 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibVulnWatch: A Deep Assessment Agent System and Leaderboard for Uncovering Hidden Vulnerabilities in Open-Source AI Libraries
May 13, 2025



Open-source AI libraries are foundational to modern AI systems but pose significant, underexamined risks across security, licensing, maintenance, supply chain integrity, and regulatory compliance. We present LibVulnWatch, a graph-based agentic assessment framework that performs deep, source-grounded evaluations of these libraries. Built on LangGraph, the system coordinates a directed acyclic graph of specialized agents to extract, verify, and quantify risk using evidence from trusted sources such as repositories, documentation, and vulnerability databases. LibVulnWatch generates reproducible, governance-aligned scores across five critical domains, publishing them to a public leaderboard for longitudinal ecosystem monitoring. Applied to 20 widely used libraries, including ML frameworks, LLM inference engines, and agent orchestration tools, our system covers up to 88% of OpenSSF Scorecard checks while uncovering up to 19 additional risks per library. These include critical Remote Code Execution (RCE) vulnerabilities, absent Software Bills of Materials (SBOMs), licensing constraints, undocumented telemetry, and widespread gaps in regulatory documentation and auditability. By translating high-level governance principles into practical, verifiable metrics, LibVulnWatch advances technical AI governance with a scalable, transparent mechanism for continuous supply chain risk assessment and informed library selection.
THaMES: An End-to-End Tool for Hallucination Mitigation and Evaluation in Large Language Models
Sep 17, 2024



Hallucination, the generation of factually incorrect content, is a growing challenge in Large Language Models (LLMs). Existing detection and mitigation methods are often isolated and insufficient for domain-specific needs, lacking a standardized pipeline. This paper introduces THaMES (Tool for Hallucination Mitigations and EvaluationS), an integrated framework and library addressing this gap. THaMES offers an end-to-end solution for evaluating and mitigating hallucinations in LLMs, featuring automated test set generation, multifaceted benchmarking, and adaptable mitigation strategies. It automates test set creation from any corpus, ensuring high data quality, diversity, and cost-efficiency through techniques like batch processing, weighted sampling, and counterfactual validation. THaMES assesses a model's ability to detect and reduce hallucinations across various tasks, including text generation and binary classification, applying optimal mitigation strategies like In-Context Learning (ICL), Retrieval Augmented Generation (RAG), and Parameter-Efficient Fine-tuning (PEFT). Evaluations of state-of-the-art LLMs using a knowledge base of academic papers, political news, and Wikipedia reveal that commercial models like GPT-4o benefit more from RAG than ICL, while open-weight models like Llama-3.1-8B-Instruct and Mistral-Nemo gain more from ICL. Additionally, PEFT significantly enhances the performance of Llama-3.1-8B-Instruct in both evaluation tasks.
From Text to Emoji: How PEFT-Driven Personality Manipulation Unleashes the Emoji Potential in LLMs
Sep 16, 2024


