 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoodSEM: Large Language Model Specialized in Food Named-Entity Linking
Sep 26, 2025This paper introduces FoodSEM, a state-of-the-art fine-tuned open-source large language model (LLM) for named-entity linking (NEL) to food-related ontologies. To the best of our knowledge, food NEL is a task that cannot be accurately solved by state-of-the-art general-purpose (large) language models or custom domain-specific models/systems. Through an instruction-response (IR) scenario, FoodSEM links food-related entities mentioned in a text to several ontologies, including FoodOn, SNOMED-CT, and the Hansard taxonomy. The FoodSEM model achieves state-of-the-art performance compared to related models/systems, with F1 scores even reaching 98% on some ontologies and datasets. The presented comparative analyses against zero-shot, one-shot, and few-shot LLM prompting baselines further highlight FoodSEM's superior performance over its non-fine-tuned version. By making FoodSEM and its related resources publicly available, the main contributions of this article include (1) publishing a food-annotated corpora into an IR format suitable for LLM fine-tuning/evaluation, (2) publishing a robust model to advance the semantic understanding of text in the food domain, and (3) providing a strong baseline on food NEL for future benchmarking.
ClustOpt: A Clustering-based Approach for Representing and Visualizing the Search Dynamics of Numerical Metaheuristic Optimization Algorithms
Jul 03, 2025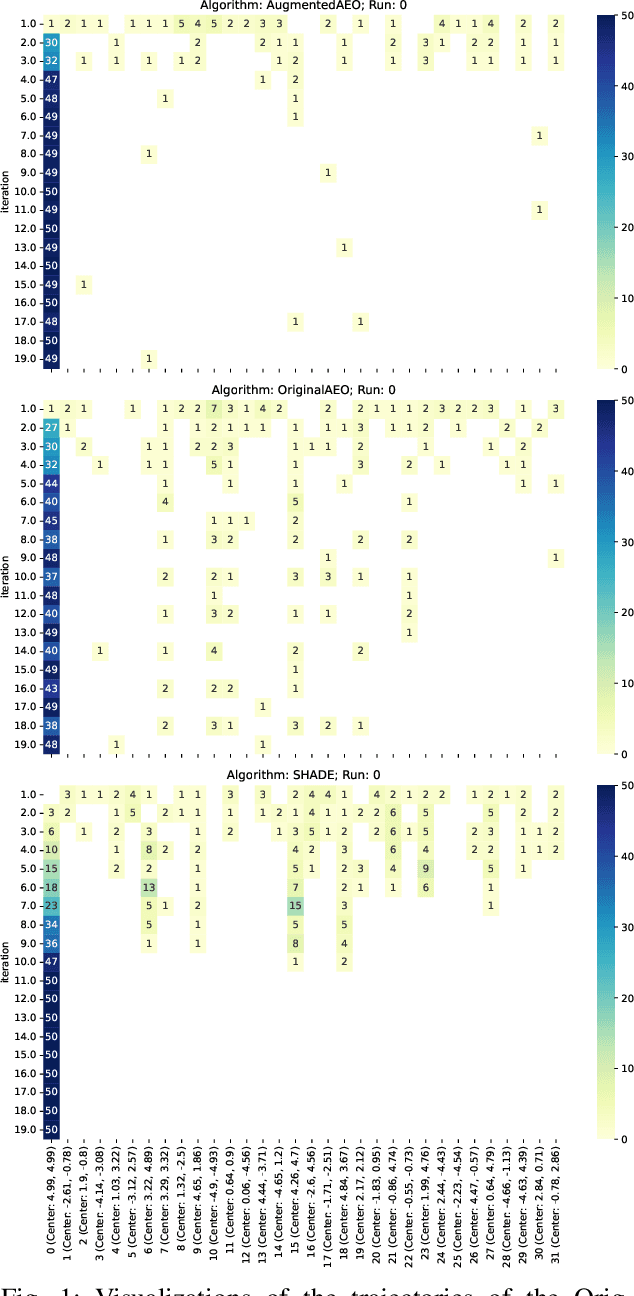
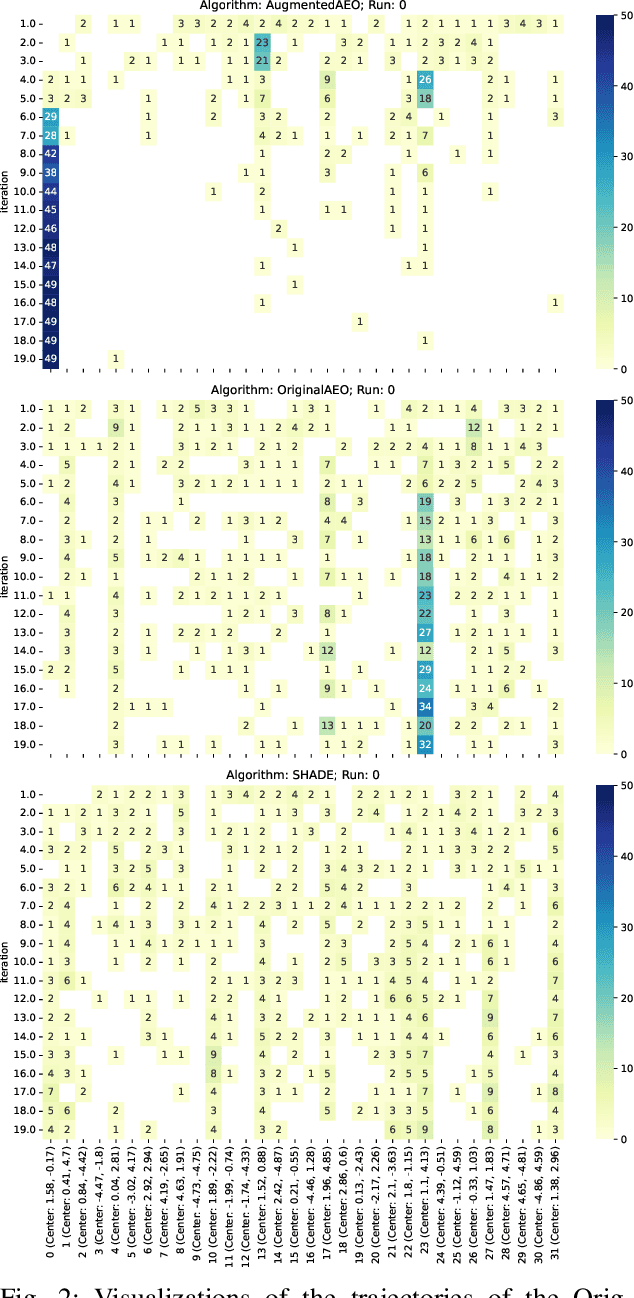
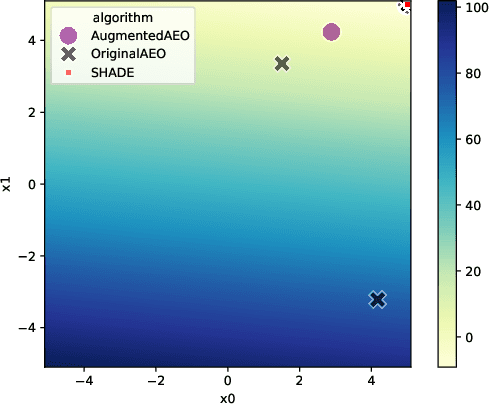
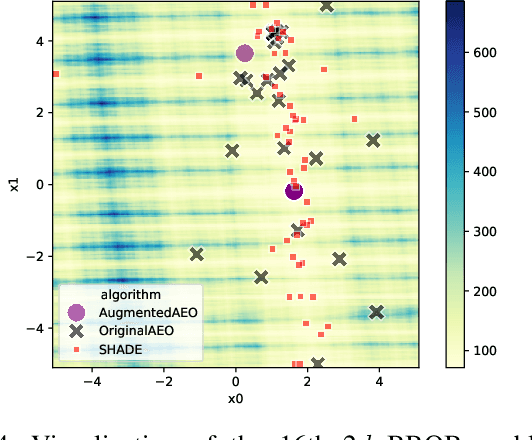
