 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Individual and Joint Module Impact in Modular Optimization Frameworks
May 20, 2024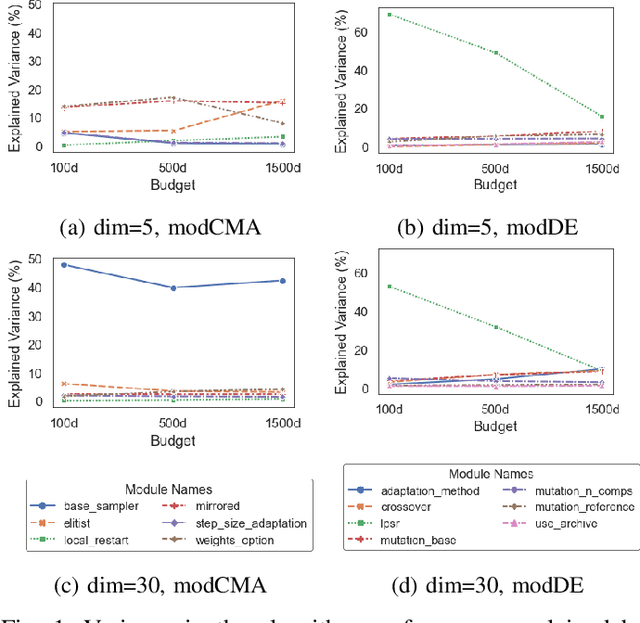



This study explores the influence of modules on the performance of modular optimization frameworks for continuous single-objective black-box optimization. There is an extensive variety of modules to choose from when designing algorithm variants, however, there is a rather limited understanding of how each module individually influences the algorithm performance and how the modules interact with each other when combined. We use the functional ANOVA (f-ANOVA) framework to quantify the influence of individual modules and module combinations for two algorithms, the modular Covariance Matrix Adaptation (modCMA) and the modular Differential Evolution (modDE). We analyze the performance data from 324 modCMA and 576 modDE variants on the BBOB benchmark collection, for two problem dimensions, and three computational budgets. Noteworthy findings include the identification of important modules that strongly influence the performance of modCMA, such as the~\textit{weights\ option} and~\textit{mirrored} modules for low dimensional problems, and the~\textit{base\ sampler} for high dimensional problems. The large individual influence of the~\textit{lpsr} module makes it very important for the performance of modDE, regardless of the problem dimensionality and the computational budget. When comparing modCMA and modDE, modDE undergoes a shift from individual modules being more influential, to module combinations being more influential, while modCMA follows the opposite pattern, with an increase in problem dimensionality and computational budget.
Generalization Ability of Feature-based Performance Prediction Models: A Statistical Analysis across Benchmarks
May 20, 2024



This study examines the generalization ability of algorithm performance prediction models across various benchmark suites. Comparing the statistical similarity between the problem collections with the accuracy of performance prediction models that are based on exploratory landscape analysis features, we observe that there is a positive correlation between these two measures. Specifically, when the high-dimensional feature value distributions between training and testing suites lack statistical significance, the model tends to generalize well, in the sense that the testing errors are in the same range as the training errors. Two experiments validate these findings: one involving the standard benchmark suites, the BBOB and CEC collections, and another using five collections of affine combinations of BBOB problem instances.
