 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sustainable Deep Learning for Multi-Label Classification on NILM
Jul 18, 2023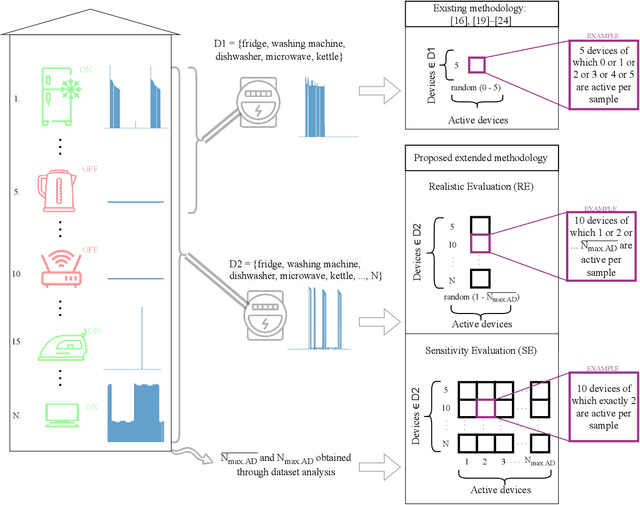
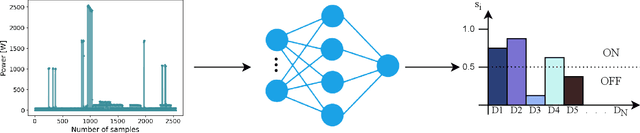
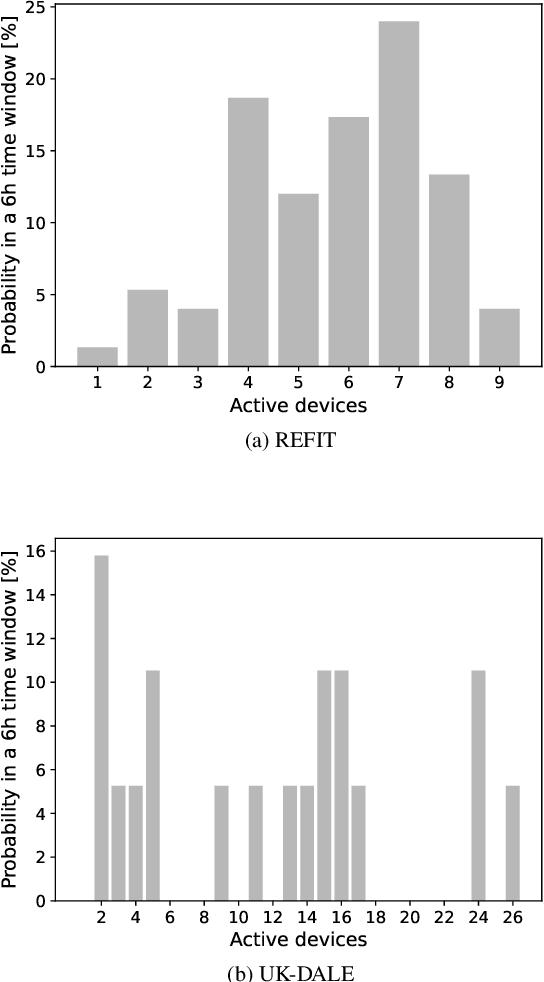
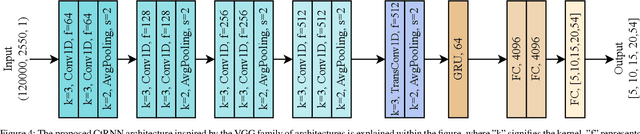
Non-intrusive load monitoring (NILM) is the process of obtaining appliance-level data from a single metering point, measuring total electricity consumption of a household or a business. Appliance-level data can be directly used for demand response applications and energy management systems as well as for awareness raising and motivation for improvements in energy efficiency and reduction in the carbon footprint. Recently, classical machine learning and deep learning (DL) techniques became very popular and proved as highly effective for NILM classification, but with the growing complexity these methods are faced with significant computational and energy demands during both their training and operation. In this paper, we introduce a novel DL model aimed at enhanced multi-label classification of NILM with improved computation and energy efficiency. We also propose a testing methodology for comparison of different models using data synthesized from the measurement datasets so as to better represent real-world scenarios. Compared to the state-of-the-art, the proposed model has its carbon footprint reduced by more than 23% while providing on average approximately 8 percentage points in performance improvement when testing on data derived from REFIT and UK-DALE datasets.
