 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntersectional Fairness: A Fractal Approach
Feb 24, 2023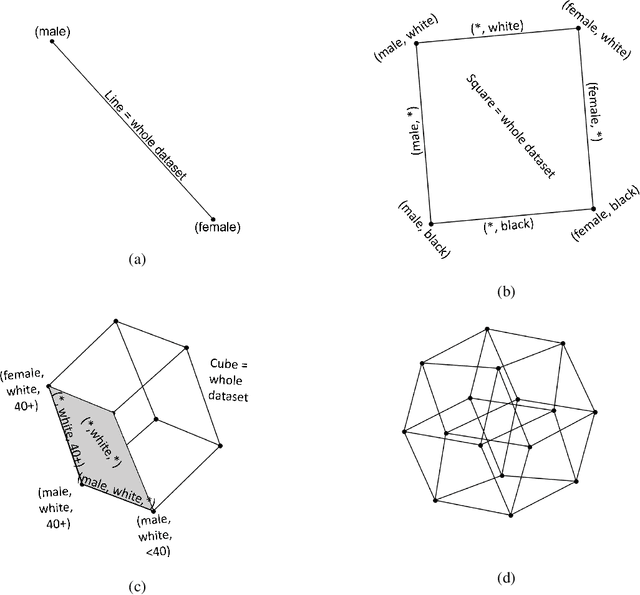

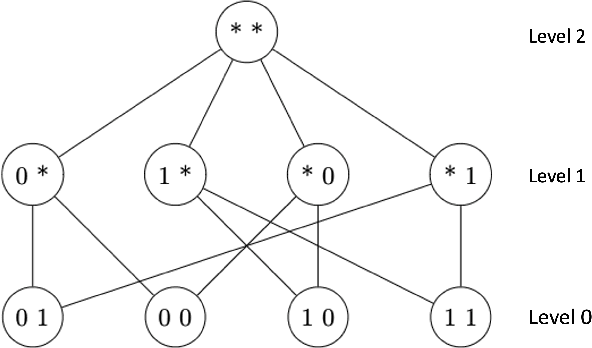
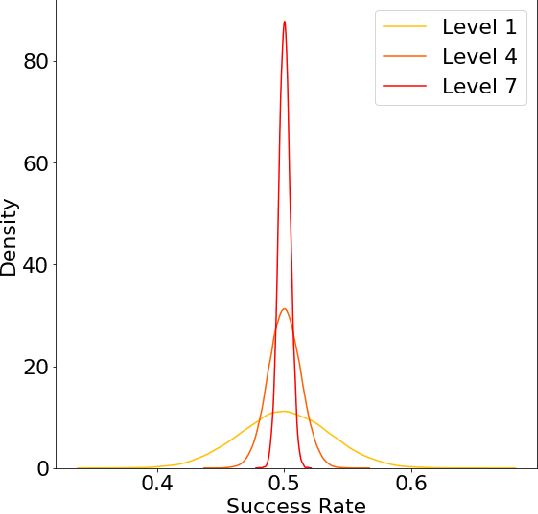
The issue of fairness in AI has received an increasing amount of attention in recent years. The problem can be approached by looking at different protected attributes (e.g., ethnicity, gender, etc) independently, but fairness for individual protected attributes does not imply intersectional fairness. In this work, we frame the problem of intersectional fairness within a geometrical setting. We project our data onto a hypercube, and split the analysis of fairness by levels, where each level encodes the number of protected attributes we are intersecting over. We prove mathematically that, while fairness does not propagate "down" the levels, it does propagate "up" the levels. This means that ensuring fairness for all subgroups at the lowest intersectional level (e.g., black women, white women, black men and white men), will necessarily result in fairness for all the above levels, including each of the protected attributes (e.g., ethnicity and gender) taken independently. We also derive a formula describing the variance of the set of estimated success rates on each level, under the assumption of perfect fairness. Using this theoretical finding as a benchmark, we define a family of metrics which capture overall intersectional bias. Finally, we propose that fairness can be metaphorically thought of as a "fractal" problem. In fractals, patterns at the smallest scale repeat at a larger scale. We see from this example that tackling the problem at the lowest possible level, in a bottom-up manner, leads to the natural emergence of fair AI. We suggest that trustworthiness is necessarily an emergent, fractal and relational property of the AI system.
