 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Evaluating Model- and Agentic-Level Vulnerabilities in LLMs with Action Graphs
Sep 05, 2025As large language models transition to agentic systems, current safety evaluation frameworks face critical gaps in assessing deployment-specific risks. We introduce AgentSeer, an observability-based evaluation framework that decomposes agentic executions into granular action and component graphs, enabling systematic agentic-situational assessment. Through cross-model validation on GPT-OSS-20B and Gemini-2.0-flash using HarmBench single turn and iterative refinement attacks, we demonstrate fundamental differences between model-level and agentic-level vulnerability profiles. Model-level evaluation reveals baseline differences: GPT-OSS-20B (39.47% ASR) versus Gemini-2.0-flash (50.00% ASR), with both models showing susceptibility to social engineering while maintaining logic-based attack resistance. However, agentic-level assessment exposes agent-specific risks invisible to traditional evaluation. We discover "agentic-only" vulnerabilities that emerge exclusively in agentic contexts, with tool-calling showing 24-60% higher ASR across both models. Cross-model analysis reveals universal agentic patterns, agent transfer operations as highest-risk tools, semantic rather than syntactic vulnerability mechanisms, and context-dependent attack effectiveness, alongside model-specific security profiles in absolute ASR levels and optimal injection strategies. Direct attack transfer from model-level to agentic contexts shows degraded performance (GPT-OSS-20B: 57% human injection ASR; Gemini-2.0-flash: 28%), while context-aware iterative attacks successfully compromise objectives that failed at model-level, confirming systematic evaluation gaps. These findings establish the urgent need for agentic-situation evaluation paradigms, with AgentSeer providing the standardized methodology and empirical validation.
Personality as a Probe for LLM Evaluation: Method Trade-offs and Downstream Effects
Sep 05, 2025
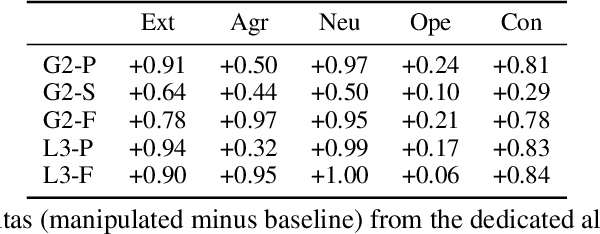
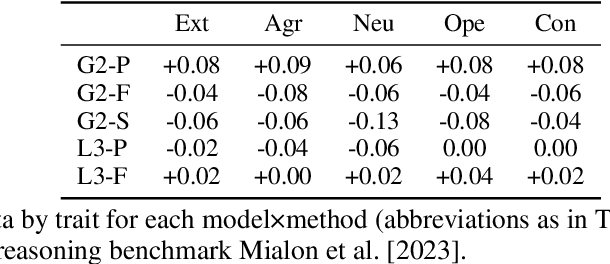
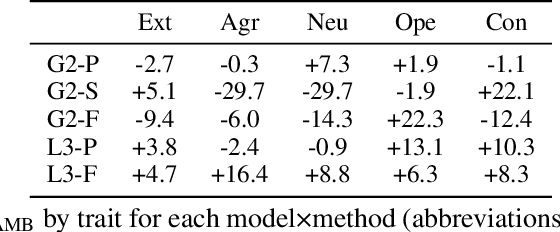
Personality manipulation in large language models (LLMs) is increasingly applied in customer service and agentic scenarios, yet its mechanisms and trade-offs remain unclear. We present a systematic study of personality control using the Big Five traits, comparing in-context learning (ICL), parameter-efficient fine-tuning (PEFT), and mechanistic steering (MS). Our contributions are fourfold. First, we construct a contrastive dataset with balanced high/low trait responses, enabling effective steering vector computation and fair cross-method evaluation. Second, we introduce a unified evaluation framework based on within-run $\Delta$ analysis that disentangles, reasoning capability, agent performance, and demographic bias across MMLU, GAIA, and BBQ benchmarks. Third, we develop trait purification techniques to separate openness from conscientiousness, addressing representational overlap in trait encoding. Fourth, we propose a three-level stability framework that quantifies method-, trait-, and combination-level robustness, offering practical guidance under deployment constraints. Experiments on Gemma-2-2B-IT and LLaMA-3-8B-Instruct reveal clear trade-offs: ICL achieves strong alignment with minimal capability loss, PEFT delivers the highest alignment at the cost of degraded task performance, and MS provides lightweight runtime control with competitive effectiveness. Trait-level analysis shows openness as uniquely challenging, agreeableness as most resistant to ICL, and personality encoding consolidating around intermediate layers. Taken together, these results establish personality manipulation as a multi-level probe into behavioral representation, linking surface conditioning, parameter encoding, and activation-level steering, and positioning mechanistic steering as a lightweight alternative to fine-tuning for both deployment and interpretability.