Understanding the behavior of numerical metaheuristic optimization algorithms is critical for advancing their development and application. Traditional visualization techniques, such as convergence plots, trajectory mapping, and fitness landscape analysis, often fall short in illustrating the structural dynamics of the search process, especially in high-dimensional or complex solution spaces. To address this, we propose a novel representation and visualization methodology that clusters solution candidates explored by the algorithm and tracks the evolution of cluster memberships across iterations, offering a dynamic and interpretable view of the search process. Additionally, we introduce two metrics - algorithm stability and algorithm similarity- to quantify the consistency of search trajectories across runs of an individual algorithm and the similarity between different algorithms, respectively. We apply this methodology to a set of ten numerical metaheuristic algorithms, revealing insights into their stability and comparative behaviors, thereby providing a deeper understanding of their search dynamics.
Comparing Optimization Algorithms Through the Lens of Search Behavior Analysis
Jul 02, 2025The field of numerical optimization has recently seen a surge in the development of "novel" metaheuristic algorithms, inspired by metaphors derived from natural or human-made processes, which have been widely criticized for obscuring meaningful innovations and failing to distinguish themselves from existing approaches. Aiming to address these concerns, we investigate the applicability of statistical tests for comparing algorithms based on their search behavior. We utilize the cross-match statistical test to compare multivariate distributions and assess the solutions produced by 114 algorithms from the MEALPY library. These findings are incorporated into an empirical analysis aiming to identify algorithms with similar search behaviors.
The Pitfalls of Benchmarking in Algorithm Selection: What We Are Getting Wrong
May 12, 2025Algorithm selection, aiming to identify the best algorithm for a given problem, plays a pivotal role in continuous black-box optimization. A common approach involves representing optimization functions using a set of features, which are then used to train a machine learning meta-model for selecting suitable algorithms. Various approaches have demonstrated the effectiveness of these algorithm selection meta-models. However, not all evaluation approaches are equally valid for assessing the performance of meta-models. We highlight methodological issues that frequently occur in the community and should be addressed when evaluating algorithm selection approaches. First, we identify flaws with the "leave-instance-out" evaluation technique. We show that non-informative features and meta-models can achieve high accuracy, which should not be the case with a well-designed evaluation framework. Second, we demonstrate that measuring the performance of optimization algorithms with metrics sensitive to the scale of the objective function requires careful consideration of how this impacts the construction of the meta-model, its predictions, and the model's error. Such metrics can falsely present overly optimistic performance assessments of the meta-models. This paper emphasizes the importance of careful evaluation, as loosely defined methodologies can mislead researchers, divert efforts, and introduce noise into the field
Landscape Features in Single-Objective Continuous Optimization: Have We Hit a Wall in Algorithm Selection Generalization?
