 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Principles of Zero-Shot Self-Supervised Unknown Emitter Detectors
Nov 10, 2025The proliferation of wireless devices necessitates more robust and reliable emitter detection and identification for critical tasks such as spectrum management and network security. Existing studies exploring methods for unknown emitters identification, however, are typically hindered by their dependence on labeled or proprietary datasets, unrealistic assumptions (e.g. all samples with identical transmitted messages), or deficiency of systematic evaluations across different architectures and design dimensions. In this work, we present a comprehensive evaluation of unknown emitter detection systems across key aspects of the design space, focusing on data modality, learning approaches, and feature learning modules. We demonstrate that prior self-supervised, zero-shot emitter detection approaches commonly use datasets with identical transmitted messages. To address this limitation, we propose a 2D-Constellation data modality for scenarios with varying messages, achieving up to a 40\% performance improvement in ROC-AUC, NMI, and F1 metrics compared to conventional raw I/Q data. Furthermore, we introduce interpretable Kolmogorov-Arnold Networks (KANs) to enhance model transparency, and a Singular Value Decomposition (SVD)-based initialization procedure for feature learning modules operating on sparse 2D-Constellation data, which improves the performance of Deep Clustering approaches by up to 40\% across the same metrics comparing to the modules without SVD initialization. We evaluate all data modalities and learning modules across three learning approaches: Deep Clustering, Auto Encoder and Contrastive Learning.
SABER: Symbolic Regression-based Angle of Arrival and Beam Pattern Estimator
Oct 30, 2025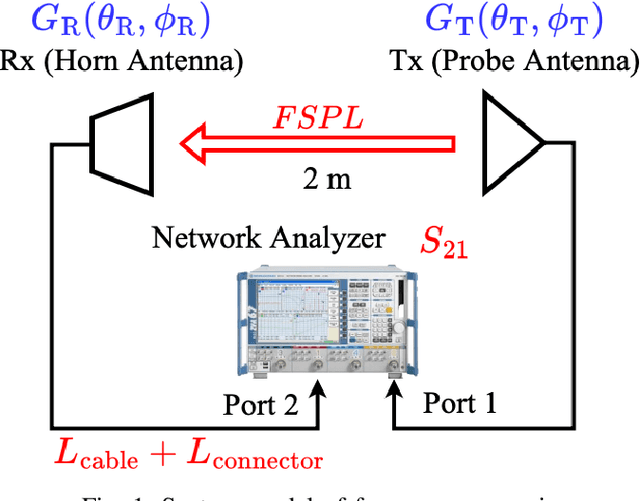
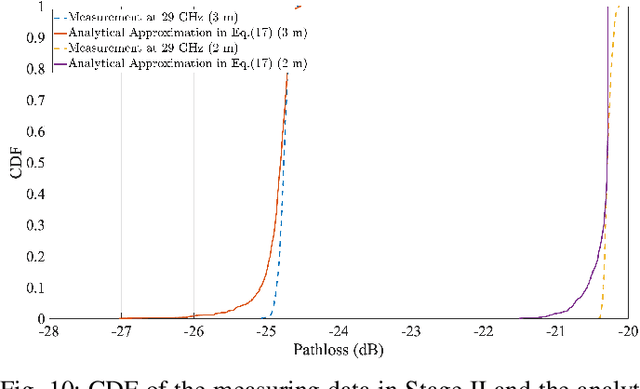
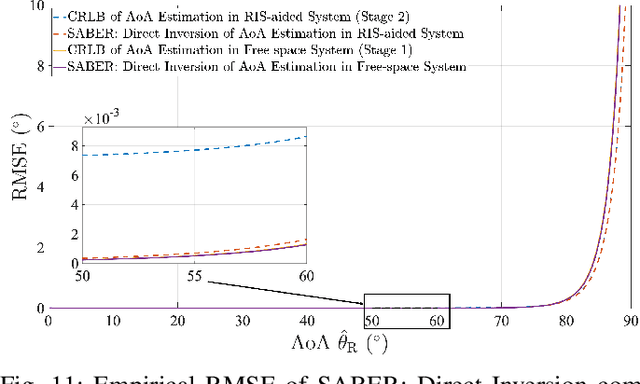
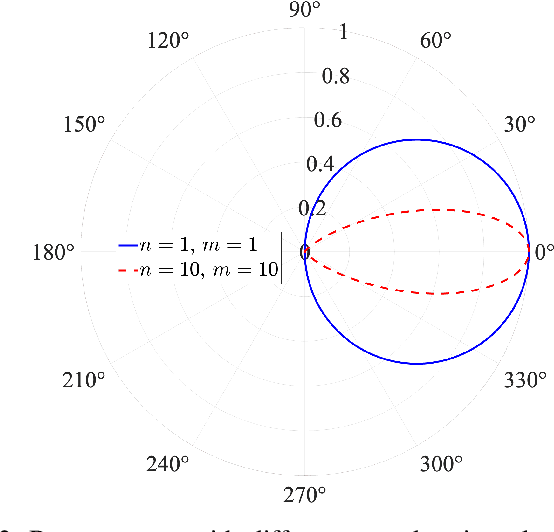
Accurate Angle-of-arrival (AoA) estimation is essential for next-generation wireless communication systems to enable reliable beamforming, high-precision localization, and integrated sensing. Unfortunately, classical high-resolution techniques require multi-element arrays and extensive snapshot collection, while generic Machine Learning (ML) approaches often yield black-box models that lack physical interpretability. To address these limitations, we propose a Symbolic Regression (SR)-based ML framework. Namely, Symbolic Regression-based Angle of Arrival and Beam Pattern Estimator (SABER), a constrained symbolic-regression framework that automatically discovers closed-form beam pattern and AoA models from path loss measurements