 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2021 Tokyo Olympics Multilingual News Article Dataset
Feb 10, 2025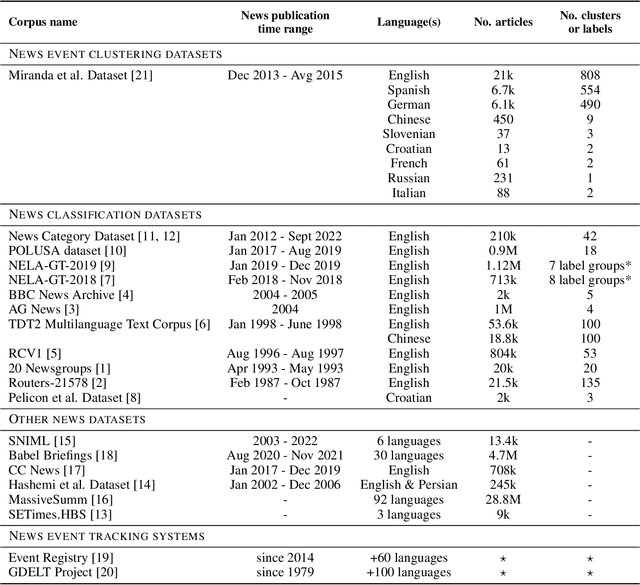
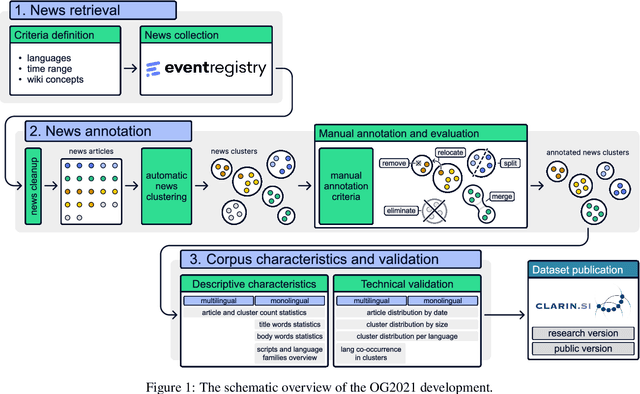

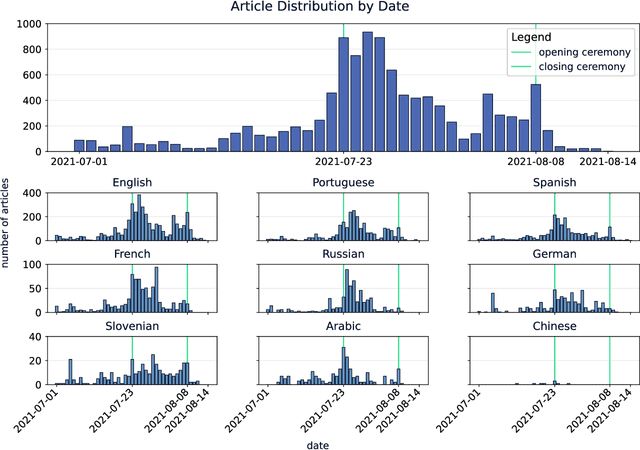
In this paper, we introduce a dataset of multilingual news articles covering the 2021 Tokyo Olympics. A total of 10,940 news articles were gathered from 1,918 different publishers, covering 1,350 sub-events of the 2021 Olympics, and published between July 1, 2021, and August 14, 2021. These articles are written in nine languages from different language families and in different scripts. To create the dataset, the raw news articles were first retrieved via a service that collects and analyzes news articles. Then, the articles were grouped using an online clustering algorithm, with each group containing articles reporting on the same sub-event. Finally, the groups were manually annotated and evaluated. The development of this dataset aims to provide a resource for evaluating the performance of multilingual news clustering algorithms, for which limited datasets are available. It can also be used to analyze the dynamics and events of the 2021 Tokyo Olympics from different perspectives. The dataset is available in CSV format and can be accessed from the CLARIN.SI repository.
Multimodal Metadata Assignment for Cultural Heritage Artifacts
Jun 01, 2024We develop a multimodal classifier for the cultural heritage domain using a late fusion approach and introduce a novel dataset. The three modalities are Image, Text, and Tabular data. We based the image classifier on a ResNet convolutional neural network architecture and the text classifier on a multilingual transformer architecture (XML-Roberta). Both are trained as multitask classifiers and use the focal loss to handle class imbalance. Tabular data and late fusion are handled by Gradient Tree Boosting. We also show how we leveraged specific data models and taxonomy in a Knowledge Graph to create the dataset and to store classification results. All individual classifiers accurately predict missing properties in the digitized silk artifacts, with the multimodal approach providing the best results.
