 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2021 Tokyo Olympics Multilingual News Article Dataset
Feb 10, 2025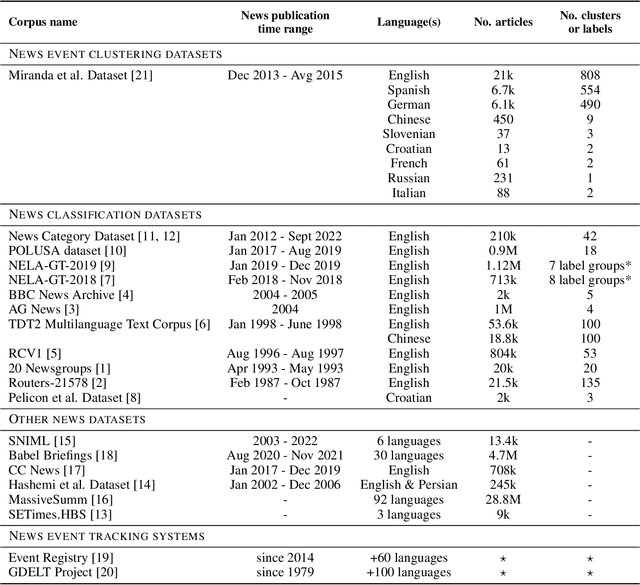
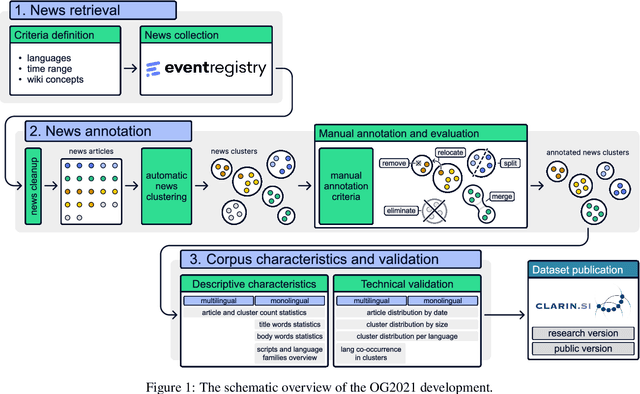

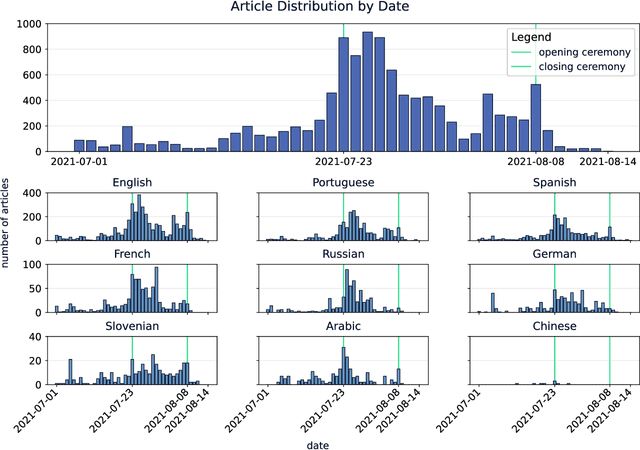
In this paper, we introduce a dataset of multilingual news articles covering the 2021 Tokyo Olympics. A total of 10,940 news articles were gathered from 1,918 different publishers, covering 1,350 sub-events of the 2021 Olympics, and published between July 1, 2021, and August 14, 2021. These articles are written in nine languages from different language families and in different scripts. To create the dataset, the raw news articles were first retrieved via a service that collects and analyzes news articles. Then, the articles were grouped using an online clustering algorithm, with each group containing articles reporting on the same sub-event. Finally, the groups were manually annotated and evaluated. The development of this dataset aims to provide a resource for evaluating the performance of multilingual news clustering algorithms, for which limited datasets are available. It can also be used to analyze the dynamics and events of the 2021 Tokyo Olympics from different perspectives. The dataset is available in CSV format and can be accessed from the CLARIN.SI repository.
An AI-based Learning Companion Promoting Lifelong Learning Opportunities for All
Nov 16, 2021Artifical Intelligence (AI) in Education has great potential for building more personalised curricula, as well as democratising education worldwide and creating a Renaissance of new ways of teaching and learning. We believe this is a crucial moment for setting the foundations of AI in education in the beginning of this Fourth Industrial Revolution. This report aims to synthesize how AI might change (and is already changing) how we learn, as well as what technological features are crucial for these AI systems in education, with the end goal of starting this pressing dialogue of how the future of AI in education should unfold, engaging policy makers, engineers, researchers and obviously, teachers and learners. This report also presents the advances within the X5GON project, a European H2020 project aimed at building and deploying a cross-modal, cross-lingual, cross-cultural, cross-domain and cross-site personalised learning platform for Open Educational Resources (OER).
PEEK: A Large Dataset of Learner Engagement with Educational Videos
Sep 13, 2021
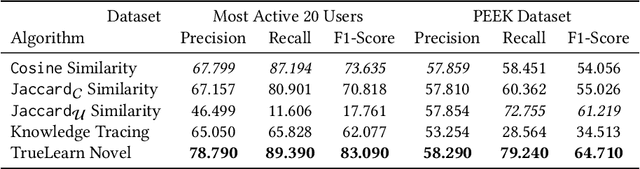


Educational recommenders have received much less attention in comparison to e-commerce and entertainment-related recommenders, even though efficient intelligent tutors have great potential to improve learning gains. One of the main challenges in advancing this research direction is the scarcity of large, publicly available datasets. In this work, we release a large, novel dataset of learners engaging with educational videos in-the-wild. The dataset, named Personalised Educational Engagement with Knowledge Topics PEEK, is the first publicly available dataset of this nature. The video lectures have been associated with Wikipedia concepts related to the material of the lecture, thus providing a humanly intuitive taxonomy. We believe that granular learner engagement signals in unison with rich content representations will pave the way to building powerful personalization algorithms that will revolutionise educational and informational recommendation systems. Towards this goal, we 1) construct a novel dataset from a popular video lecture repository, 2) identify a set of benchmark algorithms to model engagement, and 3) run extensive experimentation on the PEEK dataset to demonstrate its value. Our experiments with the dataset show promise in building powerful informational recommender systems. The dataset and the support code is available publicly.