with interpretability. SABER achieves high accuracy while bridging the gap between opaque ML methods and interpretable physics-driven estimators. First, we validate our approach in a controlled free-space anechoic chamber, showing that both direct inversion of the known $\cos^n$ beam and a low-order polynomial surrogate achieve sub-0.5 degree Mean Absolute Error (MAE). A purely unconstrained SR method can further reduce the error of the predicted angles, but produces complex formulas that lack physical insight. Then, we implement the same SR-learned inversions in a real-world, Reconfigurable Intelligent Surface (RIS)-aided indoor testbed. SABER and unconstrained SR models accurately recover the true AoA with near-zero error. Finally, we benchmark SABER against the Cram\'er-Rao Lower Bounds (CRLBs). Our results demonstrate that SABER is an interpretable and accurate alternative to state-of-the-art and black-box ML-based methods for AoA estimation.
Deep Temporal Graph Networks for Real-Time Correction of GNSS Jamming-Induced Deviations
Sep 17, 2025Global Navigation Satellite Systems (GNSS) are increasingly disrupted by intentional jamming, degrading availability precisely when positioning and timing must remain operational. We address this by reframing jamming mitigation as dynamic graph regression and introducing a receiver-centric deep temporal graph network that predicts, and thus corrects, the receivers horizontal deviation in real time. At each 1 Hz epoch, the satellite receiver environment is represented as a heterogeneous star graph (receiver center, tracked satellites as leaves) with time varying attributes (e.g., SNR, azimuth, elevation, latitude/longitude). A single layer Heterogeneous Graph ConvLSTM (HeteroGCLSTM) aggregates one hop spatial context and temporal dynamics over a short history to output the 2D deviation vector applied for on the fly correction. We evaluate on datasets from two distinct receivers under three jammer profiles, continuous wave (cw), triple tone (cw3), and wideband FM, each exercised at six power levels between -45 and -70 dBm, with 50 repetitions per scenario (prejam/jam/recovery). Against strong multivariate time series baselines (MLP, uniform CNN, and Seq2Point CNN), our model consistently attains the lowest mean absolute error (MAE). At -45 dBm, it achieves 3.64 cm (GP01/cw), 7.74 cm (GP01/cw3), 4.41 cm (ublox/cw), 4.84 cm (ublox/cw3), and 4.82 cm (ublox/FM), improving to 1.65-2.08 cm by -60 to -70 dBm. On mixed mode datasets pooling all powers, MAE is 3.78 cm (GP01) and 4.25 cm (ublox10), outperforming Seq2Point, MLP, and CNN. A split study shows superior data efficiency: with only 10\% training data our approach remains well ahead of baselines (20 cm vs. 36-42 cm).