Jan 29, 2025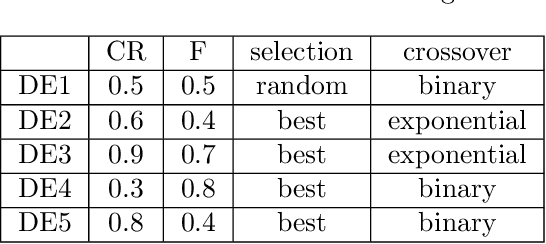
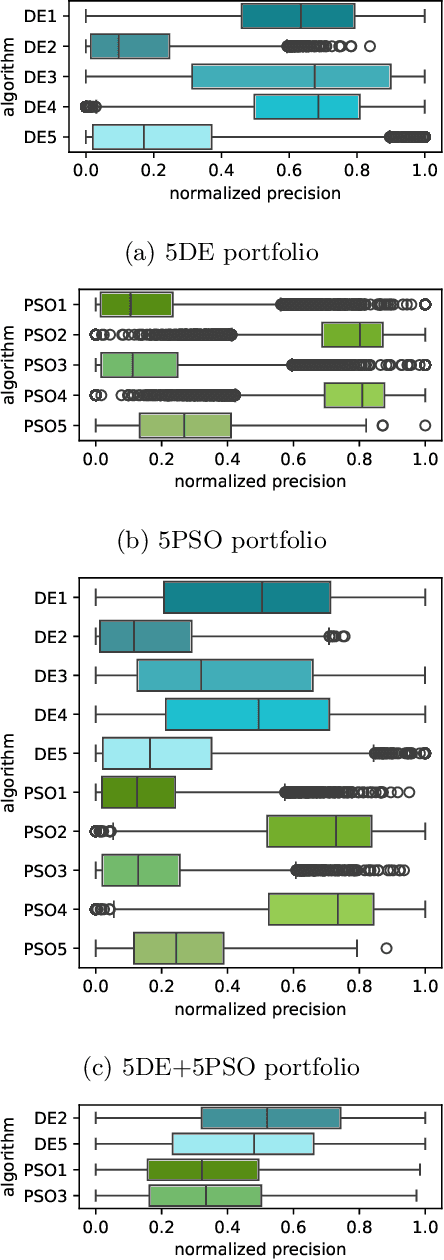
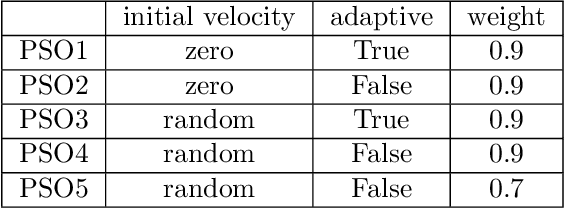
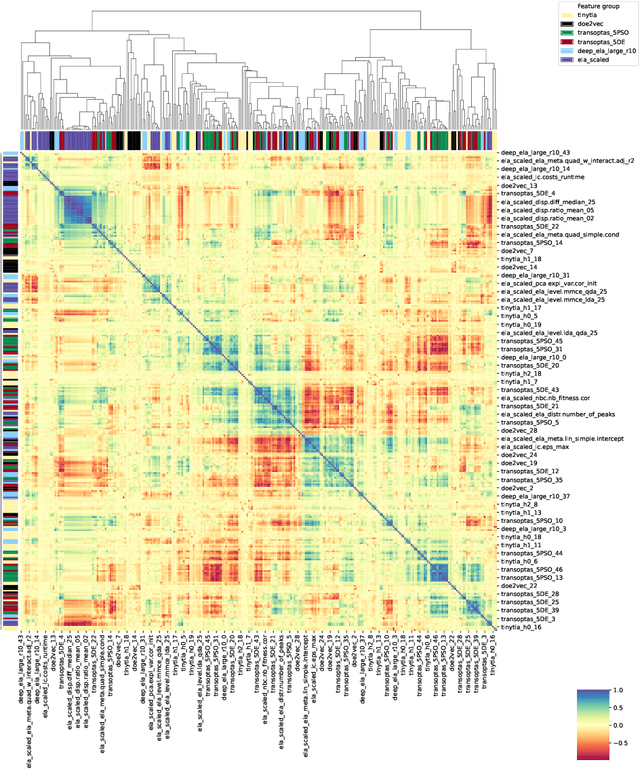
%% Text of abstract The process of identifying the most suitable optimization algorithm for a specific problem, referred to as algorithm selection (AS), entails training models that leverage problem landscape features to forecast algorithm performance. A significant challenge in this domain is ensuring that AS models can generalize effectively to novel, unseen problems. This study evaluates the generalizability of AS models based on different problem representations in the context of single-objective continuous optimization. In particular, it considers the most widely used Exploratory Landscape Analysis features, as well as recently proposed Topological Landscape Analysis features, and features based on deep learning, such as DeepELA, TransOptAS and Doe2Vec. Our results indicate that when presented with out-of-distribution evaluation data, none of the feature-based AS models outperform a simple baseline model, i.e., a Single Best Solver.