On Designing Data Models for Energy Feature Stores
May 09, 2022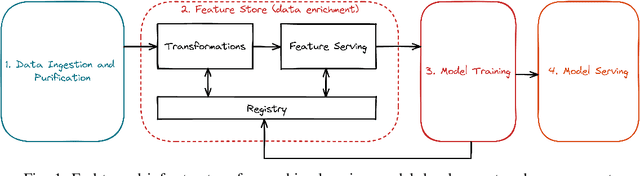
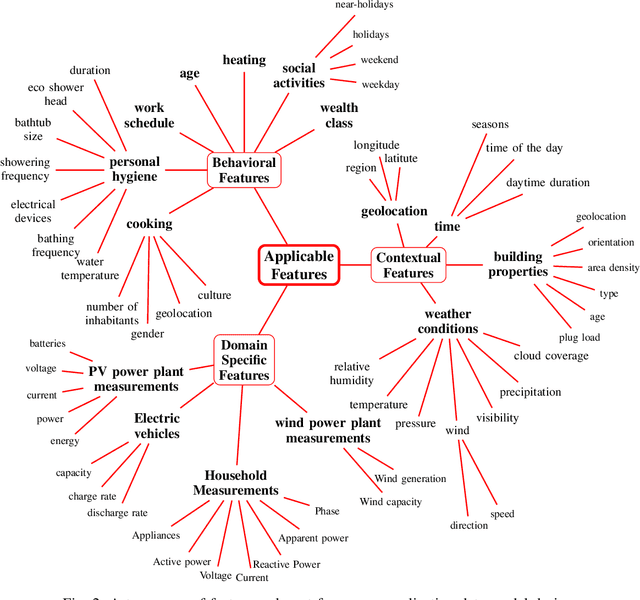
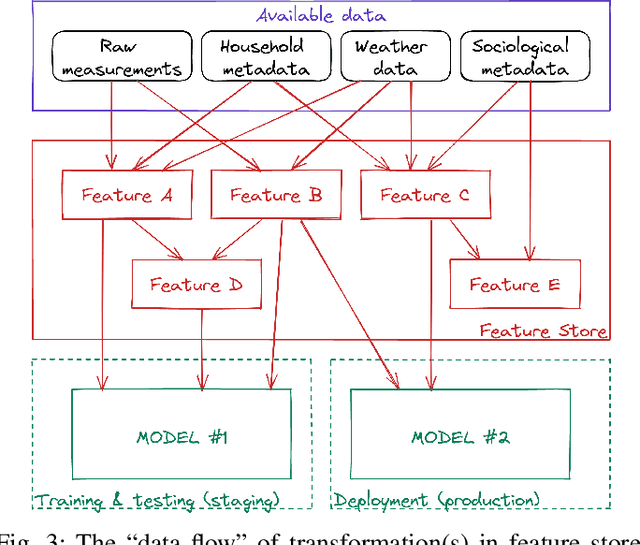

The digitization of the energy infrastructure enables new, data driven, applications often supported by machine learning models. However, domain specific data transformations, pre-processing and management in modern data driven pipelines is yet to be addressed. In this paper we perform a first time study on data models, energy feature engineering and feature management solutions for developing ML-based energy applications. We first propose a taxonomy for designing data models suitable for energy applications, analyze feature engineering techniques able to transform the data model into features suitable for ML model training and finally also analyze available designs for feature stores. Using a short-term forecasting dataset, we show the benefits of designing richer data models and engineering the features on the performance of the resulting models. Finally, we benchmark three complementary feature management solutions, including an open-source feature store.