Dealing with zero-inflated data: achieving SOTA with a two-fold machine learning approach
Oct 12, 2023



In many cases, a machine learning model must learn to correctly predict a few data points with particular values of interest in a broader range of data where many target values are zero. Zero-inflated data can be found in diverse scenarios, such as lumpy and intermittent demands, power consumption for home appliances being turned on and off, impurities measurement in distillation processes, and even airport shuttle demand prediction. The presence of zeroes affects the models' learning and may result in poor performance. Furthermore, zeroes also distort the metrics used to compute the model's prediction quality. This paper showcases two real-world use cases (home appliances classification and airport shuttle demand prediction) where a hierarchical model applied in the context of zero-inflated data leads to excellent results. In particular, for home appliances classification, the weighted average of Precision, Recall, F1, and AUC ROC was increased by 27%, 34%, 49%, and 27%, respectively. Furthermore, it is estimated that the proposed approach is also four times more energy efficient than the SOTA approach against which it was compared to. Two-fold models performed best in all cases when predicting airport shuttle demand, and the difference against other models has been proven to be statistically significant.
Human in the AI loop via xAI and Active Learning for Visual Inspection
Jul 17, 2023Industrial revolutions have historically disrupted manufacturing by introducing automation into production. Increasing automation reshapes the role of the human worker. Advances in robotics and artificial intelligence open new frontiers of human-machine collaboration. Such collaboration can be realized considering two sub-fields of artificial intelligence: active learning and explainable artificial intelligence. Active learning aims to devise strategies that help obtain data that allows machine learning algorithms to learn better. On the other hand, explainable artificial intelligence aims to make the machine learning models intelligible to the human person. The present work first describes Industry 5.0, human-machine collaboration, and state-of-the-art regarding quality inspection, emphasizing visual inspection. Then it outlines how human-machine collaboration could be realized and enhanced in visual inspection. Finally, some of the results obtained in the EU H2020 STAR project regarding visual inspection are shared, considering artificial intelligence, human digital twins, and cybersecurity.
Synthetic Data Augmentation Using GAN For Improved Automated Visual Inspection
Dec 19, 2022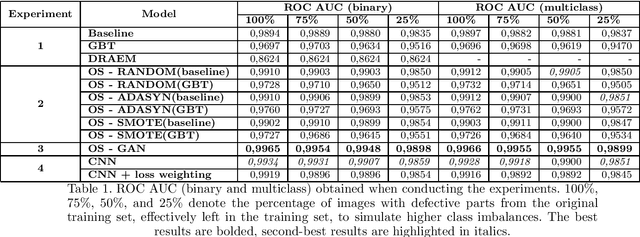
Quality control is a crucial activity performed by manufacturing companies to ensure their products conform to the requirements and specifications. The introduction of artificial intelligence models enables to automate the visual quality inspection, speeding up the inspection process and ensuring all products are evaluated under the same criteria. In this research, we compare supervised and unsupervised defect detection techniques and explore data augmentation techniques to mitigate the data imbalance in the context of automated visual inspection. Furthermore, we use Generative Adversarial Networks for data augmentation to enhance the classifiers' discriminative performance. Our results show that state-of-the-art unsupervised defect detection does not match the performance of supervised models but can be used to reduce the labeling workload by more than 50%. Furthermore, the best classification performance was achieved considering GAN-based data generation with AUC ROC scores equal to or higher than 0,9898, even when increasing the dataset imbalance by leaving only 25\% of the images denoting defective products. We performed the research with real-world data provided by Philips Consumer Lifestyle BV.
Robust Anomaly Map Assisted Multiple Defect Detection with Supervised Classification Techniques
Dec 19, 2022



Industry 4.0 aims to optimize the manufacturing environment by leveraging new technological advances, such as new sensing capabilities and artificial intelligence. The DRAEM technique has shown state-of-the-art performance for unsupervised classification. The ability to create anomaly maps highlighting areas where defects probably lie can be leveraged to provide cues to supervised classification models and enhance their performance. Our research shows that the best performance is achieved when training a defect detection model by providing an image and the corresponding anomaly map as input. Furthermore, such a setting provides consistent performance when framing the defect detection as a binary or multiclass classification problem and is not affected by class balancing policies. We performed the experiments on three datasets with real-world data provided by Philips Consumer Lifestyle BV.
