 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Bias in Face Generation Models
Paper and Code
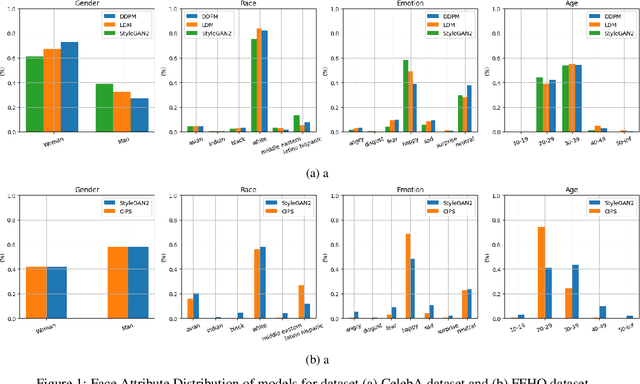
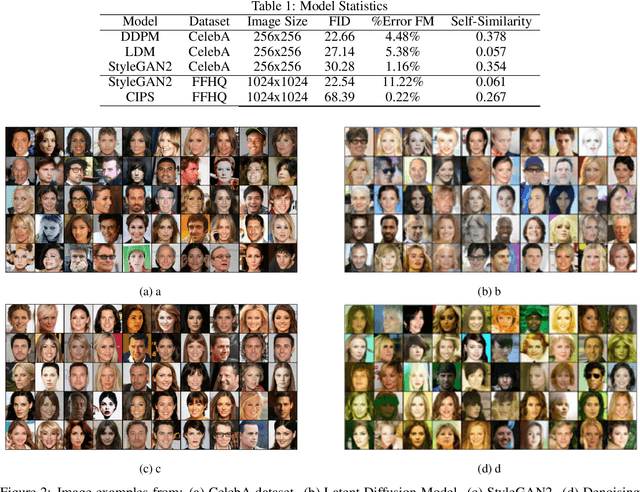

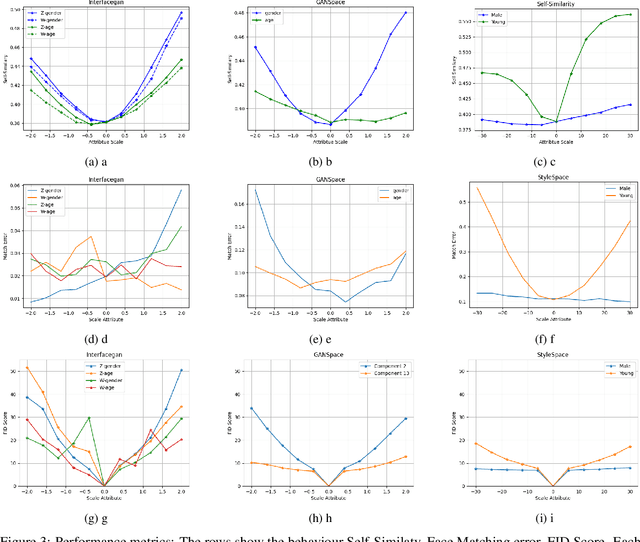
Recent advancements in GANs and diffusion models have enabled the creation of high-resolution, hyper-realistic images. However, these models may misrepresent certain social groups and present bias. Understanding bias in these models remains an important research question, especially for tasks that support critical decision-making and could affect minorities. The contribution of this work is a novel analysis covering architectures and embedding spaces for fine-grained understanding of bias over three approaches: generators, attribute modifier, and post-processing bias mitigators. This work shows that generators suffer from bias across all social groups with attribute preferences such as between 75%-85% for whiteness and 60%-80% for the female gender (for all trained CelebA models) and low probabilities of generating children and older men. Modifier and mitigators work as post-processor and change the generator performance. For instance, attribute channel perturbation strategies modify the embedding spaces. We quantify the influence of this change on group fairness by measuring the impact on image quality and group features. Specifically, we use the Fr\'echet Inception Distance (FID), the Face Matching Error and the Self-Similarity score. For Interfacegan, we analyze one and two attribute channel perturbations and examine the effect on the fairness distribution and the quality of the image. Finally, we analyzed the post-processing bias mitigators, which are the fastest and most computationally efficient way to mitigate bias. We find that these mitigation techniques show similar results on KL divergence and FID score, however, self-similarity scores show a different feature concentration on the new groups of the data distribution. The weaknesses and ongoing challenges described in this work must be considered in the pursuit of creating fair and unbiased face generation models.