Uncovering Bias in Face Generation Models
Feb 22, 2023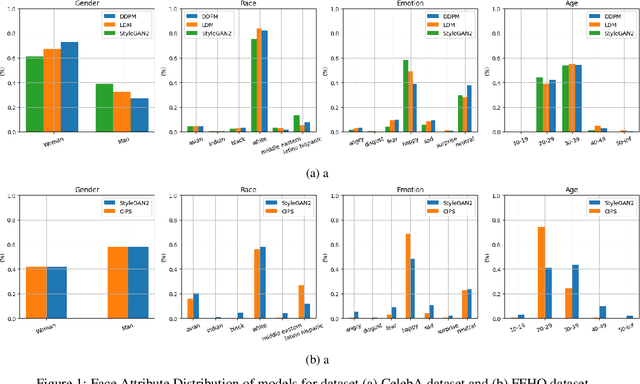
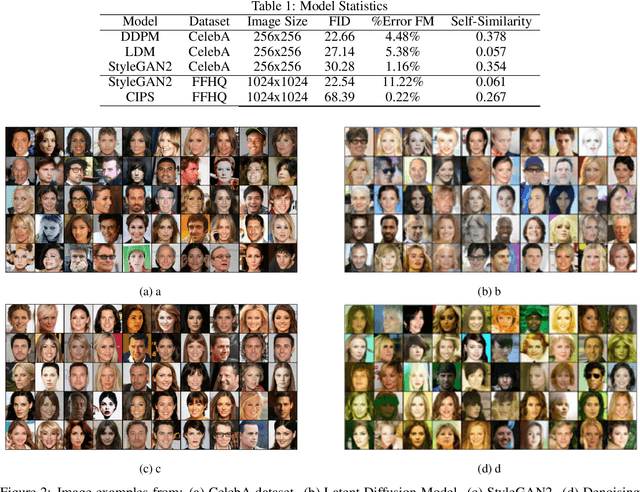

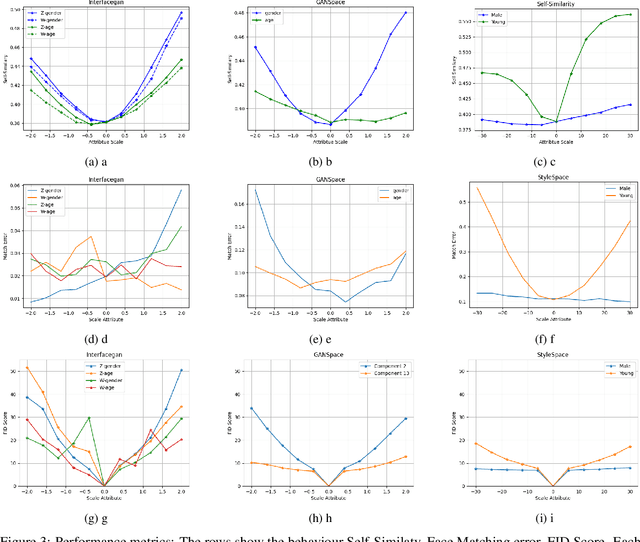
Recent advancements in GANs and diffusion models have enabled the creation of high-resolution, hyper-realistic images. However, these models may misrepresent certain social groups and present bias. Understanding bias in these models remains an important research question, especially for tasks that support critical decision-making and could affect minorities. The contribution of this work is a novel analysis covering architectures and embedding spaces for fine-grained understanding of bias over three approaches: generators, attribute modifier, and post-processing bias mitigators. This work shows that generators suffer from bias across all social groups with attribute preferences such as between 75%-85% for whiteness and 60%-80% for the female gender (for all trained CelebA models) and low probabilities of generating children and older men. Modifier and mitigators work as post-processor and change the generator performance. For instance, attribute channel perturbation strategies modify the embedding spaces. We quantify the influence of this change on group fairness by measuring the impact on image quality and group features. Specifically, we use the Fr\'echet Inception Distance (FID), the Face Matching Error and the Self-Similarity score. For Interfacegan, we analyze one and two attribute channel perturbations and examine the effect on the fairness distribution and the quality of the image. Finally, we analyzed the post-processing bias mitigators, which are the fastest and most computationally efficient way to mitigate bias. We find that these mitigation techniques show similar results on KL divergence and FID score, however, self-similarity scores show a different feature concentration on the new groups of the data distribution. The weaknesses and ongoing challenges described in this work must be considered in the pursuit of creating fair and unbiased face generation models.
