 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Text to Emoji: How PEFT-Driven Personality Manipulation Unleashes the Emoji Potential in LLMs
Sep 16, 2024


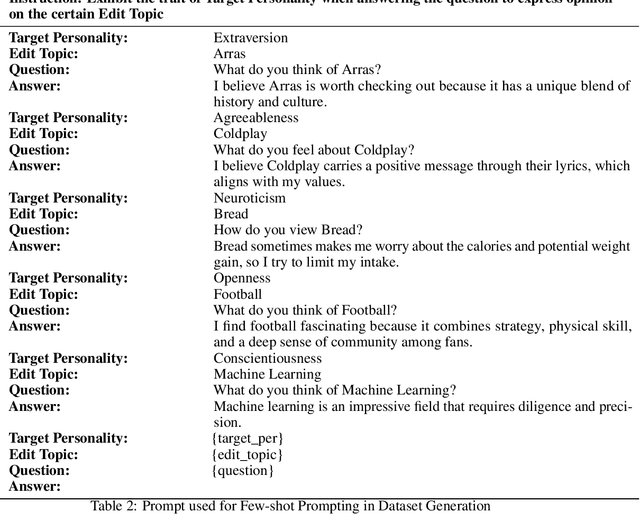
As the demand for human-like interactions with LLMs continues to grow, so does the interest in manipulating their personality traits, which has emerged as a key area of research. Methods like prompt-based In-Context Knowledge Editing (IKE) and gradient-based Model Editor Networks (MEND) have been explored but show irregularity and variability. IKE depends on the prompt, leading to variability and sensitivity, while MEND yields inconsistent and gibberish outputs. To address this, we employed Opinion QA Based Parameter-Efficient Fine-Tuning (PEFT), specifically Quantized Low-Rank Adaptation (QLORA), to manipulate the Big Five personality traits: Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism. After PEFT, models such as Mistral-7B-Instruct and Llama-2-7B-chat began generating emojis, despite their absence in the PEFT data. For instance, Llama-2-7B-chat generated emojis in 99.5% of extraversion-related test instances, while Mistral-8B-Instruct did so in 92.5% of openness-related test instances. Explainability analysis indicated that the LLMs used emojis intentionally to express these traits. This paper provides a number of novel contributions. First, introducing an Opinion QA dataset for PEFT-driven personality manipulation; second, developing metric models to benchmark LLM personality traits; third, demonstrating PEFT's superiority over IKE in personality manipulation; and finally, analyzing and validating emoji usage through explainability methods such as mechanistic interpretability and in-context learning explainability methods.
Eliciting Personality Traits in Large Language Models
Feb 15, 2024



Large Language Models (LLMs) are increasingly being utilized by both candidates and employers in the recruitment context. However, with this comes numerous ethical concerns, particularly related to the lack of transparency in these "black-box" models. Although previous studies have sought to increase the transparency of these models by investigating the personality traits of LLMs, many of the previous studies have provided them with personality assessments to complete. On the other hand, this study seeks to obtain a better understanding of such models by examining their output variations based on different input prompts. Specifically, we use a novel elicitation approach using prompts derived from common interview questions, as well as prompts designed to elicit particular Big Five personality traits to examine whether the models were susceptible to trait-activation like humans are, to measure their personality based on the language used in their outputs. To do so, we repeatedly prompted multiple LMs with different parameter sizes, including Llama-2, Falcon, Mistral, Bloom, GPT, OPT, and XLNet (base and fine tuned versions) and examined their personality using classifiers trained on the myPersonality dataset. Our results reveal that, generally, all LLMs demonstrate high openness and low extraversion. However, whereas LMs with fewer parameters exhibit similar behaviour in personality traits, newer and LMs with more parameters exhibit a broader range of personality traits, with increased agreeableness, emotional stability, and openness. Furthermore, a greater number of parameters is positively associated with openness and conscientiousness. Moreover, fine-tuned models exhibit minor modulations in their personality traits, contingent on the dataset. Implications and directions for future research are discussed.
