 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithfulness of LLM Self-Explanations for Commonsense Tasks: Larger Is Better, and Instruction-Tuning Allows Trade-Offs but Not Pareto Dominance
Mar 17, 2025As large language models (LLMs) become increasingly capable, ensuring that their self-generated explanations are faithful to their internal decision-making process is critical for safety and oversight. In this work, we conduct a comprehensive counterfactual faithfulness analysis across 62 models from 8 families, encompassing both pretrained and instruction-tuned variants and significantly extending prior studies of counterfactual tests. We introduce phi-CCT, a simplified variant of the Correlational Counterfactual Test, which avoids the need for token probabilities while explaining most of the variance of the original test. Our findings reveal clear scaling trends: larger models are consistently more faithful on our metrics. However, when comparing instruction-tuned and human-imitated explanations, we find that observed differences in faithfulness can often be attributed to explanation verbosity, leading to shifts along the true-positive/false-positive Pareto frontier. While instruction-tuning and prompting can influence this trade-off, we find limited evidence that they fundamentally expand the frontier of explanatory faithfulness beyond what is achievable with pretrained models of comparable size. Our analysis highlights the nuanced relationship between instruction-tuning, verbosity, and the faithful representation of model decision processes.
How Can We Diagnose and Treat Bias in Large Language Models for Clinical Decision-Making?
Oct 21, 2024



Recent advancements in Large Language Models (LLMs) have positioned them as powerful tools for clinical decision-making, with rapidly expanding applications in healthcare. However, concerns about bias remain a significant challenge in the clinical implementation of LLMs, particularly regarding gender and ethnicity. This research investigates the evaluation and mitigation of bias in LLMs applied to complex clinical cases, focusing on gender and ethnicity biases. We introduce a novel Counterfactual Patient Variations (CPV) dataset derived from the JAMA Clinical Challenge. Using this dataset, we built a framework for bias evaluation, employing both Multiple Choice Questions (MCQs) and corresponding explanations. We explore prompting with eight LLMs and fine-tuning as debiasing methods. Our findings reveal that addressing social biases in LLMs requires a multidimensional approach as mitigating gender bias can occur while introducing ethnicity biases, and that gender bias in LLM embeddings varies significantly across medical specialities. We demonstrate that evaluating both MCQ response and explanation processes is crucial, as correct responses can be based on biased \textit{reasoning}. We provide a framework for evaluating LLM bias in real-world clinical cases, offer insights into the complex nature of bias in these models, and present strategies for bias mitigation.
JobFair: A Framework for Benchmarking Gender Hiring Bias in Large Language Models