Automated Modeling Method for Pathloss Model Discovery
May 29, 2025Modeling propagation is the cornerstone for designing and optimizing next-generation wireless systems, with a particular emphasis on 5G and beyond era. Traditional modeling methods have long relied on statistic-based techniques to characterize propagation behavior across different environments. With the expansion of wireless communication systems, there is a growing demand for methods that guarantee the accuracy and interoperability of modeling. Artificial intelligence (AI)-based techniques, in particular, are increasingly being adopted to overcome this challenge, although the interpretability is not assured with most of these methods. Inspired by recent advancements in AI, this paper proposes a novel approach that accelerates the discovery of path loss models while maintaining interpretability. The proposed method automates the model formulation, evaluation, and refinement, facilitating model discovery. We evaluate two techniques: one based on Deep Symbolic Regression, offering full interpretability, and the second based on Kolmogorov-Arnold Networks, providing two levels of interpretability. Both approaches are evaluated on two synthetic and two real-world datasets. Our results show that Kolmogorov-Arnold Networks achieve R^2 values close to 1 with minimal prediction error, while Deep Symbolic Regression generates compact models with moderate accuracy. Moreover, on the selected examples, we demonstrate that automated methods outperform traditional methods, achieving up to 75% reduction in prediction errors, offering accurate and explainable solutions with potential to increase the efficiency of discovering next-generation path loss models.
Data Model Design for Explainable Machine Learning-based Electricity Applications
May 29, 2025The transition from traditional power grids to smart grids, significant increase in the use of renewable energy sources, and soaring electricity prices has triggered a digital transformation of the energy infrastructure that enables new, data driven, applications often supported by machine learning models. However, the majority of the developed machine learning models rely on univariate data. To date, a structured study considering the role meta-data and additional measurements resulting in multivariate data is missing. In this paper we propose a taxonomy that identifies and structures various types of data related to energy applications. The taxonomy can be used to guide application specific data model development for training machine learning models. Focusing on a household electricity forecasting application, we validate the effectiveness of the proposed taxonomy in guiding the selection of the features for various types of models. As such, we study of the effect of domain, contextual and behavioral features on the forecasting accuracy of four interpretable machine learning techniques and three openly available datasets. Finally, using a feature importance techniques, we explain individual feature contributions to the forecasting accuracy.
A Network Science Approach to Granular Time Series Segmentation
May 23, 2025Time series segmentation (TSS) is one of the time series (TS) analysis techniques, that has received considerably less attention compared to other TS related tasks. In recent years, deep learning architectures have been introduced for TSS, however their reliance on sliding windows limits segmentation granularity due to fixed window sizes and strides. To overcome these challenges, we propose a new more granular TSS approach that utilizes the Weighted Dual Perspective Visbility Graph (WDPVG) TS into a graph and combines it with a Graph Attention Network (GAT). By transforming TS into graphs, we are able to capture different structural aspects of the data that would otherwise remain hidden. By utilizing the representation learning capabilities of Graph Neural Networks, our method is able to effectively identify meaningful segments within the TS. To better understand the potential of our approach, we also experimented with different TS-to-graph transformations and compared their performance. Our contributions include: a) formulating the TSS as a node classification problem on graphs; b) conducting an extensive analysis of various TS- to-graph transformations applied to TSS using benchmark datasets from the TSSB repository; c) providing the first detailed study on utilizing GNNs for analyzing graph representations of TS in the context of TSS; d) demonstrating the effectiveness of our method, which achieves an average F1 score of 0.97 across 59 diverse TSS benchmark datasets; e) outperforming the seq2point baseline method by 0.05 in terms of F1 score; and f) reducing the required training data compared to the baseline methods.
MRM3: Machine Readable ML Model Metadata
May 19, 2025As the complexity and number of machine learning (ML) models grows, well-documented ML models are essential for developers and companies to use or adapt them to their specific use cases. Model metadata, already present in unstructured format as model cards in online repositories such as Hugging Face, could be more structured and machine readable while also incorporating environmental impact metrics such as energy consumption and carbon footprint. Our work extends the existing State of the Art by defining a structured schema for ML model metadata focusing on machine-readable format and support for integration into a knowledge graph (KG) for better organization and querying, enabling a wider set of use cases. Furthermore, we present an example wireless localization model metadata dataset consisting of 22 models trained on 4 datasets, integrated into a Neo4j-based KG with 113 nodes and 199 relations.
