 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPLE: Multi-Path Adaptive Propagation with Level-Aware Embeddings for Hierarchical Multi-Label Image Classification
Mar 31, 2026Hierarchical multi-label classification (HMLC) is essential for modeling structured label dependencies in remote sensing. Yet existing approaches struggle in multi-path settings, where images may activate multiple taxonomic branches, leading to underuse of hierarchical information. We propose MAPLE (Multi-Path Adaptive Propagation with Level-Aware Embeddings), a framework that integrates (i) hierarchical semantic initialization from graph-aware textual descriptions, (ii) graph-based structure encoding via graph convolutional networks (GCNs), and (iii) adaptive multi-modal fusion that dynamically balances semantic priors and visual evidence. An adaptive level-aware objective automatically selects appropriate losses per hierarchy level. Evaluations on CORINE-aligned remote sensing datasets (AID, DFC-15, and MLRSNet) show consistent improvements of up to +42% in few-shot regimes while adding only 2.6% parameter overhead, demonstrating that MAPLE effectively and efficiently models hierarchical semantics for Earth observation (EO).
HELM: Hierarchical and Explicit Label Modeling with Graph Learning for Multi-Label Image Classification
Mar 12, 2026Hierarchical multi-label classification (HMLC) is essential for modeling complex label dependencies in remote sensing. Existing methods, however, struggle with multi-path hierarchies where instances belong to multiple branches, and they rarely exploit unlabeled data. We introduce HELM (\textit{Hierarchical and Explicit Label Modeling}), a novel framework that overcomes these limitations. HELM: (i) uses hierarchy-specific class tokens within a Vision Transformer to capture nuanced label interactions; (ii) employs graph convolutional networks to explicitly encode the hierarchical structure and generate hierarchy-aware embeddings; and (iii) integrates a self-supervised branch to effectively leverage unlabeled imagery. We perform a comprehensive evaluation on four remote sensing image (RSI) datasets (UCM, AID, DFC-15, MLRSNet). HELM achieves state-of-the-art performance, consistently outperforming strong baselines in both supervised and semi-supervised settings, demonstrating particular strength in low-label scenarios.
In-Domain Self-Supervised Learning Can Lead to Improvements in Remote Sensing Image Classification
Jul 04, 2023


Self-supervised learning (SSL) has emerged as a promising approach for remote sensing image classification due to its ability to leverage large amounts of unlabeled data. In contrast to traditional supervised learning, SSL aims to learn representations of data without the need for explicit labels. This is achieved by formulating auxiliary tasks that can be used to create pseudo-labels for the unlabeled data and learn pre-trained models. The pre-trained models can then be fine-tuned on downstream tasks such as remote sensing image scene classification. The paper analyzes the effectiveness of SSL pre-training using Million AID - a large unlabeled remote sensing dataset on various remote sensing image scene classification datasets as downstream tasks. More specifically, we evaluate the effectiveness of SSL pre-training using the iBOT framework coupled with Vision transformers (ViT) in contrast to supervised pre-training of ViT using the ImageNet dataset. The comprehensive experimental work across 14 datasets with diverse properties reveals that in-domain SSL leads to improved predictive performance of models compared to the supervised counterparts.