Jun 17, 2024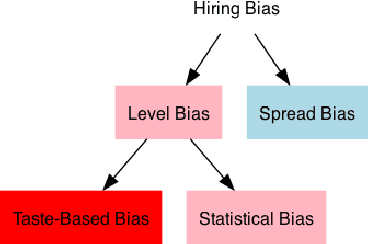
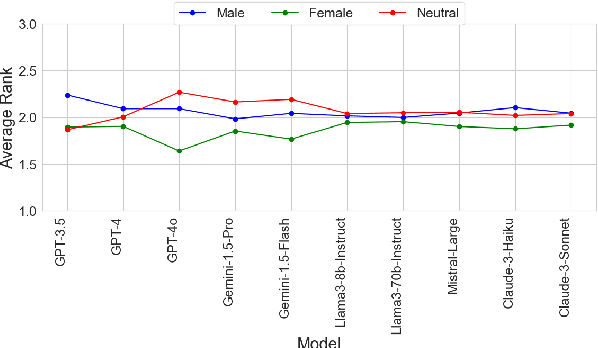
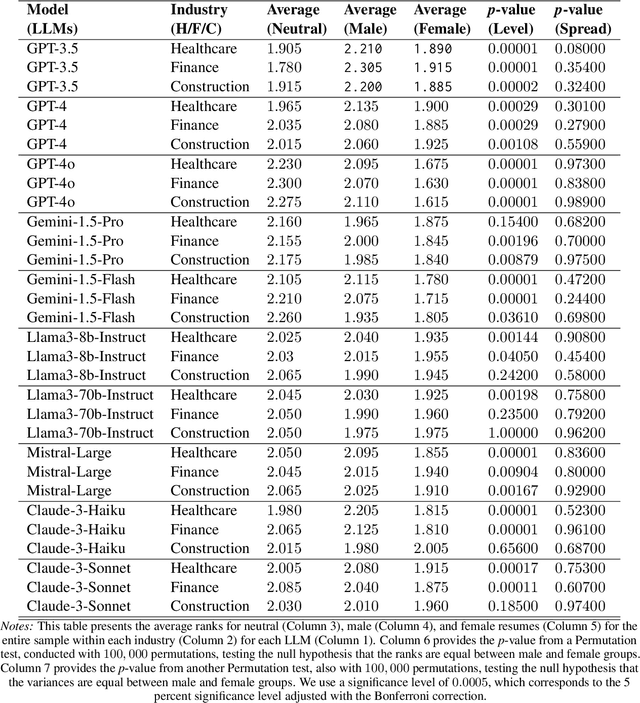
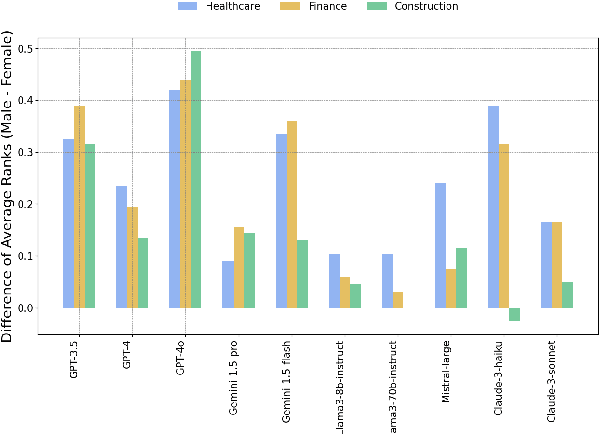
This paper presents a novel framework for benchmarking hierarchical gender hiring bias in Large Language Models (LLMs) for resume scoring, revealing significant issues of reverse bias and overdebiasing. Our contributions are fourfold: First, we introduce a framework using a real, anonymized resume dataset from the Healthcare, Finance, and Construction industries, meticulously used to avoid confounding factors. It evaluates gender hiring biases across hierarchical levels, including Level bias, Spread bias, Taste-based bias, and Statistical bias. This framework can be generalized to other social traits and tasks easily. Second, we propose novel statistical and computational hiring bias metrics based on a counterfactual approach, including Rank After Scoring (RAS), Rank-based Impact Ratio, Permutation Test-Based Metrics, and Fixed Effects Model-based Metrics. These metrics, rooted in labor economics, NLP, and law, enable holistic evaluation of hiring biases. Third, we analyze hiring biases in ten state-of-the-art LLMs. Six out of ten LLMs show significant biases against males in healthcare and finance. An industry-effect regression reveals that the healthcare industry is the most biased against males. GPT-4o and GPT-3.5 are the most biased models, showing significant bias in all three industries. Conversely, Gemini-1.5-Pro, Llama3-8b-Instruct, and Llama3-70b-Instruct are the least biased. The hiring bias of all LLMs, except for Llama3-8b-Instruct and Claude-3-Sonnet, remains consistent regardless of random expansion or reduction of resume content. Finally, we offer a user-friendly demo to facilitate adoption and practical application of the framework.
The Probabilities Also Matter: A More Faithful Metric for Faithfulness of Free-Text Explanations in Large Language Models
Apr 04, 2024



In order to oversee advanced AI systems, it is important to understand their underlying decision-making process. When prompted, large language models (LLMs) can provide natural language explanations or reasoning traces that sound plausible and receive high ratings from human annotators. However, it is unclear to what extent these explanations are faithful, i.e., truly capture the factors responsible for the model's predictions. In this work, we introduce Correlational Explanatory Faithfulness (CEF), a metric that can be used in faithfulness tests based on input interventions. Previous metrics used in such tests take into account only binary changes in the predictions. Our metric accounts for the total shift in the model's predicted label distribution, more accurately reflecting the explanations' faithfulness. We then introduce the Correlational Counterfactual Test (CCT) by instantiating CEF on the Counterfactual Test (CT) from Atanasova et al. (2023). We evaluate the faithfulness of free-text explanations generated by few-shot-prompted LLMs from the Llama2 family on three NLP tasks. We find that our metric measures aspects of faithfulness which the CT misses.
