 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Temporal Graph Networks for Real-Time Correction of GNSS Jamming-Induced Deviations
Sep 17, 2025Global Navigation Satellite Systems (GNSS) are increasingly disrupted by intentional jamming, degrading availability precisely when positioning and timing must remain operational. We address this by reframing jamming mitigation as dynamic graph regression and introducing a receiver-centric deep temporal graph network that predicts, and thus corrects, the receivers horizontal deviation in real time. At each 1 Hz epoch, the satellite receiver environment is represented as a heterogeneous star graph (receiver center, tracked satellites as leaves) with time varying attributes (e.g., SNR, azimuth, elevation, latitude/longitude). A single layer Heterogeneous Graph ConvLSTM (HeteroGCLSTM) aggregates one hop spatial context and temporal dynamics over a short history to output the 2D deviation vector applied for on the fly correction. We evaluate on datasets from two distinct receivers under three jammer profiles, continuous wave (cw), triple tone (cw3), and wideband FM, each exercised at six power levels between -45 and -70 dBm, with 50 repetitions per scenario (prejam/jam/recovery). Against strong multivariate time series baselines (MLP, uniform CNN, and Seq2Point CNN), our model consistently attains the lowest mean absolute error (MAE). At -45 dBm, it achieves 3.64 cm (GP01/cw), 7.74 cm (GP01/cw3), 4.41 cm (ublox/cw), 4.84 cm (ublox/cw3), and 4.82 cm (ublox/FM), improving to 1.65-2.08 cm by -60 to -70 dBm. On mixed mode datasets pooling all powers, MAE is 3.78 cm (GP01) and 4.25 cm (ublox10), outperforming Seq2Point, MLP, and CNN. A split study shows superior data efficiency: with only 10\% training data our approach remains well ahead of baselines (20 cm vs. 36-42 cm).
A Network Science Approach to Granular Time Series Segmentation
May 23, 2025Time series segmentation (TSS) is one of the time series (TS) analysis techniques, that has received considerably less attention compared to other TS related tasks. In recent years, deep learning architectures have been introduced for TSS, however their reliance on sliding windows limits segmentation granularity due to fixed window sizes and strides. To overcome these challenges, we propose a new more granular TSS approach that utilizes the Weighted Dual Perspective Visbility Graph (WDPVG) TS into a graph and combines it with a Graph Attention Network (GAT). By transforming TS into graphs, we are able to capture different structural aspects of the data that would otherwise remain hidden. By utilizing the representation learning capabilities of Graph Neural Networks, our method is able to effectively identify meaningful segments within the TS. To better understand the potential of our approach, we also experimented with different TS-to-graph transformations and compared their performance. Our contributions include: a) formulating the TSS as a node classification problem on graphs; b) conducting an extensive analysis of various TS- to-graph transformations applied to TSS using benchmark datasets from the TSSB repository; c) providing the first detailed study on utilizing GNNs for analyzing graph representations of TS in the context of TSS; d) demonstrating the effectiveness of our method, which achieves an average F1 score of 0.97 across 59 diverse TSS benchmark datasets; e) outperforming the seq2point baseline method by 0.05 in terms of F1 score; and f) reducing the required training data compared to the baseline methods.
MRM3: Machine Readable ML Model Metadata
May 19, 2025As the complexity and number of machine learning (ML) models grows, well-documented ML models are essential for developers and companies to use or adapt them to their specific use cases. Model metadata, already present in unstructured format as model cards in online repositories such as Hugging Face, could be more structured and machine readable while also incorporating environmental impact metrics such as energy consumption and carbon footprint. Our work extends the existing State of the Art by defining a structured schema for ML model metadata focusing on machine-readable format and support for integration into a knowledge graph (KG) for better organization and querying, enabling a wider set of use cases. Furthermore, we present an example wireless localization model metadata dataset consisting of 22 models trained on 4 datasets, integrated into a Neo4j-based KG with 113 nodes and 199 relations.