PS-AAS: Portfolio Selection for Automated Algorithm Selection in Black-Box Optimization
Oct 14, 2023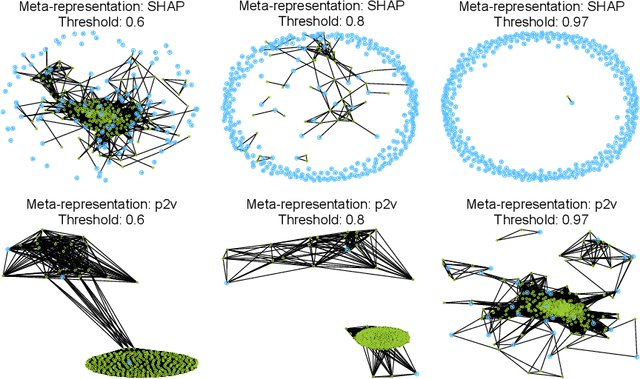
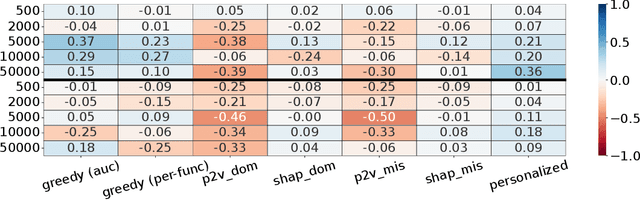
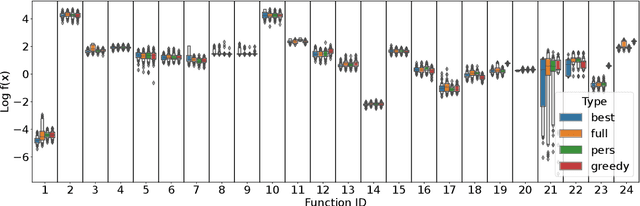
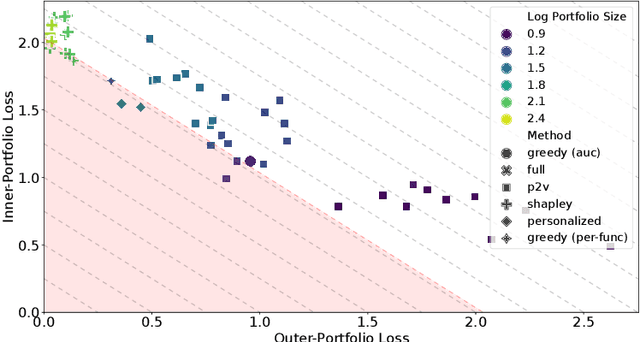
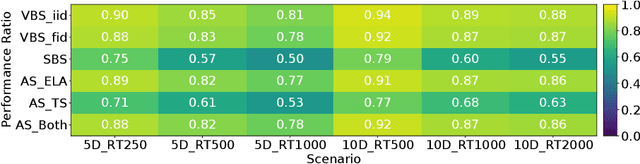
The performance of automated algorithm selection (AAS) strongly depends on the portfolio of algorithms to choose from. Selecting the portfolio is a non-trivial task that requires balancing the trade-off between the higher flexibility of large portfolios with the increased complexity of the AAS task. In practice, probably the most common way to choose the algorithms for the portfolio is a greedy selection of the algorithms that perform well in some reference tasks of interest. We set out in this work to investigate alternative, data-driven portfolio selection techniques. Our proposed method creates algorithm behavior meta-representations, constructs a graph from a set of algorithms based on their meta-representation similarity, and applies a graph algorithm to select a final portfolio of diverse, representative, and non-redundant algorithms. We evaluate two distinct meta-representation techniques (SHAP and performance2vec) for selecting complementary portfolios from a total of 324 different variants of CMA-ES for the task of optimizing the BBOB single-objective problems in dimensionalities 5 and 30 with different cut-off budgets. We test two types of portfolios: one related to overall algorithm behavior and the `personalized' one (related to algorithm behavior per each problem separately). We observe that the approach built on the performance2vec-based representations favors small portfolios with negligible error in the AAS task relative to the virtual best solver from the selected portfolio, whereas the portfolios built from the SHAP-based representations gain from higher flexibility at the cost of decreased performance of the AAS. Across most considered scenarios, personalized portfolios yield comparable or slightly better performance than the classical greedy approach. They outperform the full portfolio in all scenarios.
Comparing Algorithm Selection Approaches on Black-Box Optimization Problems
Jun 30, 2023

Performance complementarity of solvers available to tackle black-box optimization problems gives rise to the important task of algorithm selection (AS). Automated AS approaches can help replace tedious and labor-intensive manual selection, and have already shown promising performance in various optimization domains. Automated AS relies on machine learning (ML) techniques to recommend the best algorithm given the information about the problem instance. Unfortunately, there are no clear guidelines for choosing the most appropriate one from a variety of ML techniques. Tree-based models such as Random Forest or XGBoost have consistently demonstrated outstanding performance for automated AS. Transformers and other tabular deep learning models have also been increasingly applied in this context. We investigate in this work the impact of the choice of the ML technique on AS performance. We compare four ML models on the task of predicting the best solver for the BBOB problems for 7 different runtime budgets in 2 dimensions. While our results confirm that a per-instance AS has indeed impressive potential, we also show that the particular choice of the ML technique is of much minor importance.