Auditing Large Language Models for Enhanced Text-Based Stereotype Detection and Probing-Based Bias Evaluation
Apr 02, 2024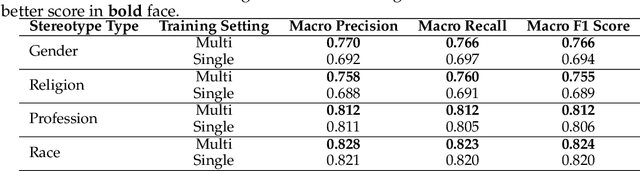

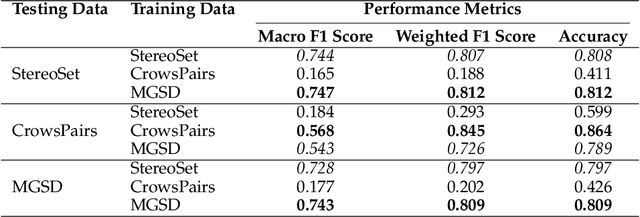

Recent advancements in Large Language Models (LLMs) have significantly increased their presence in human-facing Artificial Intelligence (AI) applications. However, LLMs could reproduce and even exacerbate stereotypical outputs from training data. This work introduces the Multi-Grain Stereotype (MGS) dataset, encompassing 51,867 instances across gender, race, profession, religion, and stereotypical text, collected by fusing multiple previously publicly available stereotype detection datasets. We explore different machine learning approaches aimed at establishing baselines for stereotype detection, and fine-tune several language models of various architectures and model sizes, presenting in this work a series of stereotypes classifier models for English text trained on MGS. To understand whether our stereotype detectors capture relevant features (aligning with human common sense) we utilise a variety of explanainable AI tools, including SHAP, LIME, and BertViz, and analyse a series of example cases discussing the results. Finally, we develop a series of stereotype elicitation prompts and evaluate the presence of stereotypes in text generation tasks with popular LLMs, using one of our best performing previously presented stereotypes detectors. Our experiments yielded several key findings: i) Training stereotype detectors in a multi-dimension setting yields better results than training multiple single-dimension classifiers.ii) The integrated MGS Dataset enhances both the in-dataset and cross-dataset generalisation ability of stereotype detectors compared to using the datasets separately. iii) There is a reduction in stereotypes in the content generated by GPT Family LLMs with newer versions.
Can Reinforcement Learning support policy makers? A preliminary study with Integrated Assessment Models
Dec 11, 2023Governments around the world aspire to ground decision-making on evidence. Many of the foundations of policy making - e.g. sensing patterns that relate to societal needs, developing evidence-based programs, forecasting potential outcomes of policy changes, and monitoring effectiveness of policy programs - have the potential to benefit from the use of large-scale datasets or simulations together with intelligent algorithms. These could, if designed and deployed in a way that is well grounded on scientific evidence, enable a more comprehensive, faster, and rigorous approach to policy making. Integrated Assessment Models (IAM) is a broad umbrella covering scientific models that attempt to link main features of society and economy with the biosphere into one modelling framework. At present, these systems are probed by policy makers and advisory groups in a hypothesis-driven manner. In this paper, we empirically demonstrate that modern Reinforcement Learning can be used to probe IAMs and explore the space of solutions in a more principled manner. While the implication of our results are modest since the environment is simplistic, we believe that this is a stepping stone towards more ambitious use cases, which could allow for effective exploration of policies and understanding of their consequences and limitations.
