 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustOpt: A Clustering-based Approach for Representing and Visualizing the Search Dynamics of Numerical Metaheuristic Optimization Algorithms
Jul 03, 2025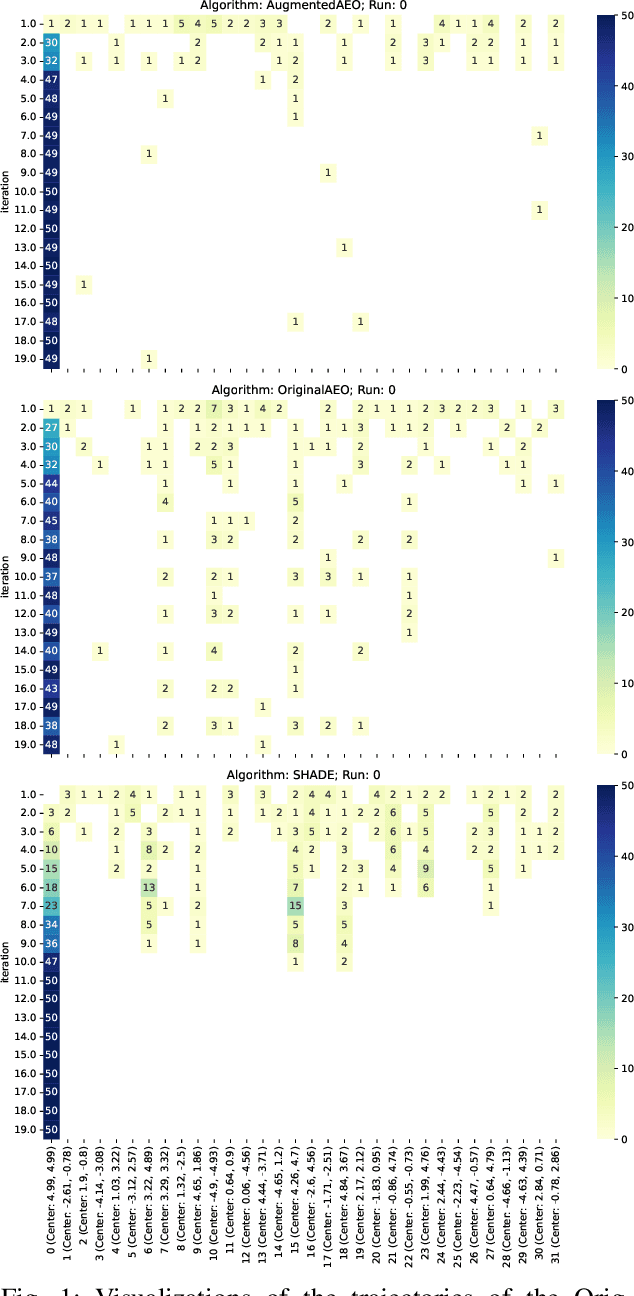
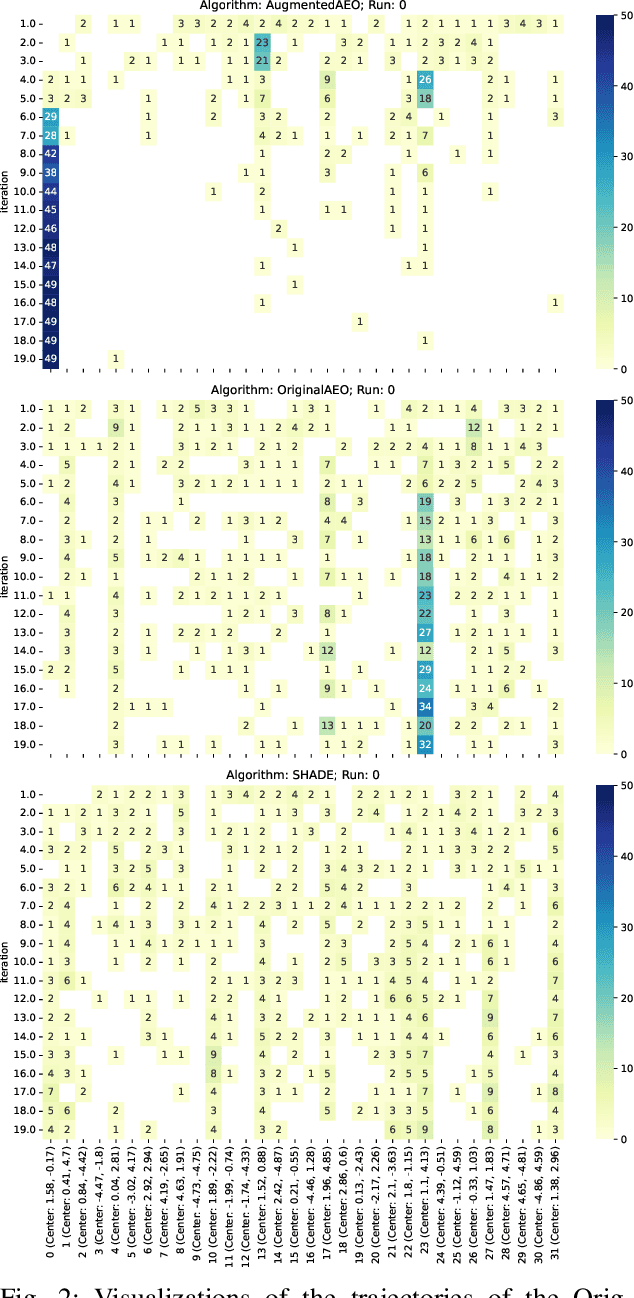
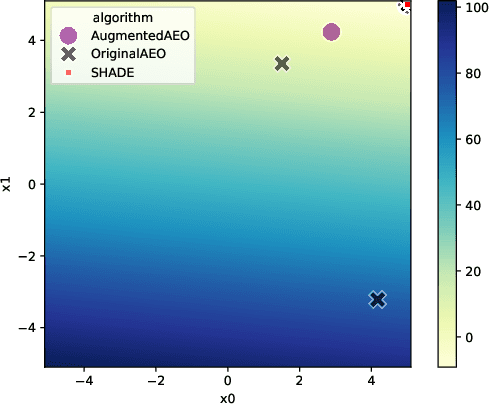
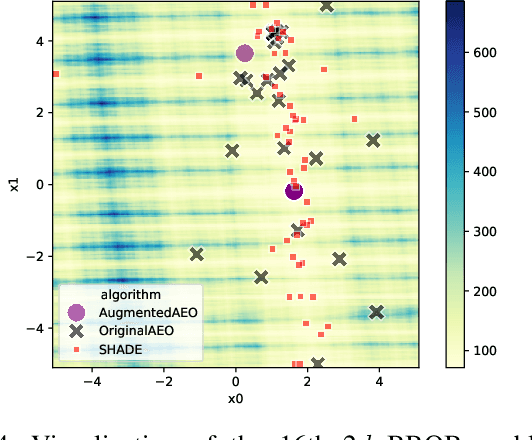
Understanding the behavior of numerical metaheuristic optimization algorithms is critical for advancing their development and application. Traditional visualization techniques, such as convergence plots, trajectory mapping, and fitness landscape analysis, often fall short in illustrating the structural dynamics of the search process, especially in high-dimensional or complex solution spaces. To address this, we propose a novel representation and visualization methodology that clusters solution candidates explored by the algorithm and tracks the evolution of cluster memberships across iterations, offering a dynamic and interpretable view of the search process. Additionally, we introduce two metrics - algorithm stability and algorithm similarity- to quantify the consistency of search trajectories across runs of an individual algorithm and the similarity between different algorithms, respectively. We apply this methodology to a set of ten numerical metaheuristic algorithms, revealing insights into their stability and comparative behaviors, thereby providing a deeper understanding of their search dynamics.
Comparing Optimization Algorithms Through the Lens of Search Behavior Analysis
Jul 02, 2025The field of numerical optimization has recently seen a surge in the development of "novel" metaheuristic algorithms, inspired by metaphors derived from natural or human-made processes, which have been widely criticized for obscuring meaningful innovations and failing to distinguish themselves from existing approaches. Aiming to address these concerns, we investigate the applicability of statistical tests for comparing algorithms based on their search behavior. We utilize the cross-match statistical test to compare multivariate distributions and assess the solutions produced by 114 algorithms from the MEALPY library. These findings are incorporated into an empirical analysis aiming to identify algorithms with similar search behaviors.