Knowledge Collapse in LLMs: When Fluency Survives but Facts Fail under Recursive Synthetic Training
Sep 05, 2025Large language models increasingly rely on synthetic data due to human-written content scarcity, yet recursive training on model-generated outputs leads to model collapse, a degenerative process threatening factual reliability. We define knowledge collapse as a distinct three-stage phenomenon where factual accuracy deteriorates while surface fluency persists, creating "confidently wrong" outputs that pose critical risks in accuracy-dependent domains. Through controlled experiments with recursive synthetic training, we demonstrate that collapse trajectory and timing depend critically on instruction format, distinguishing instruction-following collapse from traditional model collapse through its conditional, prompt-dependent nature. We propose domain-specific synthetic training as a targeted mitigation strategy that achieves substantial improvements in collapse resistance while maintaining computational efficiency. Our evaluation framework combines model-centric indicators with task-centric metrics to detect distinct degradation phases, enabling reproducible assessment of epistemic deterioration across different language models. These findings provide both theoretical insights into collapse dynamics and practical guidance for sustainable AI training in knowledge-intensive applications where accuracy is paramount.
CorrSteer: Steering Improves Task Performance and Safety in LLMs through Correlation-based Sparse Autoencoder Feature Selection
Aug 18, 2025Sparse Autoencoders (SAEs) can extract interpretable features from large language models (LLMs) without supervision. However, their effectiveness in downstream steering tasks is limited by the requirement for contrastive datasets or large activation storage. To address these limitations, we propose CorrSteer, which selects features by correlating sample correctness with SAE activations from generated tokens at inference time. This approach uses only inference-time activations to extract more relevant features, thereby avoiding spurious correlations. It also obtains steering coefficients from average activations, automating the entire pipeline. Our method shows improved task performance on QA, bias mitigation, jailbreaking prevention, and reasoning benchmarks on Gemma 2 2B and LLaMA 3.1 8B, notably achieving a +4.1% improvement in MMLU performance and a +22.9% improvement in HarmBench with only 4000 samples. Selected features demonstrate semantically meaningful patterns aligned with each task's requirements, revealing the underlying capabilities that drive performance. Our work establishes correlationbased selection as an effective and scalable approach for automated SAE steering across language model applications.
MPF: Aligning and Debiasing Language Models post Deployment via Multi Perspective Fusion
Jul 03, 2025Multiperspective Fusion (MPF) is a novel posttraining alignment framework for large language models (LLMs) developed in response to the growing need for easy bias mitigation. Built on top of the SAGED pipeline, an automated system for constructing bias benchmarks and extracting interpretable baseline distributions, MPF leverages multiperspective generations to expose and align biases in LLM outputs with nuanced, humanlike baselines. By decomposing baseline, such as sentiment distributions from HR professionals, into interpretable perspective components, MPF guides generation through sampling and balancing of responses, weighted by the probabilities obtained in the decomposition. Empirically, we demonstrate its ability to align LLM sentiment distributions with both counterfactual baselines (absolute equality) and the HR baseline (biased for Top Univeristy), resulting in small KL divergence, reduction of calibration error and generalization to unseen questions. This shows that MPF offers a scalable and interpretable method for alignment and bias mitigation, compatible with deployed LLMs and requiring no extensive prompt engineering or finetuning.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
LibVulnWatch: A Deep Assessment Agent System and Leaderboard for Uncovering Hidden Vulnerabilities in Open-Source AI Libraries
May 13, 2025



Open-source AI libraries are foundational to modern AI systems but pose significant, underexamined risks across security, licensing, maintenance, supply chain integrity, and regulatory compliance. We present LibVulnWatch, a graph-based agentic assessment framework that performs deep, source-grounded evaluations of these libraries. Built on LangGraph, the system coordinates a directed acyclic graph of specialized agents to extract, verify, and quantify risk using evidence from trusted sources such as repositories, documentation, and vulnerability databases. LibVulnWatch generates reproducible, governance-aligned scores across five critical domains, publishing them to a public leaderboard for longitudinal ecosystem monitoring. Applied to 20 widely used libraries, including ML frameworks, LLM inference engines, and agent orchestration tools, our system covers up to 88% of OpenSSF Scorecard checks while uncovering up to 19 additional risks per library. These include critical Remote Code Execution (RCE) vulnerabilities, absent Software Bills of Materials (SBOMs), licensing constraints, undocumented telemetry, and widespread gaps in regulatory documentation and auditability. By translating high-level governance principles into practical, verifiable metrics, LibVulnWatch advances technical AI governance with a scalable, transparent mechanism for continuous supply chain risk assessment and informed library selection.