A Commonsense-Infused Language-Agnostic Learning Framework for Enhancing Prediction of Political Polarity in Multilingual News Headlines
Dec 01, 2022

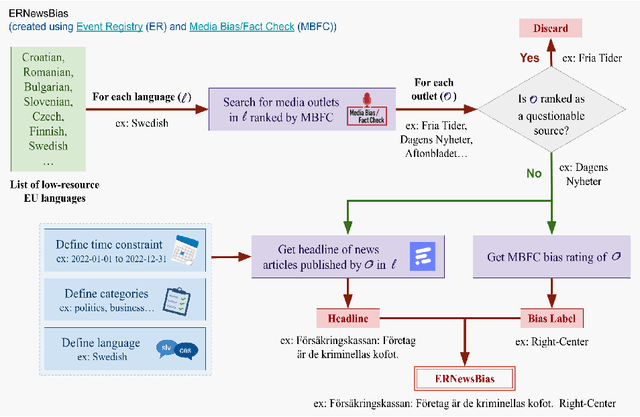
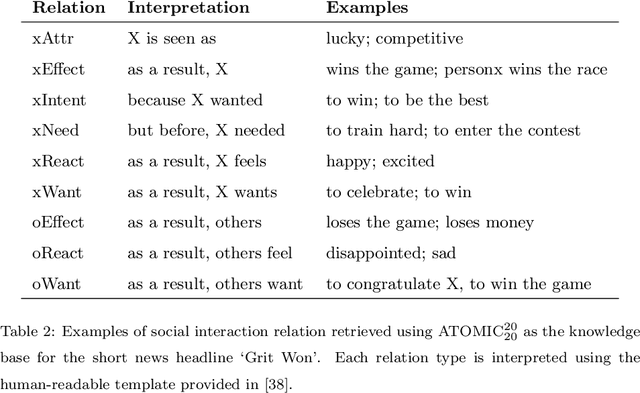
Predicting the political polarity of news headlines is a challenging task that becomes even more challenging in a multilingual setting with low-resource languages. To deal with this, we propose to utilise the Inferential Commonsense Knowledge via a Translate-Retrieve-Translate strategy to introduce a learning framework. To begin with, we use the method of translation and retrieval to acquire the inferential knowledge in the target language. We then employ an attention mechanism to emphasise important inferences. We finally integrate the attended inferences into a multilingual pre-trained language model for the task of bias prediction. To evaluate the effectiveness of our framework, we present a dataset of over 62.6K multilingual news headlines in five European languages annotated with their respective political polarities. We evaluate several state-of-the-art multilingual pre-trained language models since their performance tends to vary across languages (low/high resource). Evaluation results demonstrate that our proposed framework is effective regardless of the models employed. Overall, the best performing model trained with only headlines show 0.90 accuracy and F1, and 0.83 jaccard score. With attended knowledge in our framework, the same model show an increase in 2.2% accuracy and F1, and 3.6% jaccard score. Extending our experiments to individual languages reveals that the models we analyze for Slovenian perform significantly worse than other languages in our dataset. To investigate this, we assess the effect of translation quality on prediction performance. It indicates that the disparity in performance is most likely due to poor translation quality. We release our dataset and scripts at: https://github.com/Swati17293/KG-Multi-Bias for future research. Our framework has the potential to benefit journalists, social scientists, news producers, and consumers.
Machine Beats Machine: Machine Learning Models to Defend Against Adversarial Attacks
Sep 28, 2022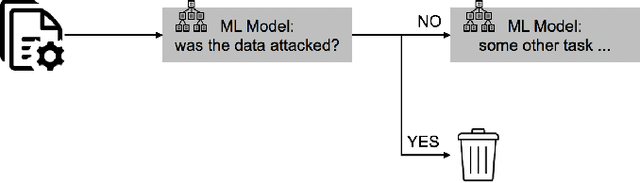



We propose using a two-layered deployment of machine learning models to prevent adversarial attacks. The first layer determines whether the data was tampered, while the second layer solves a domain-specific problem. We explore three sets of features and three dataset variations to train machine learning models. Our results show clustering algorithms achieved promising results. In particular, we consider the best results were obtained by applying the DBSCAN algorithm to the structured structural similarity index measure computed between the images and a white reference image.