Towards Sustainable Deep Learning for Wireless Fingerprinting Localization
Jan 22, 2022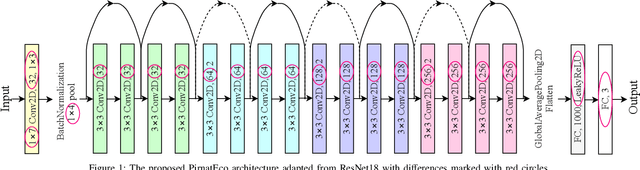
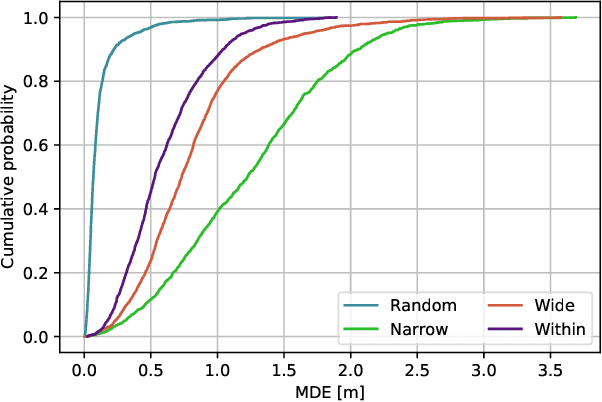
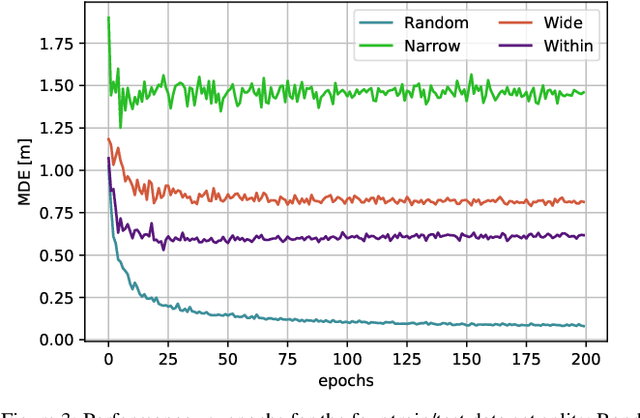
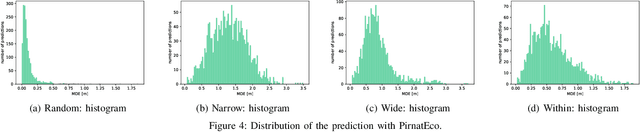
Location based services, already popular with end users, are now inevitably becoming part of new wireless infrastructures and emerging business processes. The increasingly popular Deep Learning (DL) artificial intelligence methods perform very well in wireless fingerprinting localization based on extensive indoor radio measurement data. However, with the increasing complexity these methods become computationally very intensive and energy hungry, both for their training and subsequent operation. Considering only mobile users, estimated to exceed 7.4billion by the end of 2025, and assuming that the networks serving these users will need to perform only one localization per user per hour on average, the machine learning models used for the calculation would need to perform 65*10^12 predictions per year. Add to this equation tens of billions of other connected devices and applications that rely heavily on more frequent location updates, and it becomes apparent that localization will contribute significantly to carbon emissions unless more energy-efficient models are developed and used. This motivated our work on a new DL-based architecture for indoor localization that is more energy efficient compared to related state-of-the-art approaches while showing only marginal performance degradation. A detailed performance evaluation shows that the proposed model producesonly 58 % of the carbon footprint while maintaining 98.7 % of the overall performance compared to state of the art model external to our group. Additionally, we elaborate on a methodology to calculate the complexity of the DL model and thus the CO2 footprint during its training and operation.