Using Knowledge Graphs for Performance Prediction of Modular Optimization Algorithms
Jan 24, 2023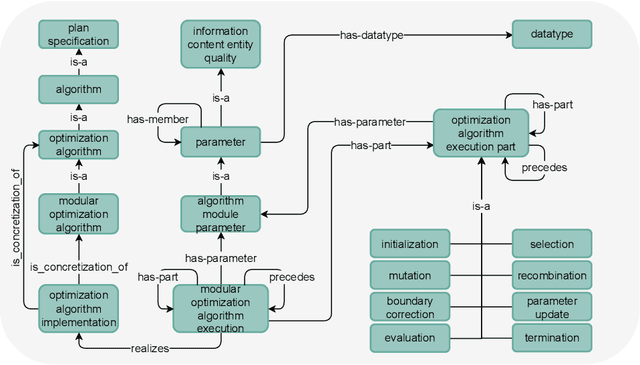
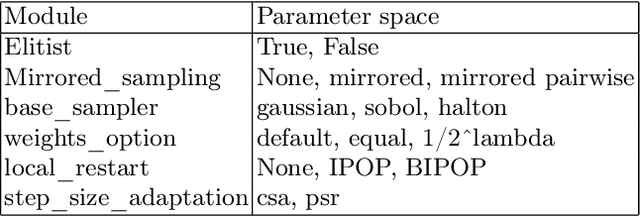
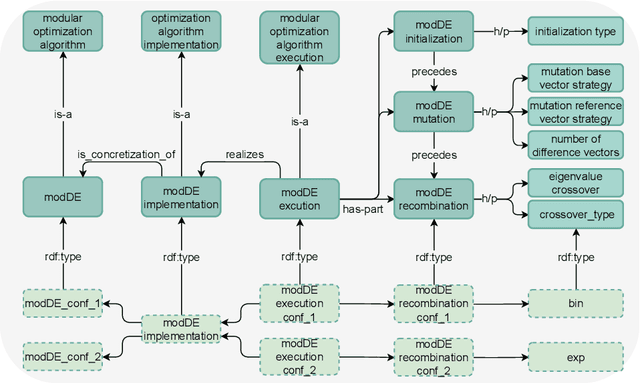

Empirical data plays an important role in evolutionary computation research. To make better use of the available data, ontologies have been proposed in the literature to organize their storage in a structured way. However, the full potential of these formal methods to capture our domain knowledge has yet to be demonstrated. In this work, we evaluate a performance prediction model built on top of the extension of the recently proposed OPTION ontology. More specifically, we first extend the OPTION ontology with the vocabulary needed to represent modular black-box optimization algorithms. Then, we use the extended OPTION ontology, to create knowledge graphs with fixed-budget performance data for two modular algorithm frameworks, modCMA, and modDE, for the 24 noiseless BBOB benchmark functions. We build the performance prediction model using a knowledge graph embedding-based methodology. Using a number of different evaluation scenarios, we show that a triple classification approach, a fairly standard predictive modeling task in the context of knowledge graphs, can correctly predict whether a given algorithm instance will be able to achieve a certain target precision for a given problem instance. This approach requires feature representation of algorithms and problems. While the latter is already well developed, we hope that our work will motivate the community to collaborate on appropriate algorithm representations.
FAIRification of MLC data
Nov 23, 2022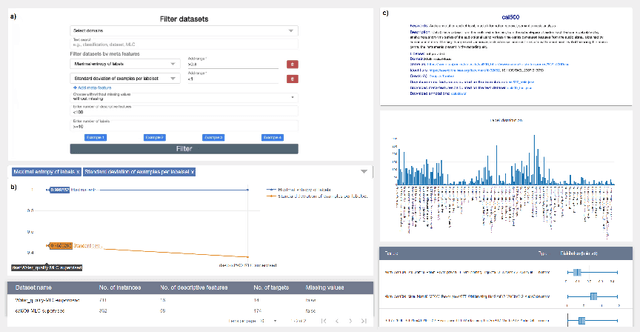
The multi-label classification (MLC) task has increasingly been receiving interest from the machine learning (ML) community, as evidenced by the growing number of papers and methods that appear in the literature. Hence, ensuring proper, correct, robust, and trustworthy benchmarking is of utmost importance for the further development of the field. We believe that this can be achieved by adhering to the recently emerged data management standards, such as the FAIR (Findable, Accessible, Interoperable, and Reusable) and TRUST (Transparency, Responsibility, User focus, Sustainability, and Technology) principles. To FAIRify the MLC datasets, we introduce an ontology-based online catalogue of MLC datasets that follow these principles. The catalogue extensively describes many MLC datasets with comprehensible meta-features, MLC-specific semantic descriptions, and different data provenance information. The MLC data catalogue is extensively described in our recent publication in Nature Scientific Reports, Kostovska & Bogatinovski et al., and available at: http://semantichub.ijs.si/MLCdatasets. In addition, we provide an ontology-based system for easy access and querying of performance/benchmark data obtained from a comprehensive MLC benchmark study. The system is available at: http://semantichub.ijs.si/MLCbenchmark.