Forecasting Sensor Values in Waste-To-Fuel Plants: a Case Study
Sep 28, 2022
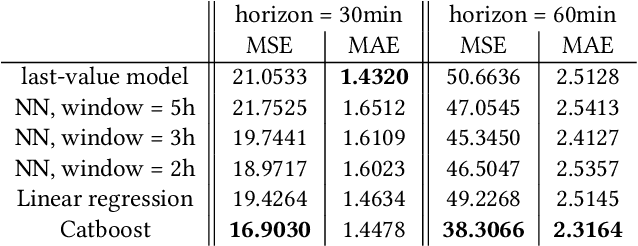
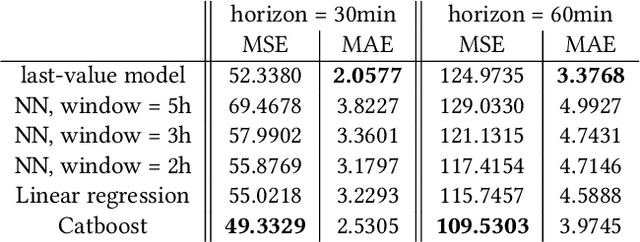
In this research, we develop machine learning models to predict future sensor readings of a waste-to-fuel plant, which would enable proactive control of the plant's operations. We developed models that predict sensor readings for 30 and 60 minutes into the future. The models were trained using historical data, and predictions were made based on sensor readings taken at a specific time. We compare three types of models: (a) a n\"aive prediction that considers only the last predicted value, (b) neural networks that make predictions based on past sensor data (we consider different time window sizes for making a prediction), and (c) a gradient boosted tree regressor created with a set of features that we developed. We developed and tested our models on a real-world use case at a waste-to-fuel plant in Canada. We found that approach (c) provided the best results, while approach (b) provided mixed results and was not able to outperform the n\"aive consistently.
Active Learning and Approximate Model Calibration for Automated Visual Inspection in Manufacturing
Sep 12, 2022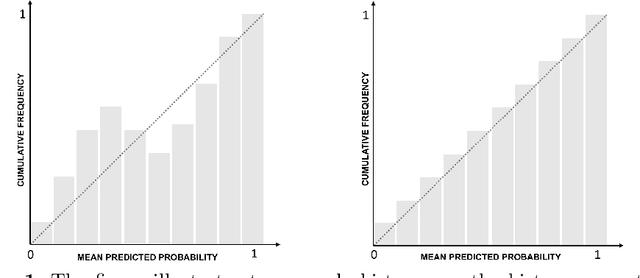
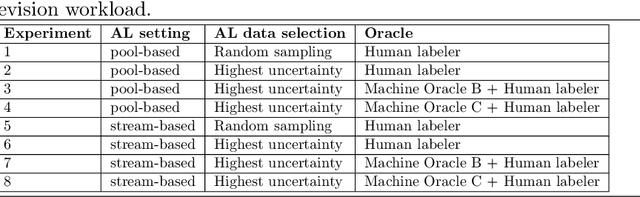
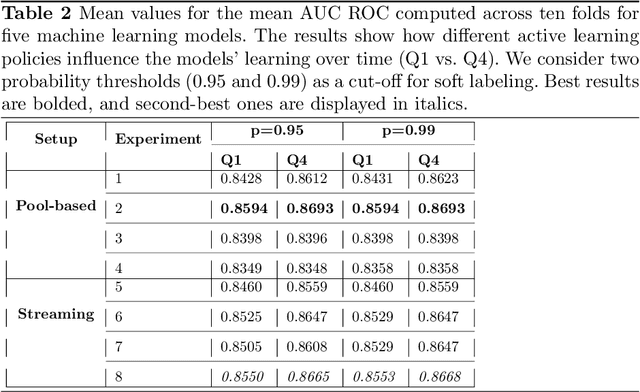

Quality control is a crucial activity performed by manufacturing enterprises to ensure that their products meet quality standards and avoid potential damage to the brand's reputation. The decreased cost of sensors and connectivity enabled increasing digitalization of manufacturing. In addition, artificial intelligence enables higher degrees of automation, reducing overall costs and time required for defect inspection. This research compares three active learning approaches (with single and multiple oracles) to visual inspection. We propose a novel approach to probabilities calibration of classification models and two new metrics to assess the performance of the calibration without the need for ground truth. We performed experiments on real-world data provided by Philips Consumer Lifestyle BV. Our results show that explored active learning settings can reduce the data labeling effort by between three and four percent without detriment to the overall quality goals, considering a threshold of p=0.95. Furthermore, we show that the proposed metrics successfully capture relevant information otherwise available to metrics used up to date only through ground truth data. Therefore, the proposed metrics can be used to estimate the quality of models' probability calibration without committing to a labeling effort to obtain ground truth data.