FAIRification of MLC data
Nov 23, 2022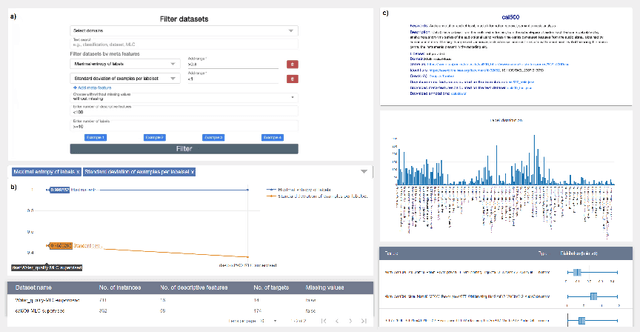
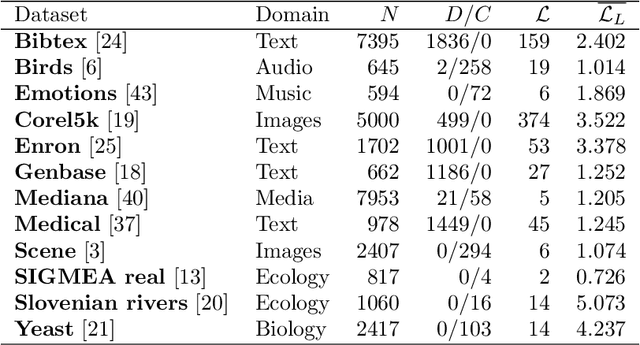
The multi-label classification (MLC) task has increasingly been receiving interest from the machine learning (ML) community, as evidenced by the growing number of papers and methods that appear in the literature. Hence, ensuring proper, correct, robust, and trustworthy benchmarking is of utmost importance for the further development of the field. We believe that this can be achieved by adhering to the recently emerged data management standards, such as the FAIR (Findable, Accessible, Interoperable, and Reusable) and TRUST (Transparency, Responsibility, User focus, Sustainability, and Technology) principles. To FAIRify the MLC datasets, we introduce an ontology-based online catalogue of MLC datasets that follow these principles. The catalogue extensively describes many MLC datasets with comprehensible meta-features, MLC-specific semantic descriptions, and different data provenance information. The MLC data catalogue is extensively described in our recent publication in Nature Scientific Reports, Kostovska & Bogatinovski et al., and available at: http://semantichub.ijs.si/MLCdatasets. In addition, we provide an ontology-based system for easy access and querying of performance/benchmark data obtained from a comprehensive MLC benchmark study. The system is available at: http://semantichub.ijs.si/MLCbenchmark.
Explainable Model-specific Algorithm Selection for Multi-Label Classification
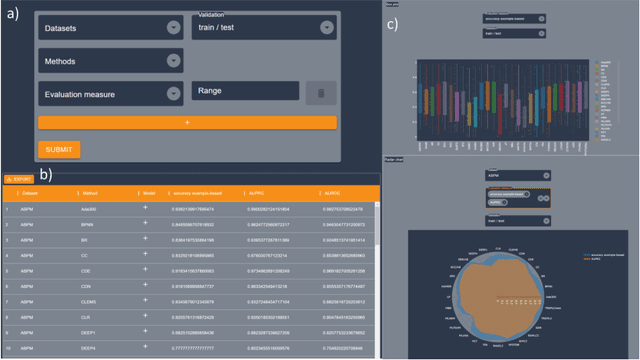
Nov 21, 2022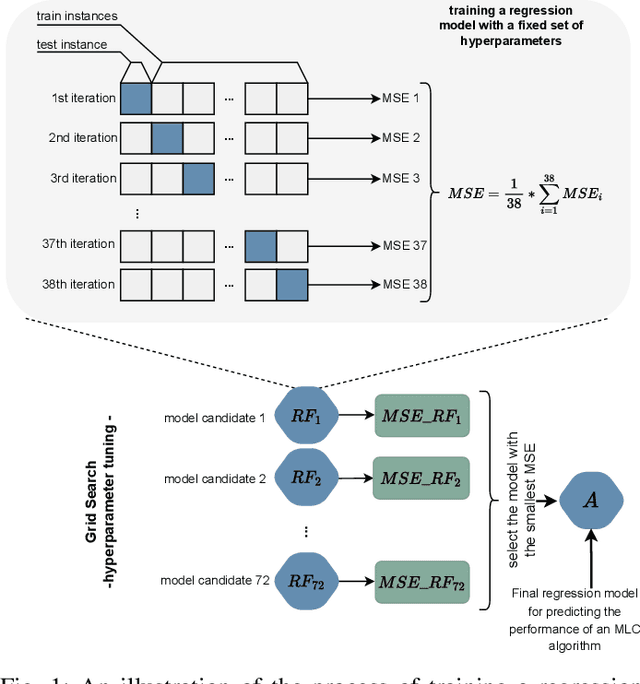