The Pitfalls of Benchmarking in Algorithm Selection: What We Are Getting Wrong
May 12, 2025Algorithm selection, aiming to identify the best algorithm for a given problem, plays a pivotal role in continuous black-box optimization. A common approach involves representing optimization functions using a set of features, which are then used to train a machine learning meta-model for selecting suitable algorithms. Various approaches have demonstrated the effectiveness of these algorithm selection meta-models. However, not all evaluation approaches are equally valid for assessing the performance of meta-models. We highlight methodological issues that frequently occur in the community and should be addressed when evaluating algorithm selection approaches. First, we identify flaws with the "leave-instance-out" evaluation technique. We show that non-informative features and meta-models can achieve high accuracy, which should not be the case with a well-designed evaluation framework. Second, we demonstrate that measuring the performance of optimization algorithms with metrics sensitive to the scale of the objective function requires careful consideration of how this impacts the construction of the meta-model, its predictions, and the model's error. Such metrics can falsely present overly optimistic performance assessments of the meta-models. This paper emphasizes the importance of careful evaluation, as loosely defined methodologies can mislead researchers, divert efforts, and introduce noise into the field
Landscape Features in Single-Objective Continuous Optimization: Have We Hit a Wall in Algorithm Selection Generalization?
Jan 29, 2025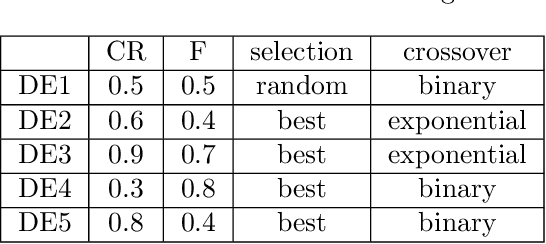
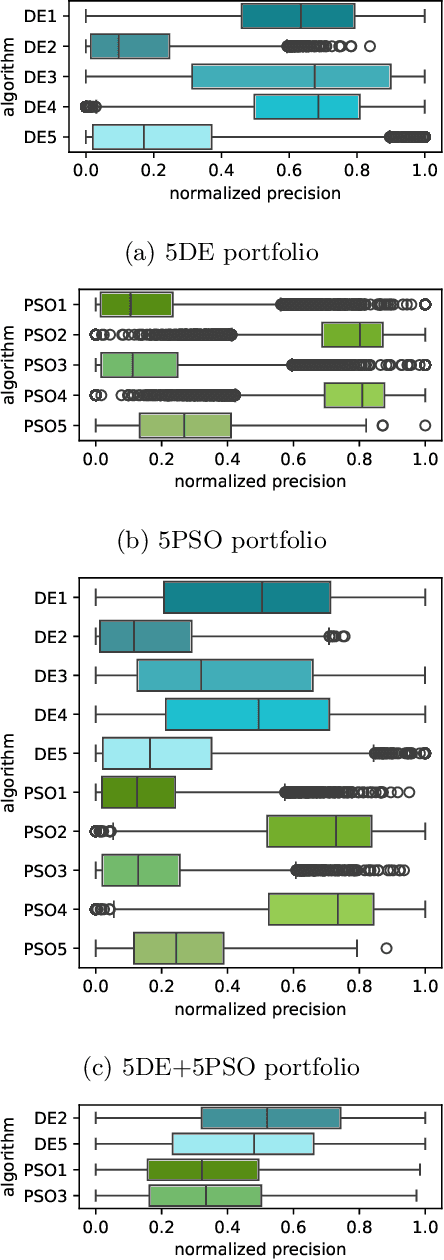
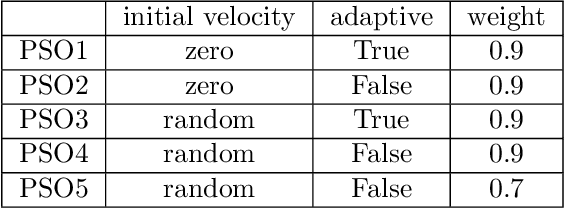
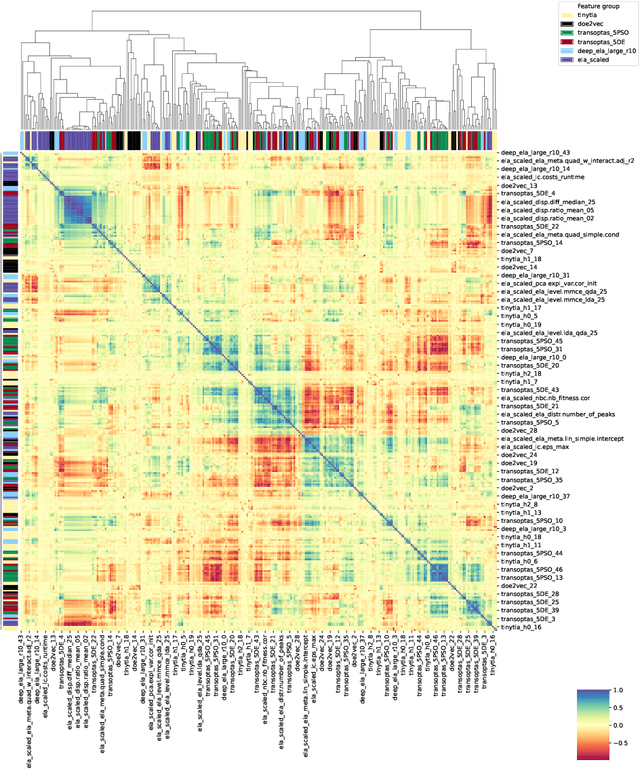
%% Text of abstract The process of identifying the most suitable optimization algorithm for a specific problem, referred to as algorithm selection (AS), entails training models that leverage problem landscape features to forecast algorithm performance. A significant challenge in this domain is ensuring that AS models can generalize effectively to novel, unseen problems. This study evaluates the generalizability of AS models based on different problem representations in the context of single-objective continuous optimization. In particular, it considers the most widely used Exploratory Landscape Analysis features, as well as recently proposed Topological Landscape Analysis features, and features based on deep learning, such as DeepELA, TransOptAS and Doe2Vec. Our results indicate that when presented with out-of-distribution evaluation data, none of the feature-based AS models outperform a simple baseline model, i.e., a Single Best Solver.
