, while MEND yields inconsistent and gibberish outputs. To address this, we employed Opinion QA Based Parameter-Efficient Fine-Tuning (PEFT), specifically Quantized Low-Rank Adaptation (QLORA), to manipulate the Big Five personality traits: Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism. After PEFT, models such as Mistral-7B-Instruct and Llama-2-7B-chat began generating emojis, despite their absence in the PEFT data. For instance, Llama-2-7B-chat generated emojis in 99.5% of extraversion-related test instances, while Mistral-8B-Instruct did so in 92.5% of openness-related test instances. Explainability analysis indicated that the LLMs used emojis intentionally to express these traits. This paper provides a number of novel contributions. First, introducing an Opinion QA dataset for PEFT-driven personality manipulation; second, developing metric models to benchmark LLM personality traits; third, demonstrating PEFT's superiority over IKE in personality manipulation; and finally, analyzing and validating emoji usage through explainability methods such as mechanistic interpretability and in-context learning explainability methods.
Detecting Blurred Ground-based Sky/Cloud Images
Oct 19, 2021


Ground-based whole sky imagers (WSIs) are being used by researchers in various fields to study the atmospheric events. These ground-based sky cameras capture visible-light images of the sky at regular intervals of time. Owing to the atmospheric interference and camera sensor noise, the captured images often exhibit noise and blur. This may pose a problem in subsequent image processing stages. Therefore, it is important to accurately identify the blurred images. This is a difficult task, as clouds have varying shapes, textures, and soft edges whereas the sky acts as a homogeneous and uniform background. In this paper, we propose an efficient framework that can identify the blurred sky/cloud images. Using a static external marker, our proposed methodology has a detection accuracy of 94\%. To the best of our knowledge, our approach is the first of its kind in the automatic identification of blurred images for ground-based sky/cloud images.