RAG Enabled Conversations about Household Electricity Monitoring
Jun 03, 2024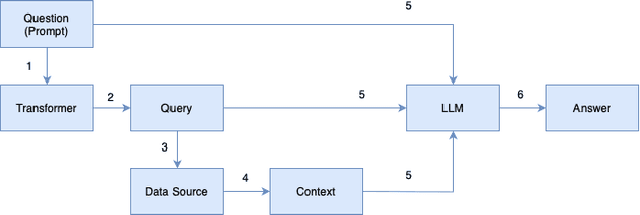
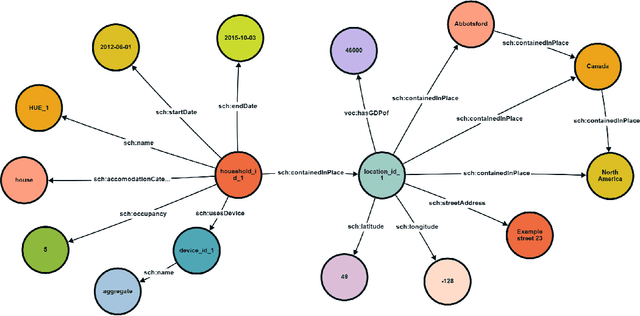


In this paper, we investigate the integration of Retrieval Augmented Generation (RAG) with large language models (LLMs) such as ChatGPT, Gemini, and Llama to enhance the accuracy and specificity of responses to complex questions about electricity datasets. Recognizing the limitations of LLMs in generating precise and contextually relevant answers due to their dependency on the patterns in training data rather than factual understanding, we propose a solution that leverages a specialized electricity knowledge graph. This approach facilitates the retrieval of accurate, real-time data which is then synthesized with the generative capabilities of LLMs. Our findings illustrate that the RAG approach not only reduces the incidence of incorrect information typically generated by LLMs but also significantly improves the quality of the output by grounding responses in verifiable data. This paper details our methodology, presents a comparative analysis of responses with and without RAG, and discusses the implications of our findings for future applications of AI in specialized sectors like energy data analysis.
Towards Data-Driven Electricity Management: Multi-Region Harmonized Data and Knowledge Graph
May 29, 2024Due to growing population and technological advances, global electricity consumption, and consequently also CO2 emissions are increasing. The residential sector makes up 25% of global electricity consumption and has great potential to increase efficiency and reduce CO2 footprint without sacrificing comfort. However, a lack of uniform consumption data at the household level spanning multiple regions hinders large-scale studies and robust multi-region model development. This paper introduces a multi-region dataset compiled from publicly available sources and presented in a uniform format. This data enables machine learning tasks such as disaggregation, demand forecasting, appliance ON/OFF classification, etc. Furthermore, we develop an RDF knowledge graph that characterizes the electricity consumption of the households and contextualizes it with household related properties enabling semantic queries and interoperability with other open knowledge bases like Wikidata and DBpedia. This structured data can be utilized to inform various stakeholders towards data-driven policy and business development.
Dealing with zero-inflated data: achieving SOTA with a two-fold machine learning approach
Oct 12, 2023



In many cases, a machine learning model must learn to correctly predict a few data points with particular values of interest in a broader range of data where many target values are zero. Zero-inflated data can be found in diverse scenarios, such as lumpy and intermittent demands, power consumption for home appliances being turned on and off, impurities measurement in distillation processes, and even airport shuttle demand prediction. The presence of zeroes affects the models' learning and may result in poor performance. Furthermore, zeroes also distort the metrics used to compute the model's prediction quality. This paper showcases two real-world use cases (home appliances classification and airport shuttle demand prediction) where a hierarchical model applied in the context of zero-inflated data leads to excellent results. In particular, for home appliances classification, the weighted average of Precision, Recall, F1, and AUC ROC was increased by 27%, 34%, 49%, and 27%, respectively. Furthermore, it is estimated that the proposed approach is also four times more energy efficient than the SOTA approach against which it was compared to. Two-fold models performed best in all cases when predicting airport shuttle demand, and the difference against other models has been proven to be statistically significant.