Instance Selection for Dynamic Algorithm Configuration with Reinforcement Learning: Improving Generalization
Jul 18, 2024Dynamic Algorithm Configuration (DAC) addresses the challenge of dynamically setting hyperparameters of an algorithm for a diverse set of instances rather than focusing solely on individual tasks. Agents trained with Deep Reinforcement Learning (RL) offer a pathway to solve such settings. However, the limited generalization performance of these agents has significantly hindered the application in DAC. Our hypothesis is that a potential bias in the training instances limits generalization capabilities. We take a step towards mitigating this by selecting a representative subset of training instances to overcome overrepresentation and then retraining the agent on this subset to improve its generalization performance. For constructing the meta-features for the subset selection, we particularly account for the dynamic nature of the RL agent by computing time series features on trajectories of actions and rewards generated by the agent's interaction with the environment. Through empirical evaluations on the Sigmoid and CMA-ES benchmarks from the standard benchmark library for DAC, called DACBench, we discuss the potentials of our selection technique compared to training on the entire instance set. Our results highlight the efficacy of instance selection in refining DAC policies for diverse instance spaces.
A Survey of Meta-features Used for Automated Selection of Algorithms for Black-box Single-objective Continuous Optimization
Jun 08, 2024
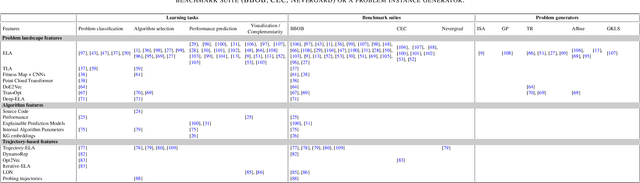
The selection of the most appropriate algorithm to solve a given problem instance, known as algorithm selection, is driven by the potential to capitalize on the complementary performance of different algorithms across sets of problem instances. However, determining the optimal algorithm for an unseen problem instance has been shown to be a challenging task, which has garnered significant attention from researchers in recent years. In this survey, we conduct an overview of the key contributions to algorithm selection in the field of single-objective continuous black-box optimization. We present ongoing work in representation learning of meta-features for optimization problem instances, algorithm instances, and their interactions. We also study machine learning models for automated algorithm selection, configuration, and performance prediction. Through this analysis, we identify gaps in the state of the art, based on which we present ideas for further development of meta-feature representations.
Generalization Ability of Feature-based Performance Prediction Models: A Statistical Analysis across Benchmarks
May 20, 2024



This study examines the generalization ability of algorithm performance prediction models across various benchmark suites. Comparing the statistical similarity between the problem collections with the accuracy of performance prediction models that are based on exploratory landscape analysis features, we observe that there is a positive correlation between these two measures. Specifically, when the high-dimensional feature value distributions between training and testing suites lack statistical significance, the model tends to generalize well, in the sense that the testing errors are in the same range as the training errors. Two experiments validate these findings: one involving the standard benchmark suites, the BBOB and CEC collections, and another using five collections of affine combinations of BBOB problem instances.
TransOpt: Transformer-based Representation Learning for Optimization Problem Classification
Nov 29, 2023We propose a representation of optimization problem instances using a transformer-based neural network architecture trained for the task of problem classification of the 24 problem classes from the Black-box Optimization Benchmarking (BBOB) benchmark. We show that transformer-based methods can be trained to recognize problem classes with accuracies in the range of 70\%-80\% for different problem dimensions, suggesting the possible application of transformer architectures in acquiring representations for black-box optimization problems.