OPTION: OPTImization Algorithm Benchmarking ONtology
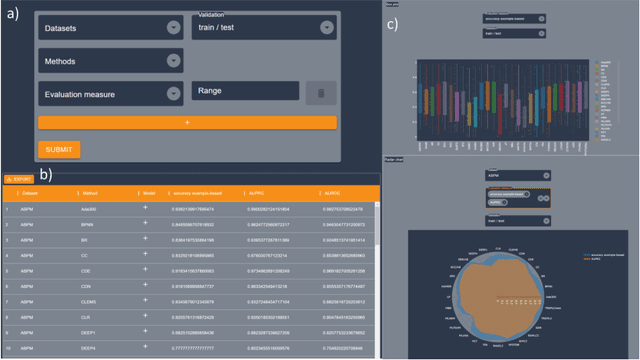
Nov 21, 2022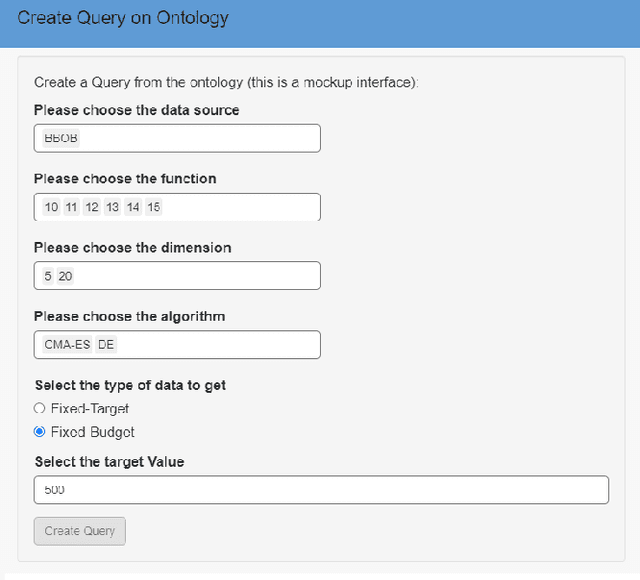
Many optimization algorithm benchmarking platforms allow users to share their experimental data to promote reproducible and reusable research. However, different platforms use different data models and formats, which drastically complicates the identification of relevant datasets, their interpretation, and their interoperability. Therefore, a semantically rich, ontology-based, machine-readable data model that can be used by different platforms is highly desirable. In this paper, we report on the development of such an ontology, which we call OPTION (OPTImization algorithm benchmarking ONtology). Our ontology provides the vocabulary needed for semantic annotation of the core entities involved in the benchmarking process, such as algorithms, problems, and evaluation measures. It also provides means for automatic data integration, improved interoperability, and powerful querying capabilities, thereby increasing the value of the benchmarking data. We demonstrate the utility of OPTION, by annotating and querying a corpus of benchmark performance data from the BBOB collection of the COCO framework and from the Yet Another Black-Box Optimization Benchmark (YABBOB) family of the Nevergrad environment. In addition, we integrate features of the BBOB functional performance landscape into the OPTION knowledge base using publicly available datasets with exploratory landscape analysis. Finally, we integrate the OPTION knowledge base into the IOHprofiler environment and provide users with the ability to perform meta-analysis of performance data.