A Survey of Meta-features Used for Automated Selection of Algorithms for Black-box Single-objective Continuous Optimization
Jun 08, 2024
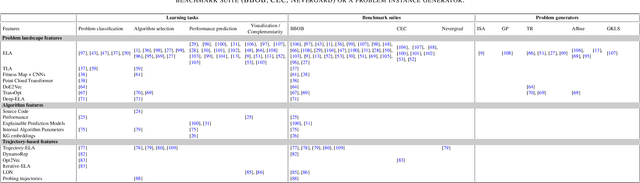
The selection of the most appropriate algorithm to solve a given problem instance, known as algorithm selection, is driven by the potential to capitalize on the complementary performance of different algorithms across sets of problem instances. However, determining the optimal algorithm for an unseen problem instance has been shown to be a challenging task, which has garnered significant attention from researchers in recent years. In this survey, we conduct an overview of the key contributions to algorithm selection in the field of single-objective continuous black-box optimization. We present ongoing work in representation learning of meta-features for optimization problem instances, algorithm instances, and their interactions. We also study machine learning models for automated algorithm selection, configuration, and performance prediction. Through this analysis, we identify gaps in the state of the art, based on which we present ideas for further development of meta-feature representations.
TransOpt: Transformer-based Representation Learning for Optimization Problem Classification
Nov 29, 2023We propose a representation of optimization problem instances using a transformer-based neural network architecture trained for the task of problem classification of the 24 problem classes from the Black-box Optimization Benchmarking (BBOB) benchmark. We show that transformer-based methods can be trained to recognize problem classes with accuracies in the range of 70\%-80\% for different problem dimensions, suggesting the possible application of transformer architectures in acquiring representations for black-box optimization problems.
Dealing with zero-inflated data: achieving SOTA with a two-fold machine learning approach
Oct 12, 2023



In many cases, a machine learning model must learn to correctly predict a few data points with particular values of interest in a broader range of data where many target values are zero. Zero-inflated data can be found in diverse scenarios, such as lumpy and intermittent demands, power consumption for home appliances being turned on and off, impurities measurement in distillation processes, and even airport shuttle demand prediction. The presence of zeroes affects the models' learning and may result in poor performance. Furthermore, zeroes also distort the metrics used to compute the model's prediction quality. This paper showcases two real-world use cases (home appliances classification and airport shuttle demand prediction) where a hierarchical model applied in the context of zero-inflated data leads to excellent results. In particular, for home appliances classification, the weighted average of Precision, Recall, F1, and AUC ROC was increased by 27%, 34%, 49%, and 27%, respectively. Furthermore, it is estimated that the proposed approach is also four times more energy efficient than the SOTA approach against which it was compared to. Two-fold models performed best in all cases when predicting airport shuttle demand, and the difference against other models has been proven to be statistically significant.