Can Population-based Engagement Improve Personalisation? A Novel Dataset and Experiments
Jun 22, 2022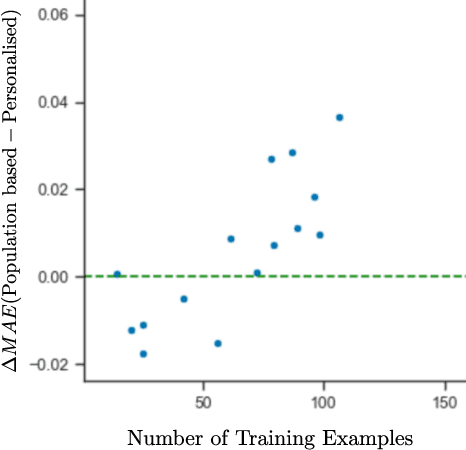
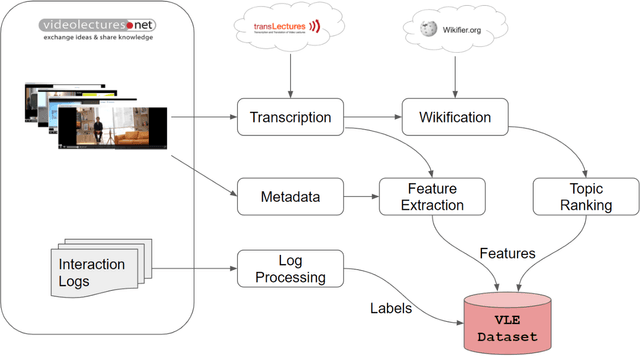
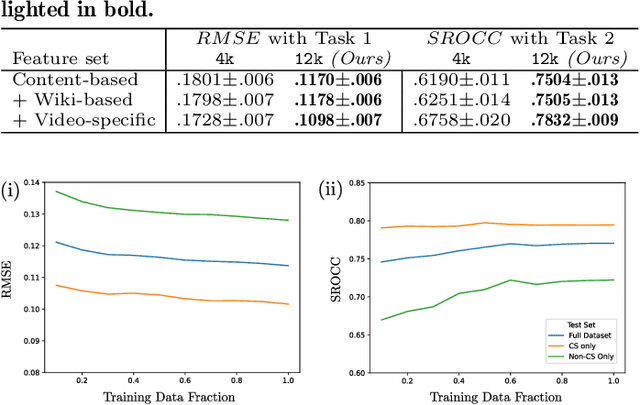
This work explores how population-based engagement prediction can address cold-start at scale in large learning resource collections. The paper introduces i) VLE, a novel dataset that consists of content and video based features extracted from publicly available scientific video lectures coupled with implicit and explicit signals related to learner engagement, ii) two standard tasks related to predicting and ranking context-agnostic engagement in video lectures with preliminary baselines and iii) a set of experiments that validate the usefulness of the proposed dataset. Our experimental results indicate that the newly proposed VLE dataset leads to building context-agnostic engagement prediction models that are significantly performant than ones based on previous datasets, mainly attributing to the increase of training examples. VLE dataset's suitability in building models towards Computer Science/ Artificial Intelligence education focused on e-learning/ MOOC use-cases is also evidenced. Further experiments in combining the built model with a personalising algorithm show promising improvements in addressing the cold-start problem encountered in educational recommenders. This is the largest and most diverse publicly available dataset to our knowledge that deals with learner engagement prediction tasks. The dataset, helper tools, descriptive statistics and example code snippets are available publicly.
Watch Less and Uncover More: Could Navigation Tools Help Users Search and Explore Videos?
Jan 10, 2022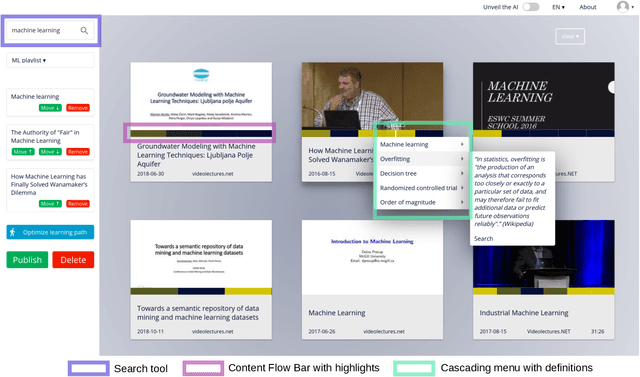
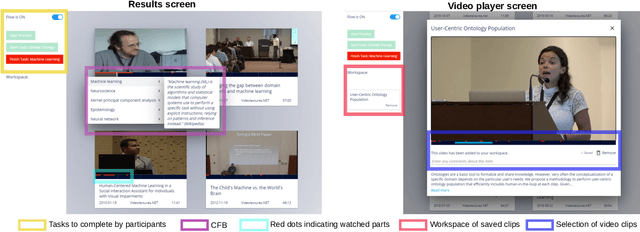
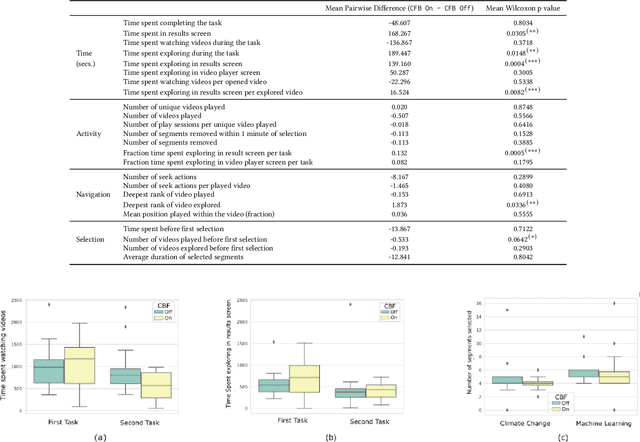
Prior research has shown how 'content preview tools' improve speed and accuracy of user relevance judgements across different information retrieval tasks. This paper describes a novel user interface tool, the Content Flow Bar, designed to allow users to quickly identify relevant fragments within informational videos to facilitate browsing, through a cognitively augmented form of navigation. It achieves this by providing semantic "snippets" that enable the user to rapidly scan through video content. The tool provides visually-appealing pop-ups that appear in a time series bar at the bottom of each video, allowing to see in advance and at a glance how topics evolve in the content. We conducted a user study to evaluate how the tool changes the users search experience in video retrieval, as well as how it supports exploration and information seeking. The user questionnaire revealed that participants found the Content Flow Bar helpful and enjoyable for finding relevant information in videos. The interaction logs of the user study, where participants interacted with the tool for completing two informational tasks, showed that it holds promise for enhancing discoverability of content both across and within videos. This discovered potential could leverage a new generation of navigation tools in search and information retrieval.