Explainable Model-specific Algorithm Selection for Multi-Label Classification
Nov 21, 2022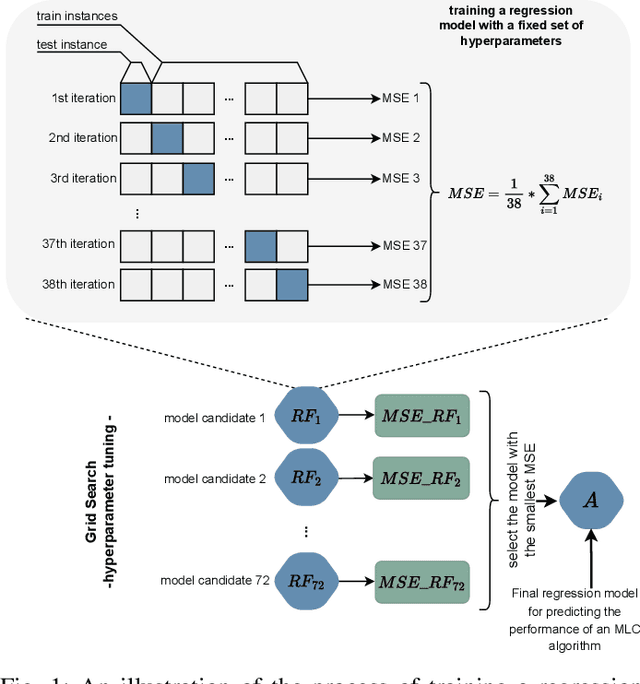
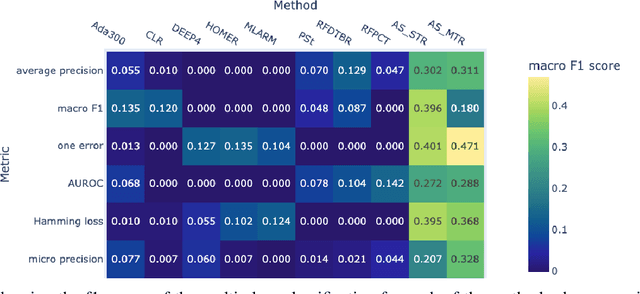
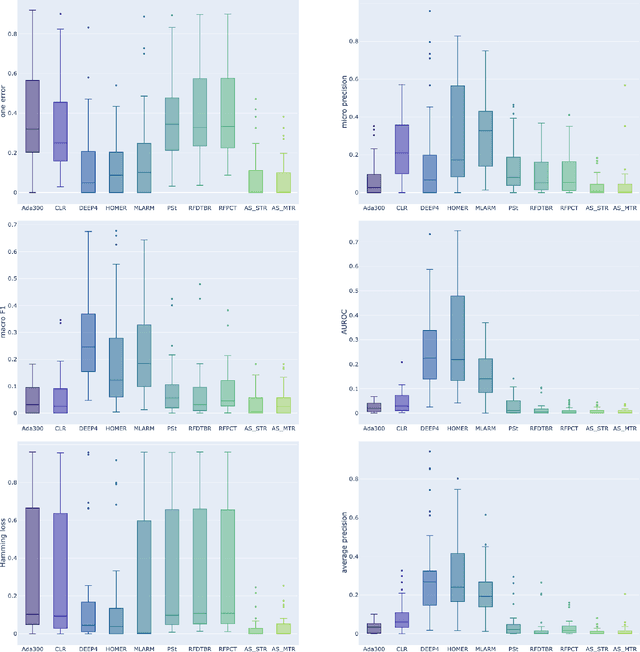
Multi-label classification (MLC) is an ML task of predictive modeling in which a data instance can simultaneously belong to multiple classes. MLC is increasingly gaining interest in different application domains such as text mining, computer vision, and bioinformatics. Several MLC algorithms have been proposed in the literature, resulting in a meta-optimization problem that the user needs to address: which MLC approach to select for a given dataset? To address this algorithm selection problem, we investigate in this work the quality of an automated approach that uses characteristics of the datasets - so-called features - and a trained algorithm selector to choose which algorithm to apply for a given task. For our empirical evaluation, we use a portfolio of 38 datasets. We consider eight MLC algorithms, whose quality we evaluate using six different performance metrics. We show that our automated algorithm selector outperforms any of the single MLC algorithms, and this is for all evaluated performance measures. Our selection approach is explainable, a characteristic that we exploit to investigate which meta-features have the largest influence on the decisions made by the algorithm selector. Finally, we also quantify the importance of the most significant meta-features for various domains.