Deep Feature Learning for Wireless Spectrum Data
Aug 07, 2023In recent years, the traditional feature engineering process for training machine learning models is being automated by the feature extraction layers integrated in deep learning architectures. In wireless networks, many studies were conducted in automatic learning of feature representations for domain-related challenges. However, most of the existing works assume some supervision along the learning process by using labels to optimize the model. In this paper, we investigate an approach to learning feature representations for wireless transmission clustering in a completely unsupervised manner, i.e. requiring no labels in the process. We propose a model based on convolutional neural networks that automatically learns a reduced dimensionality representation of the input data with 99.3% less components compared to a baseline principal component analysis (PCA). We show that the automatic representation learning is able to extract fine-grained clusters containing the shapes of the wireless transmission bursts, while the baseline enables only general separability of the data based on the background noise.
Towards Sustainable Deep Learning for Multi-Label Classification on NILM
Jul 18, 2023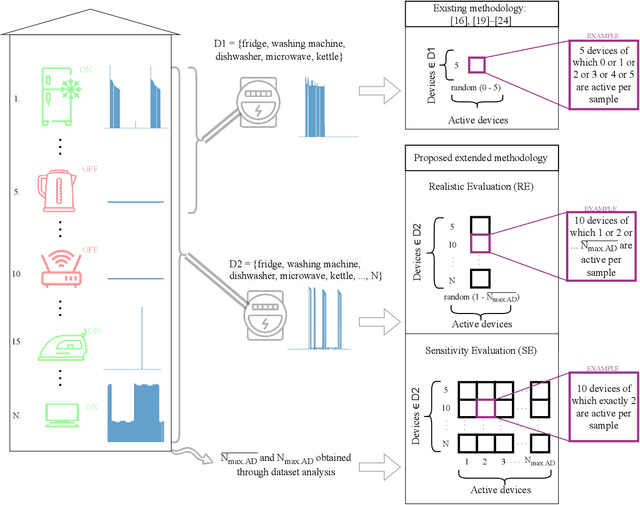
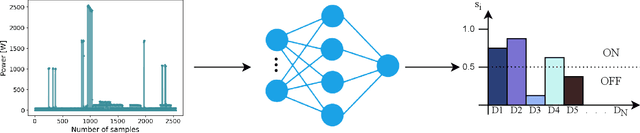
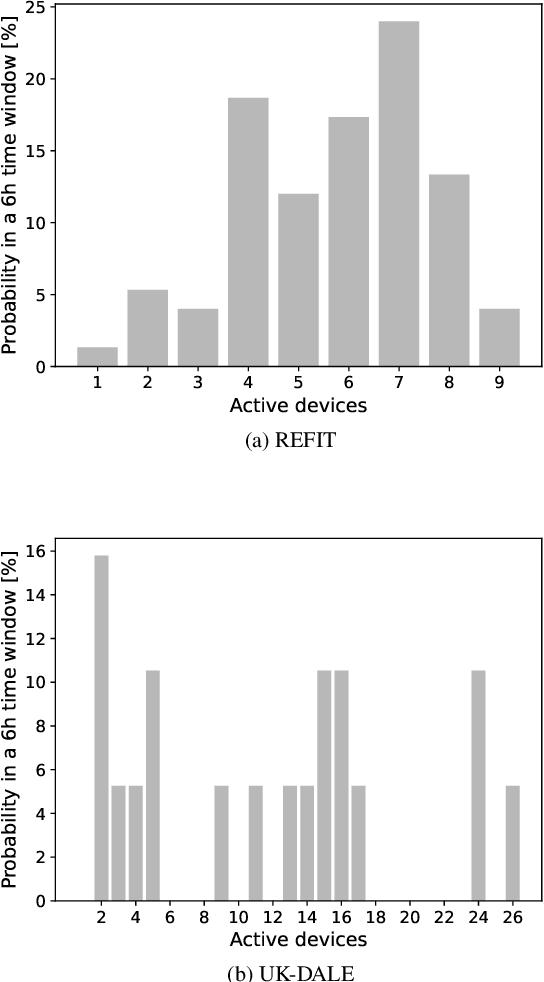
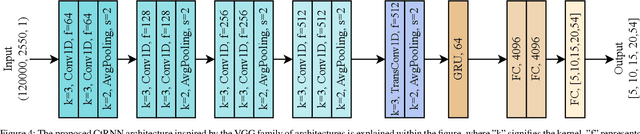
Non-intrusive load monitoring (NILM) is the process of obtaining appliance-level data from a single metering point, measuring total electricity consumption of a household or a business. Appliance-level data can be directly used for demand response applications and energy management systems as well as for awareness raising and motivation for improvements in energy efficiency and reduction in the carbon footprint. Recently, classical machine learning and deep learning (DL) techniques became very popular and proved as highly effective for NILM classification, but with the growing complexity these methods are faced with significant computational and energy demands during both their training and operation. In this paper, we introduce a novel DL model aimed at enhanced multi-label classification of NILM with improved computation and energy efficiency. We also propose a testing methodology for comparison of different models using data synthesized from the measurement datasets so as to better represent real-world scenarios. Compared to the state-of-the-art, the proposed model has its carbon footprint reduced by more than 23% while providing on average approximately 8 percentage points in performance improvement when testing on data derived from REFIT and UK-DALE datasets.
