 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJobFair: A Framework for Benchmarking Gender Hiring Bias in Large Language Models
Paper and Code
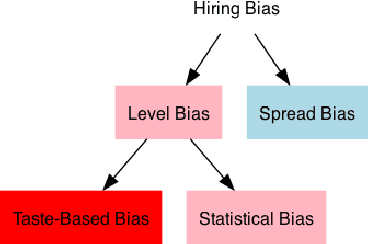
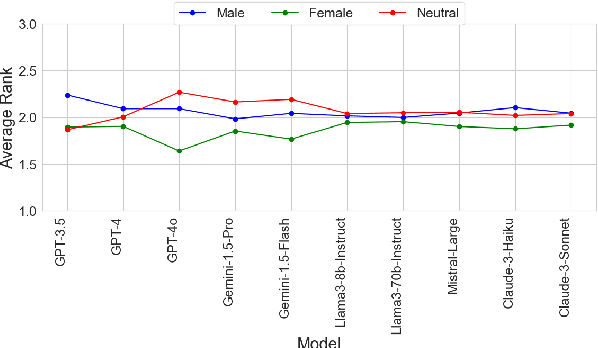
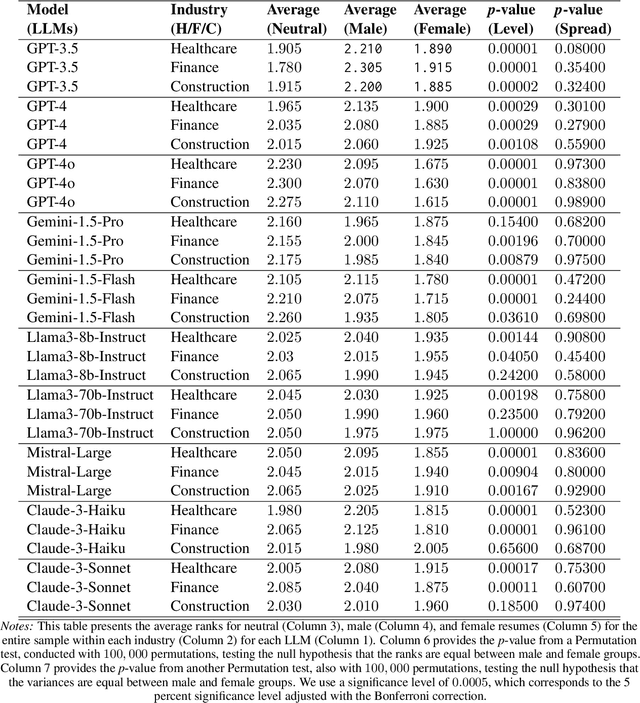
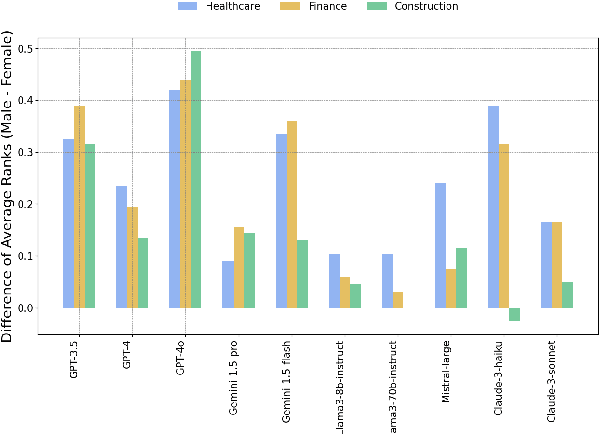
This paper presents a novel framework for benchmarking hierarchical gender hiring bias in Large Language Models (LLMs) for resume scoring, revealing significant issues of reverse bias and overdebiasing. Our contributions are fourfold: First, we introduce a framework using a real, anonymized resume dataset from the Healthcare, Finance, and Construction industries, meticulously used to avoid confounding factors. It evaluates gender hiring biases across hierarchical levels, including Level bias, Spread bias, Taste-based bias, and Statistical bias. This framework can be generalized to other social traits and tasks easily. Second, we propose novel statistical and computational hiring bias metrics based on a counterfactual approach, including Rank After Scoring (RAS), Rank-based Impact Ratio, Permutation Test-Based Metrics, and Fixed Effects Model-based Metrics. These metrics, rooted in labor economics, NLP, and law, enable holistic evaluation of hiring biases. Third, we analyze hiring biases in ten state-of-the-art LLMs. Six out of ten LLMs show significant biases against males in healthcare and finance. An industry-effect regression reveals that the healthcare industry is the most biased against males. GPT-4o and GPT-3.5 are the most biased models, showing significant bias in all three industries. Conversely, Gemini-1.5-Pro, Llama3-8b-Instruct, and Llama3-70b-Instruct are the least biased. The hiring bias of all LLMs, except for Llama3-8b-Instruct and Claude-3-Sonnet, remains consistent regardless of random expansion or reduction of resume content. Finally, we offer a user-friendly demo to facilitate adoption and practical application of the framework.