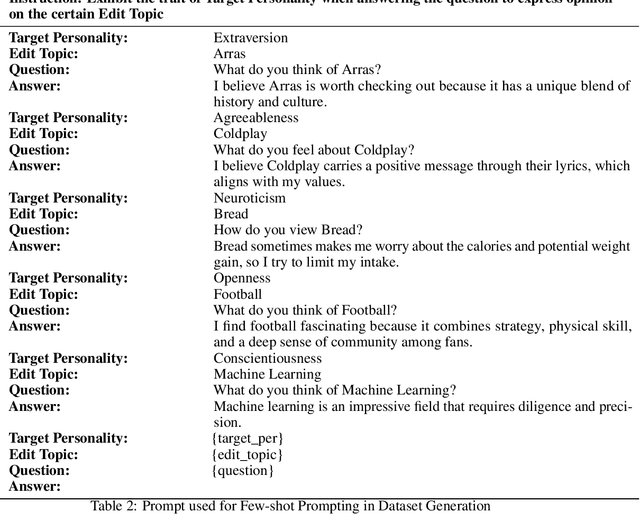
As the demand for human-like interactions with LLMs continues to grow, so does the interest in manipulating their personality traits, which has emerged as a key area of research. Methods like prompt-based In-Context Knowledge Editing (IKE) and gradient-based Model Editor Networks (MEND) have been explored but show irregularity and variability. IKE depends on the prompt, leading to variability and sensitivity, while MEND yields inconsistent and gibberish outputs. To address this, we employed Opinion QA Based Parameter-Efficient Fine-Tuning (PEFT), specifically Quantized Low-Rank Adaptation (QLORA), to manipulate the Big Five personality traits: Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism. After PEFT, models such as Mistral-7B-Instruct and Llama-2-7B-chat began generating emojis, despite their absence in the PEFT data. For instance, Llama-2-7B-chat generated emojis in 99.5% of extraversion-related test instances, while Mistral-8B-Instruct did so in 92.5% of openness-related test instances. Explainability analysis indicated that the LLMs used emojis intentionally to express these traits. This paper provides a number of novel contributions. First, introducing an Opinion QA dataset for PEFT-driven personality manipulation; second, developing metric models to benchmark LLM personality traits; third, demonstrating PEFT's superiority over IKE in personality manipulation; and finally, analyzing and validating emoji usage through explainability methods such as mechanistic interpretability and in-context learning explainability methods.
Eliciting Personality Traits in Large Language Models
Feb 15, 2024



Large Language Models (LLMs) are increasingly being utilized by both candidates and employers in the recruitment context. However, with this comes numerous ethical concerns, particularly related to the lack of transparency in these "black-box" models. Although previous studies have sought to increase the transparency of these models by investigating the personality traits of LLMs, many of the previous studies have provided them with personality assessments to complete. On the other hand, this study seeks to obtain a better understanding of such models by examining their output variations based on different input prompts. Specifically, we use a novel elicitation approach using prompts derived from common interview questions, as well as prompts designed to elicit particular Big Five personality traits to examine whether the models were susceptible to trait-activation like humans are, to measure their personality based on the language used in their outputs. To do so, we repeatedly prompted multiple LMs with different parameter sizes, including Llama-2, Falcon, Mistral, Bloom, GPT, OPT, and XLNet (base and fine tuned versions) and examined their personality using classifiers trained on the myPersonality dataset. Our results reveal that, generally, all LLMs demonstrate high openness and low extraversion. However, whereas LMs with fewer parameters exhibit similar behaviour in personality traits, newer and LMs with more parameters exhibit a broader range of personality traits, with increased agreeableness, emotional stability, and openness. Furthermore, a greater number of parameters is positively associated with openness and conscientiousness. Moreover, fine-tuned models exhibit minor modulations in their personality traits, contingent on the dataset. Implications and directions for future research are discussed.
Local and Global Explainability Metrics for Machine Learning Predictions
Feb 23, 2023

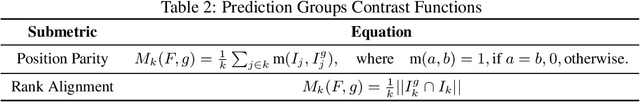

Rapid advancements in artificial intelligence (AI) technology have brought about a plethora of new challenges in terms of governance and regulation. AI systems are being integrated into various industries and sectors, creating a demand from decision-makers to possess a comprehensive and nuanced understanding of the capabilities and limitations of these systems. One critical aspect of this demand is the ability to explain the results of machine learning models, which is crucial to promoting transparency and trust in AI systems, as well as fundamental in helping machine learning models to be trained ethically. In this paper, we present novel quantitative metrics frameworks for interpreting the predictions of classifier and regressor models. The proposed metrics are model agnostic and are defined in order to be able to quantify: i. the interpretability factors based on global and local feature importance distributions; ii. the variability of feature impact on the model output; and iii. the complexity of feature interactions within model decisions. We employ publicly available datasets to apply our proposed metrics to various machine learning models focused on predicting customers' credit risk (classification task) and real estate price valuation (regression task). The results expose how these metrics can provide a more comprehensive understanding of model predictions and facilitate better communication between decision-makers and stakeholders, thereby increasing the overall transparency and accountability of AI systems.