PS-AAS: Portfolio Selection for Automated Algorithm Selection in Black-Box Optimization
Oct 14, 2023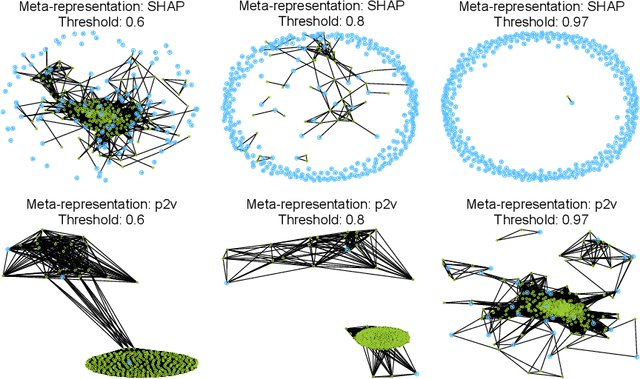
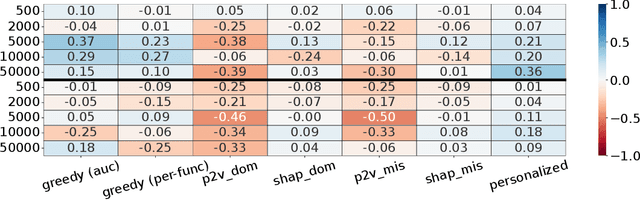
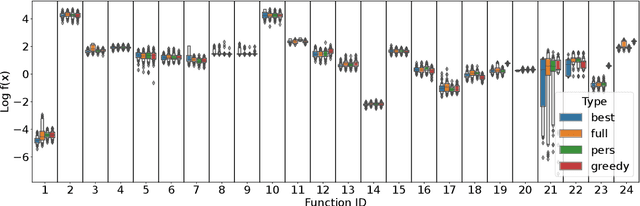
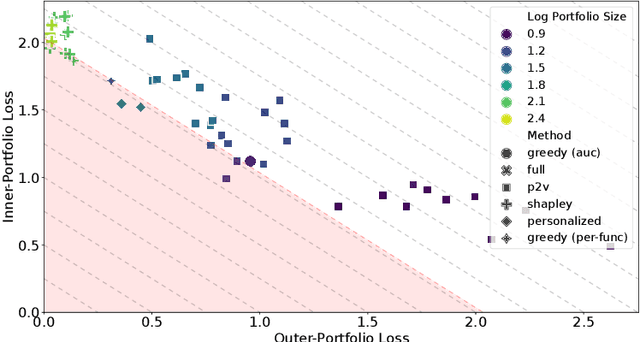
The performance of automated algorithm selection (AAS) strongly depends on the portfolio of algorithms to choose from. Selecting the portfolio is a non-trivial task that requires balancing the trade-off between the higher flexibility of large portfolios with the increased complexity of the AAS task. In practice, probably the most common way to choose the algorithms for the portfolio is a greedy selection of the algorithms that perform well in some reference tasks of interest. We set out in this work to investigate alternative, data-driven portfolio selection techniques. Our proposed method creates algorithm behavior meta-representations, constructs a graph from a set of algorithms based on their meta-representation similarity, and applies a graph algorithm to select a final portfolio of diverse, representative, and non-redundant algorithms. We evaluate two distinct meta-representation techniques (SHAP and performance2vec) for selecting complementary portfolios from a total of 324 different variants of CMA-ES for the task of optimizing the BBOB single-objective problems in dimensionalities 5 and 30 with different cut-off budgets. We test two types of portfolios: one related to overall algorithm behavior and the `personalized' one (related to algorithm behavior per each problem separately). We observe that the approach built on the performance2vec-based representations favors small portfolios with negligible error in the AAS task relative to the virtual best solver from the selected portfolio, whereas the portfolios built from the SHAP-based representations gain from higher flexibility at the cost of decreased performance of the AAS. Across most considered scenarios, personalized portfolios yield comparable or slightly better performance than the classical greedy approach. They outperform the full portfolio in all scenarios.