Local Law 144: A Critical Analysis of Regression Metrics
Feb 08, 2023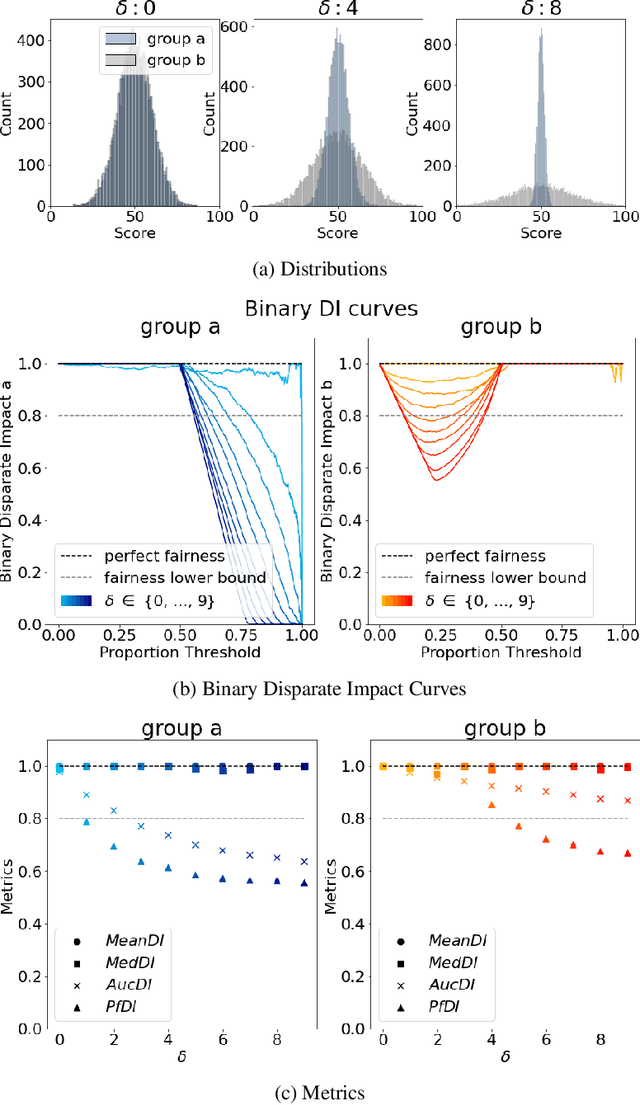
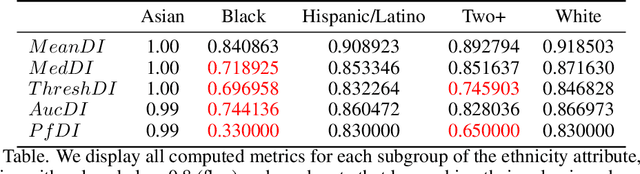
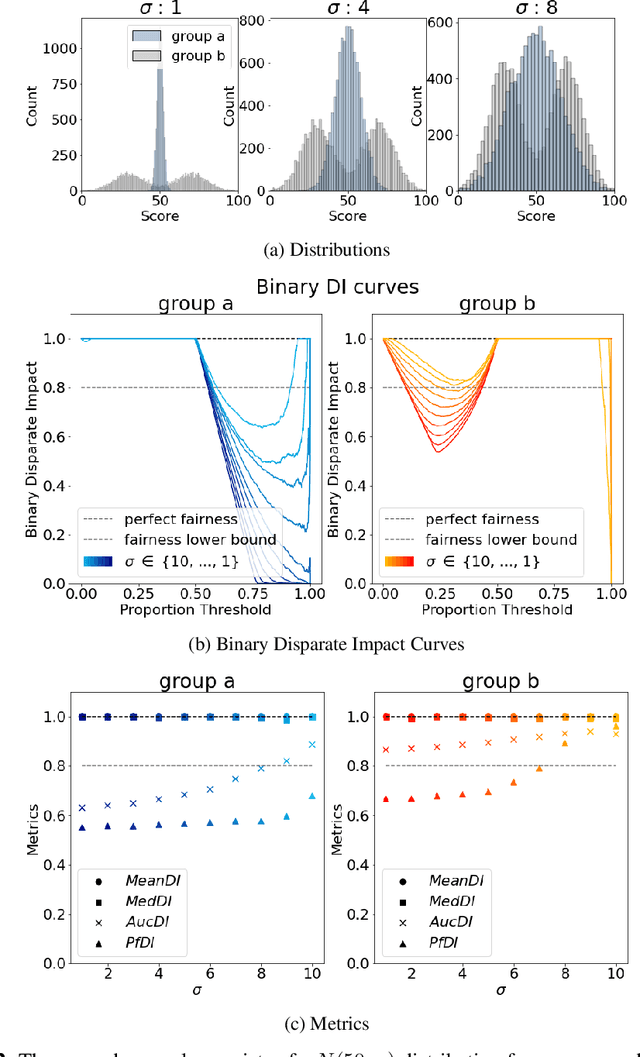
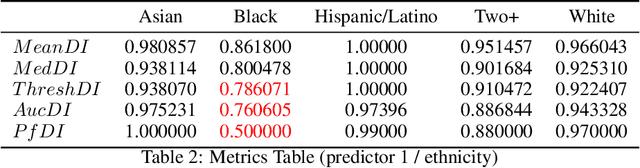
The use of automated decision tools in recruitment has received an increasing amount of attention. In November 2021, the New York City Council passed a legislation (Local Law 144) that mandates bias audits of Automated Employment Decision Tools. From 15th April 2023, companies that use automated tools for hiring or promoting employees are required to have these systems audited by an independent entity. Auditors are asked to compute bias metrics that compare outcomes for different groups, based on sex/gender and race/ethnicity categories at a minimum. Local Law 144 proposes novel bias metrics for regression tasks (scenarios where the automated system scores candidates with a continuous range of values). A previous version of the legislation proposed a bias metric that compared the mean scores of different groups. The new revised bias metric compares the proportion of candidates in each group that falls above the median. In this paper, we argue that both metrics fail to capture distributional differences over the whole domain, and therefore cannot reliably detect bias. We first introduce two metrics, as possible alternatives to the legislation metrics. We then compare these metrics over a range of theoretical examples, for which the legislation proposed metrics seem to underestimate bias. Finally, we study real data and show that the legislation metrics can similarly fail in a real-world recruitment application.