A Representation Learning Approach to Feature Drift Detection in Wireless Networks
May 15, 2025AI is foreseen to be a centerpiece in next generation wireless networks enabling enabling ubiquitous communication as well as new services. However, in real deployment, feature distribution changes may degrade the performance of AI models and lead to undesired behaviors. To counter for undetected model degradation, we propose ALERT; a method that can detect feature distribution changes and trigger model re-training that works well on two wireless network use cases: wireless fingerprinting and link anomaly detection. ALERT includes three components: representation learning, statistical testing and utility assessment. We rely on MLP for designing the representation learning component, on Kolmogorov-Smirnov and Population Stability Index tests for designing the statistical testing and a new function for utility assessment. We show the superiority of the proposed method against ten standard drift detection methods available in the literature on two wireless network use cases.
The Energy Cost of Artificial Intelligence of Things Lifecycle
Aug 01, 2024Artificial intelligence (AI)coupled with existing Internet of Things (IoT) enables more streamlined and autonomous operations across various economic sectors. Consequently, the paradigm of Artificial Intelligence of Things (AIoT) having AI techniques at its core implies additional energy and carbon costs that may become significant with more complex neural architectures. To better understand the energy and Carbon Footprint (CF) of some AIoT components, very recent studies employ conventional metrics. However, these metrics are not designed to capture energy efficiency aspects of inference. In this paper, we propose a new metric, the Energy Cost of AIoT Lifecycle (eCAL) to capture the overall energy cost of inference over the lifecycle of an AIoT system. We devise a new methodology for determining eCAL of an AIoT system by analyzing the complexity of data manipulation in individual components involved in the AIoT lifecycle and derive the overall and per bit energy consumption. With eCAL we show that the better a model is and the more it is used, the more energy efficient an inference is. For an example AIoT configuration, eCAL for making $100$ inferences is $1.43$ times higher than for $1000$ inferences. We also evaluate the CF of the AIoT system by calculating the equivalent CO$_{2}$ emissions based on the energy consumption and the Carbon Intensity (CI) across different countries. Using 2023 renewable data, our analysis reveals that deploying an AIoT system in Germany results in emitting $4.62$ times higher CO$_2$ than in Finland, due to latter using more low-CI energy sources.
RAG Enabled Conversations about Household Electricity Monitoring
Jun 03, 2024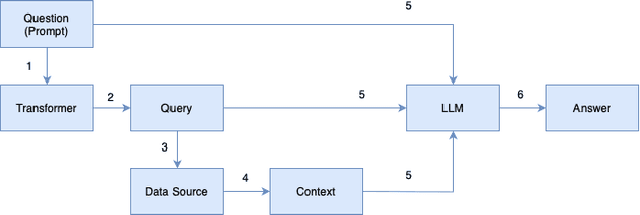
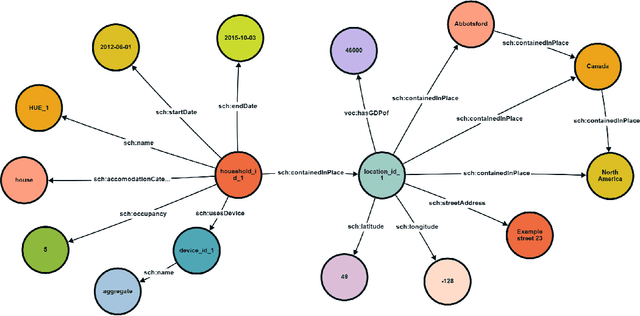


In this paper, we investigate the integration of Retrieval Augmented Generation (RAG) with large language models (LLMs) such as ChatGPT, Gemini, and Llama to enhance the accuracy and specificity of responses to complex questions about electricity datasets. Recognizing the limitations of LLMs in generating precise and contextually relevant answers due to their dependency on the patterns in training data rather than factual understanding, we propose a solution that leverages a specialized electricity knowledge graph. This approach facilitates the retrieval of accurate, real-time data which is then synthesized with the generative capabilities of LLMs. Our findings illustrate that the RAG approach not only reduces the incidence of incorrect information typically generated by LLMs but also significantly improves the quality of the output by grounding responses in verifiable data. This paper details our methodology, presents a comparative analysis of responses with and without RAG, and discusses the implications of our findings for future applications of AI in specialized sectors like energy data analysis.