Discover the Mysteries of the Maya: Selected Contributions from the Machine Learning Challenge & The Discovery Challenge Workshop at ECML PKDD 2021
Aug 09, 2022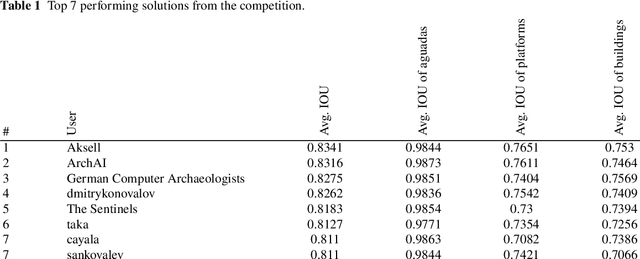
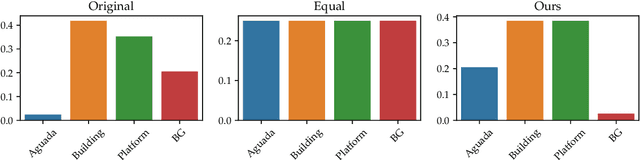


The volume contains selected contributions from the Machine Learning Challenge "Discover the Mysteries of the Maya", presented at the Discovery Challenge Track of The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD 2021). Remote sensing has greatly accelerated traditional archaeological landscape surveys in the forested regions of the ancient Maya. Typical exploration and discovery attempts, beside focusing on whole ancient cities, focus also on individual buildings and structures. Recently, there have been several successful attempts of utilizing machine learning for identifying ancient Maya settlements. These attempts, while relevant, focus on narrow areas and rely on high-quality aerial laser scanning (ALS) data which covers only a fraction of the region where ancient Maya were once settled. Satellite image data, on the other hand, produced by the European Space Agency's (ESA) Sentinel missions, is abundant and, more importantly, publicly available. The "Discover the Mysteries of the Maya" challenge aimed at locating and identifying ancient Maya architectures (buildings, aguadas, and platforms) by performing integrated image segmentation of different types of satellite imagery (from Sentinel-1 and Sentinel-2) data and ALS (lidar) data.
Per-run Algorithm Selection with Warm-starting using Trajectory-based Features
Apr 20, 2022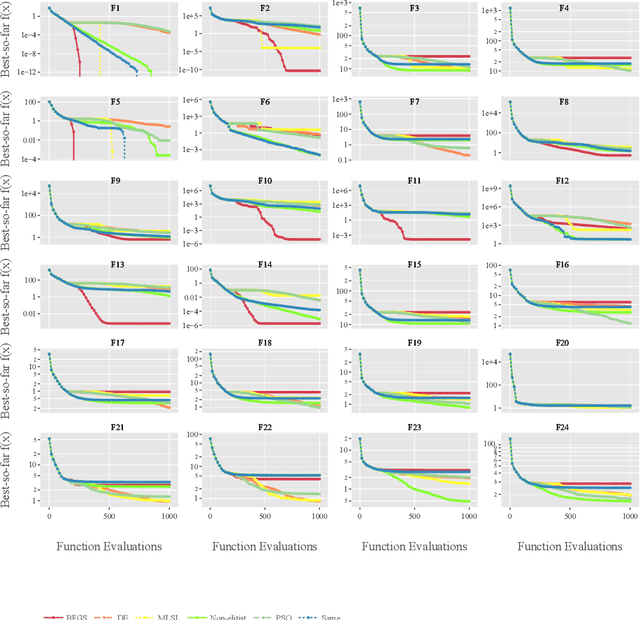


Per-instance algorithm selection seeks to recommend, for a given problem instance and a given performance criterion, one or several suitable algorithms that are expected to perform well for the particular setting. The selection is classically done offline, using openly available information about the problem instance or features that are extracted from the instance during a dedicated feature extraction step. This ignores valuable information that the algorithms accumulate during the optimization process. In this work, we propose an alternative, online algorithm selection scheme which we coin per-run algorithm selection. In our approach, we start the optimization with a default algorithm, and, after a certain number of iterations, extract instance features from the observed trajectory of this initial optimizer to determine whether to switch to another optimizer. We test this approach using the CMA-ES as the default solver, and a portfolio of six different optimizers as potential algorithms to switch to. In contrast to other recent work on online per-run algorithm selection, we warm-start the second optimizer using information accumulated during the first optimization phase. We show that our approach outperforms static per-instance algorithm selection. We also compare two different feature extraction principles, based on exploratory landscape analysis and time series analysis of the internal state variables of the CMA-ES, respectively. We show that a combination of both feature sets provides the most accurate recommendations for our test cases, taken from the BBOB function suite from the COCO platform and the YABBOB suite from the Nevergrad platform.