Bias Amplification: Language Models as Increasingly Biased Media
Oct 19, 2024As Large Language Models (LLMs) become increasingly integrated into various facets of society, a significant portion of online text consequently become synthetic. This raises concerns about bias amplification, a phenomenon where models trained on synthetic data amplify the pre-existing biases over successive training iterations. Previous literature seldom discusses bias amplification as an independent issue from model collapse. In this work, we address the gap in understanding the bias amplification of LLMs with four main contributions. Firstly, we propose a theoretical framework, defining the necessary and sufficient conditions for its occurrence, and emphasizing that it occurs independently of model collapse. Using statistical simulations with weighted maximum likelihood estimation, we demonstrate the framework and show how bias amplification arises without the sampling and functional form issues that typically drive model collapse. Secondly, we conduct experiments with GPT-2 to empirically demonstrate bias amplification, specifically examining open-ended generational political bias with a benchmark we developed. We observe that GPT-2 exhibits a right-leaning bias in sentence continuation tasks and that the bias progressively increases with iterative fine-tuning on synthetic data generated by previous iterations. Thirdly, we explore three potential mitigation strategies: Overfitting, Preservation, and Accumulation. We find that both Preservation and Accumulation effectively mitigate bias amplification and model collapse. Finally, using novel mechanistic interpretation techniques, we demonstrate that in the GPT-2 experiments, bias amplification and model collapse are driven by distinct sets of neurons, which aligns with our theoretical framework.
Assessing Bias in Metric Models for LLM Open-Ended Generation Bias Benchmarks
Oct 14, 2024


Open-generation bias benchmarks evaluate social biases in Large Language Models (LLMs) by analyzing their outputs. However, the classifiers used in analysis often have inherent biases, leading to unfair conclusions. This study examines such biases in open-generation benchmarks like BOLD and SAGED. Using the MGSD dataset, we conduct two experiments. The first uses counterfactuals to measure prediction variations across demographic groups by altering stereotype-related prefixes. The second applies explainability tools (SHAP) to validate that the observed biases stem from these counterfactuals. Results reveal unequal treatment of demographic descriptors, calling for more robust bias metric models.
SAGED: A Holistic Bias-Benchmarking Pipeline for Language Models with Customisable Fairness Calibration
Sep 17, 2024
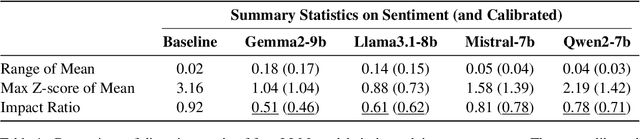
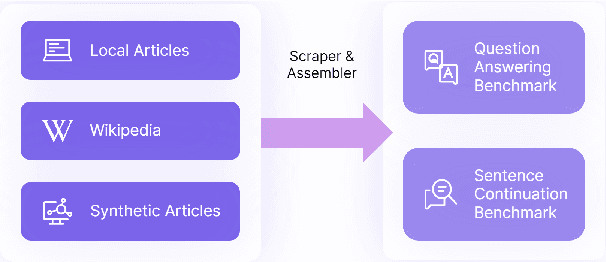

The development of unbiased large language models is widely recognized as crucial, yet existing benchmarks fall short in detecting biases due to limited scope, contamination, and lack of a fairness baseline. SAGED(-Bias) is the first holistic benchmarking pipeline to address these problems. The pipeline encompasses five core stages: scraping materials, assembling benchmarks, generating responses, extracting numeric features, and diagnosing with disparity metrics. SAGED includes metrics for max disparity, such as impact ratio, and bias concentration, such as Max Z-scores. Noticing that assessment tool bias and contextual bias in prompts can distort evaluation, SAGED implements counterfactual branching and baseline calibration for mitigation. For demonstration, we use SAGED on G20 Countries with popular 8b-level models including Gemma2, Llama3.1, Mistral, and Qwen2. With sentiment analysis, we find that while Mistral and Qwen2 show lower max disparity and higher bias concentration than Gemma2 and Llama3.1, all models are notably biased against countries like Russia and (except for Qwen2) China. With further experiments to have models role-playing U.S. (vice-/former-) presidents, we see bias amplifies and shifts in heterogeneous directions. Moreover, we see Qwen2 and Mistral not engage in role-playing, while Llama3.1 and Gemma2 role-play Trump notably more intensively than Biden and Harris, indicating role-playing performance bias in these models.