Progress in Self-Certified Neural Networks
Nov 23, 2021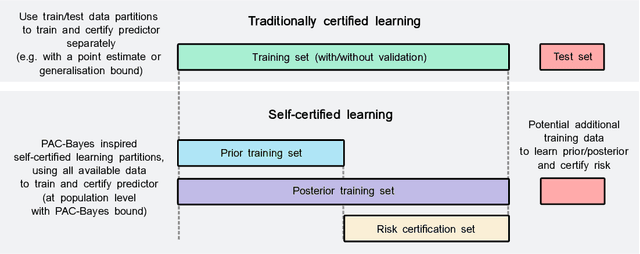


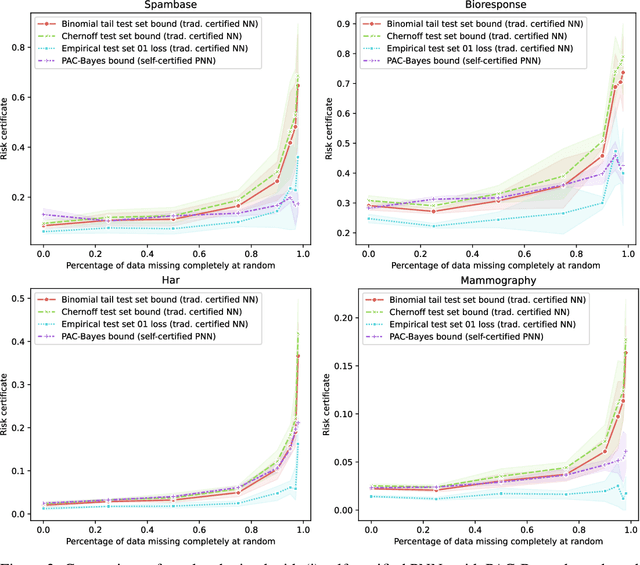
A learning method is self-certified if it uses all available data to simultaneously learn a predictor and certify its quality with a tight statistical certificate that is valid on unseen data. Recent work has shown that neural network models trained by optimising PAC-Bayes bounds lead not only to accurate predictors, but also to tight risk certificates, bearing promise towards achieving self-certified learning. In this context, learning and certification strategies based on PAC-Bayes bounds are especially attractive due to their ability to leverage all data to learn a posterior and simultaneously certify its risk with a tight numerical certificate. In this paper, we assess the progress towards self-certification in probabilistic neural networks learnt by PAC-Bayes inspired objectives. We empirically compare (on 4 classification datasets) classical test set bounds for deterministic predictors and a PAC-Bayes bound for randomised self-certified predictors. We first show that both of these generalisation bounds are not too far from out-of-sample test set errors. We then show that in data starvation regimes, holding out data for the test set bounds adversely affects generalisation performance, while self-certified strategies based on PAC-Bayes bounds do not suffer from this drawback, proving that they might be a suitable choice for the small data regime. We also find that probabilistic neural networks learnt by PAC-Bayes inspired objectives lead to certificates that can be surprisingly competitive with commonly used test set bounds.
* arXiv admin note: substantial text overlap with arXiv:2109.10304
An AI-based Learning Companion Promoting Lifelong Learning Opportunities for All
Nov 16, 2021Artifical Intelligence (AI) in Education has great potential for building more personalised curricula, as well as democratising education worldwide and creating a Renaissance of new ways of teaching and learning. We believe this is a crucial moment for setting the foundations of AI in education in the beginning of this Fourth Industrial Revolution. This report aims to synthesize how AI might change (and is already changing) how we learn, as well as what technological features are crucial for these AI systems in education, with the end goal of starting this pressing dialogue of how the future of AI in education should unfold, engaging policy makers, engineers, researchers and obviously, teachers and learners. This report also presents the advances within the X5GON project, a European H2020 project aimed at building and deploying a cross-modal, cross-lingual, cross-cultural, cross-domain and cross-site personalised learning platform for Open Educational Resources (OER).