XAI for Self-supervised Clustering of Wireless Spectrum Activity
May 17, 2023The so-called black-box deep learning (DL) models are increasingly used in classification tasks across many scientific disciplines, including wireless communications domain. In this trend, supervised DL models appear as most commonly proposed solutions to domain-related classification problems. Although they are proven to have unmatched performance, the necessity for large labeled training data and their intractable reasoning, as two major drawbacks, are constraining their usage. The self-supervised architectures emerged as a promising solution that reduces the size of the needed labeled data, but the explainability problem remains. In this paper, we propose a methodology for explaining deep clustering, self-supervised learning architectures comprised of a representation learning part based on a Convolutional Neural Network (CNN) and a clustering part. For the state of the art representation learning part, our methodology employs Guided Backpropagation to interpret the regions of interest of the input data. For the clustering part, the methodology relies on Shallow Trees to explain the clustering result using optimized depth decision tree. Finally, a data-specific visualizations part enables connection for each of the clusters to the input data trough the relevant features. We explain on a use case of wireless spectrum activity clustering how the CNN-based, deep clustering architecture reasons.
Self-supervised Learning for Clustering of Wireless Spectrum Activity
Sep 22, 2022

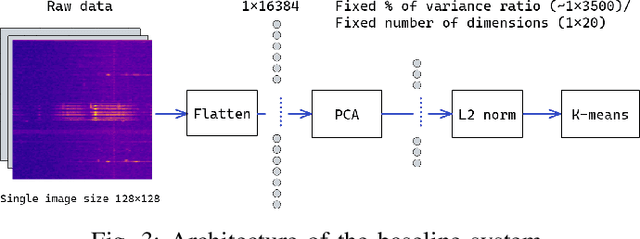
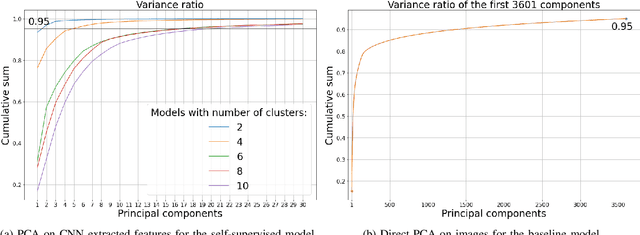
In recent years, much work has been done on processing of wireless spectral data involving machine learning techniques in domain-related problems for cognitive radio networks, such as anomaly detection, modulation classification, technology classification and device fingerprinting. Most of the solutions are based on labeled data, created in a controlled manner and processed with supervised learning approaches. Labeling spectral data is a laborious and expensive process, being one of the main drawbacks of using supervised approaches. In this paper, we introduce self-supervised learning for exploring spectral activities using real-world, unlabeled data. We show that the proposed model achieves superior performance regarding the quality of extracted features and clustering performance. We achieve reduction of the feature vectors size by 2 orders of magnitude (from 3601 to 20), while improving performance by 2 to 2.5 times across the evaluation metrics, supported by visual assessment. Using 15 days of continuous narrowband spectrum sensing data, we found that 17% of the spectrogram slices contain no or very weak transmissions, 36% contain mostly IEEE 802.15.4, 26% contain coexisting IEEE 802.15.4 with LoRA and proprietary activity, 12% contain LoRA with variable background noise and 9% contain only dotted activity, representing LoRA and proprietary transmissions.