DynamoRep: Trajectory-Based Population Dynamics for Classification of Black-box Optimization Problems
Jun 08, 2023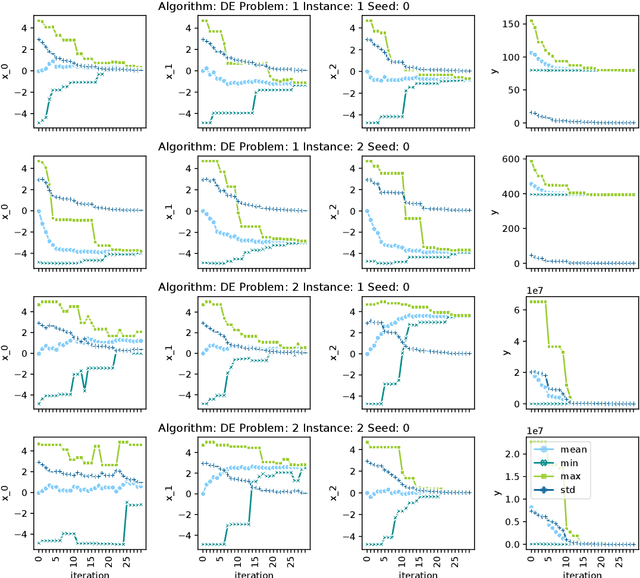
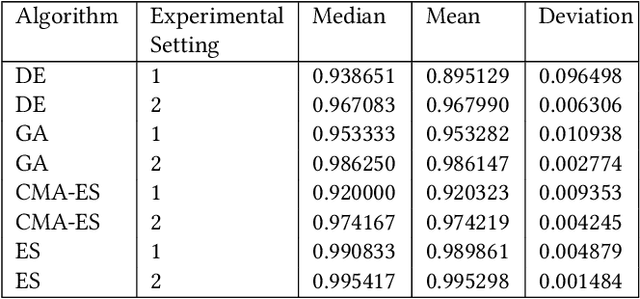
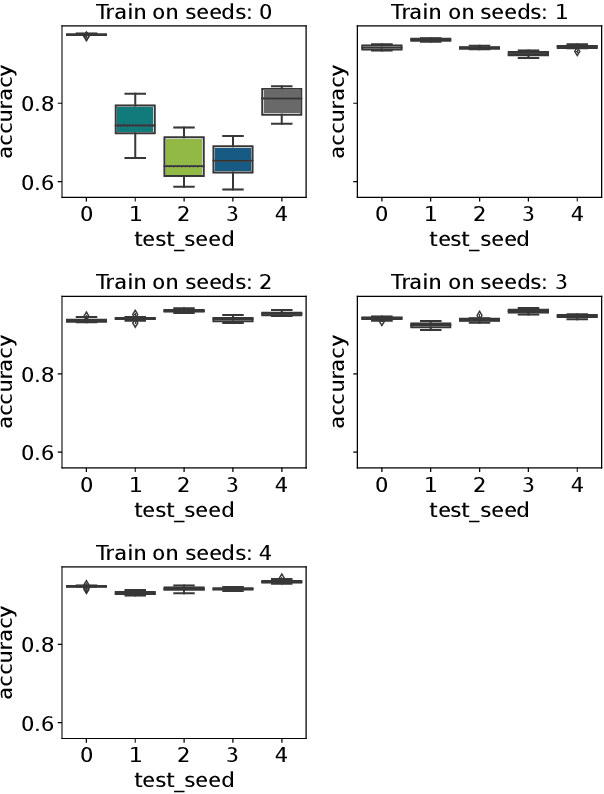
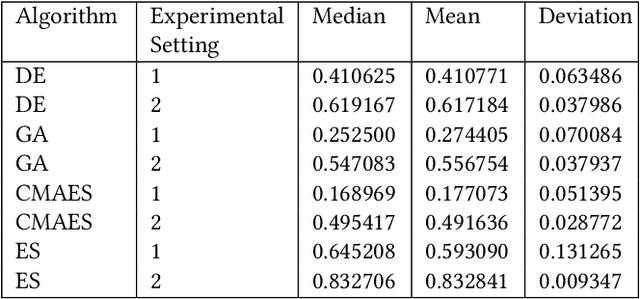
The application of machine learning (ML) models to the analysis of optimization algorithms requires the representation of optimization problems using numerical features. These features can be used as input for ML models that are trained to select or to configure a suitable algorithm for the problem at hand. Since in pure black-box optimization information about the problem instance can only be obtained through function evaluation, a common approach is to dedicate some function evaluations for feature extraction, e.g., using random sampling. This approach has two key downsides: (1) It reduces the budget left for the actual optimization phase, and (2) it neglects valuable information that could be obtained from a problem-solver interaction. In this paper, we propose a feature extraction method that describes the trajectories of optimization algorithms using simple descriptive statistics. We evaluate the generated features for the task of classifying problem classes from the Black Box Optimization Benchmarking (BBOB) suite. We demonstrate that the proposed DynamoRep features capture enough information to identify the problem class on which the optimization algorithm is running, achieving a mean classification accuracy of 95% across all experiments.