Local Law 144: A Critical Analysis of Regression Metrics
Feb 08, 2023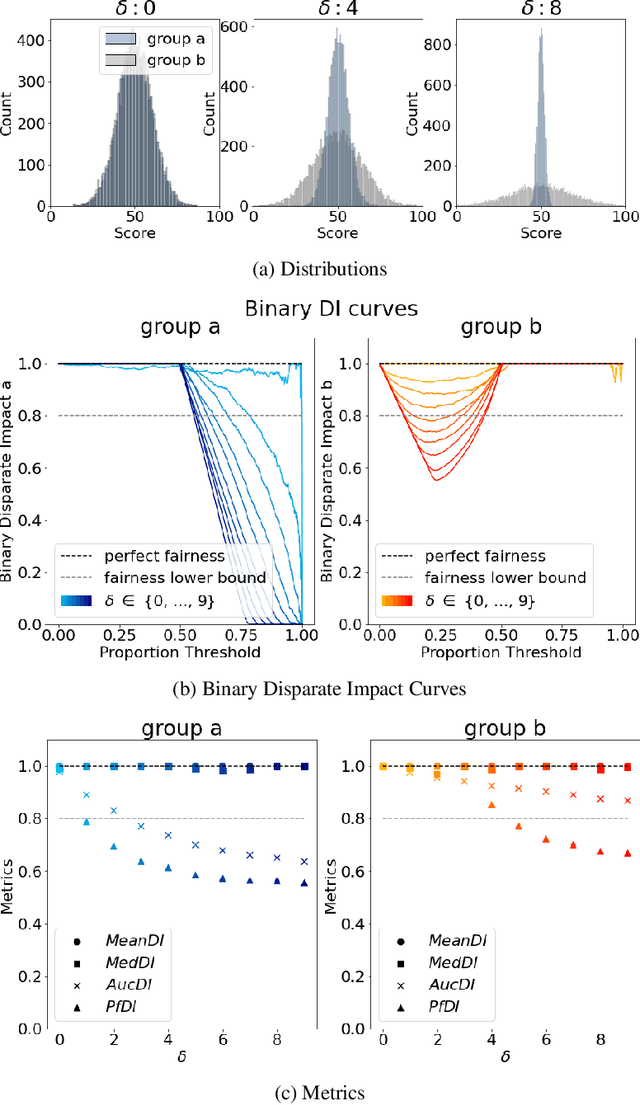
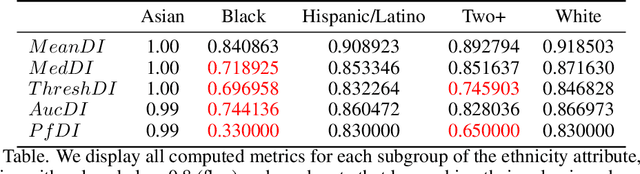
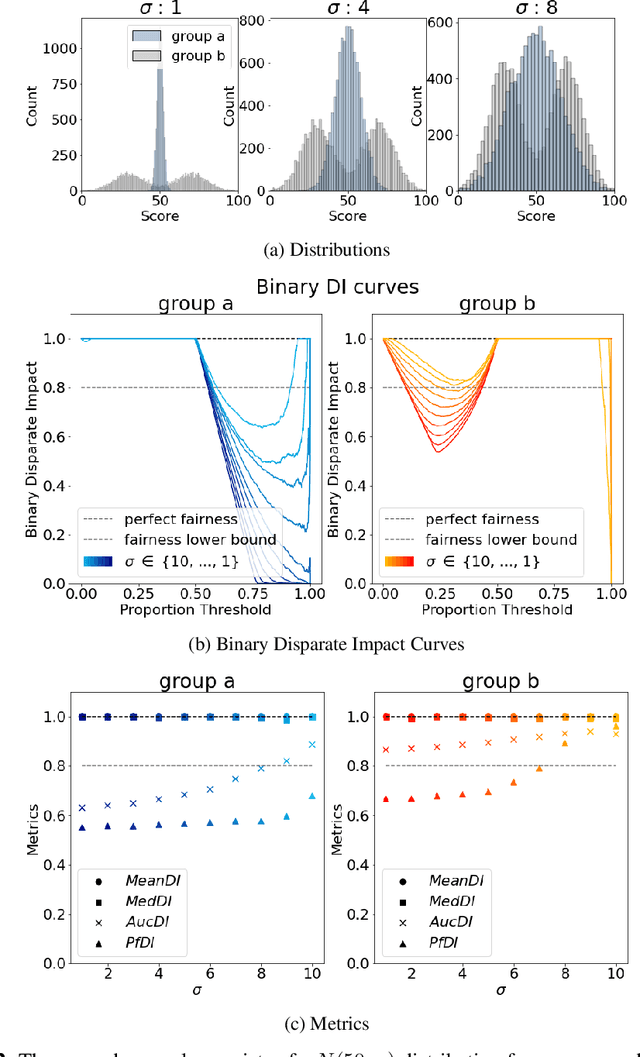
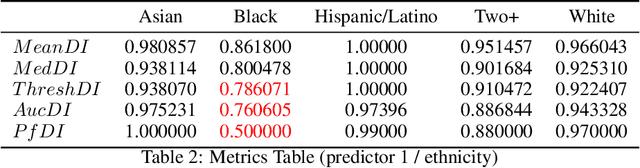
The use of automated decision tools in recruitment has received an increasing amount of attention. In November 2021, the New York City Council passed a legislation (Local Law 144) that mandates bias audits of Automated Employment Decision Tools. From 15th April 2023, companies that use automated tools for hiring or promoting employees are required to have these systems audited by an independent entity. Auditors are asked to compute bias metrics that compare outcomes for different groups, based on sex/gender and race/ethnicity categories at a minimum. Local Law 144 proposes novel bias metrics for regression tasks (scenarios where the automated system scores candidates with a continuous range of values). A previous version of the legislation proposed a bias metric that compared the mean scores of different groups. The new revised bias metric compares the proportion of candidates in each group that falls above the median. In this paper, we argue that both metrics fail to capture distributional differences over the whole domain, and therefore cannot reliably detect bias. We first introduce two metrics, as possible alternatives to the legislation metrics. We then compare these metrics over a range of theoretical examples, for which the legislation proposed metrics seem to underestimate bias. Finally, we study real data and show that the legislation metrics can similarly fail in a real-world recruitment application.