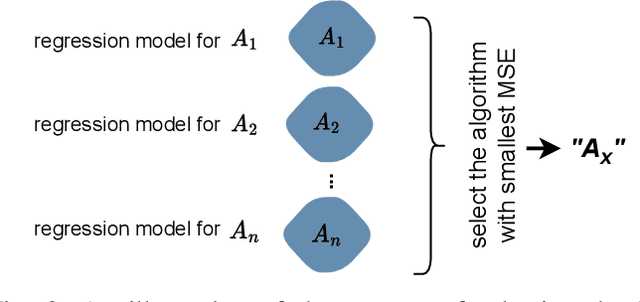
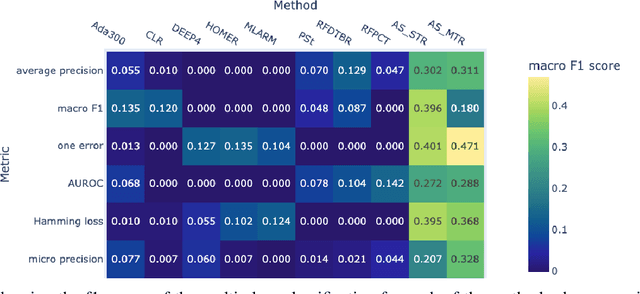
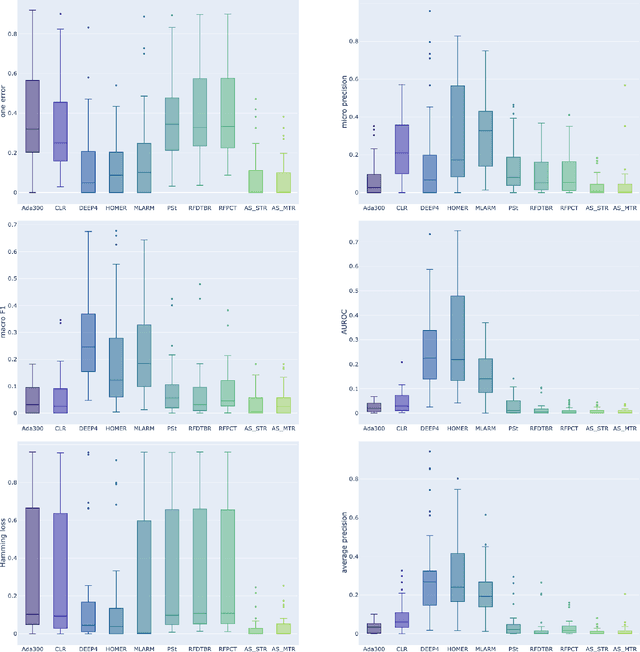
Multi-label classification (MLC) is an ML task of predictive modeling in which a data instance can simultaneously belong to multiple classes. MLC is increasingly gaining interest in different application domains such as text mining, computer vision, and bioinformatics. Several MLC algorithms have been proposed in the literature, resulting in a meta-optimization problem that the user needs to address: which MLC approach to select for a given dataset? To address this algorithm selection problem, we investigate in this work the quality of an automated approach that uses characteristics of the datasets - so-called features - and a trained algorithm selector to choose which algorithm to apply for a given task. For our empirical evaluation, we use a portfolio of 38 datasets. We consider eight MLC algorithms, whose quality we evaluate using six different performance metrics. We show that our automated algorithm selector outperforms any of the single MLC algorithms, and this is for all evaluated performance measures. Our selection approach is explainable, a characteristic that we exploit to investigate which meta-features have the largest influence on the decisions made by the algorithm selector. Finally, we also quantify the importance of the most significant meta-features for various domains.
Discover the Mysteries of the Maya: Selected Contributions from the Machine Learning Challenge & The Discovery Challenge Workshop at ECML PKDD 2021
Aug 09, 2022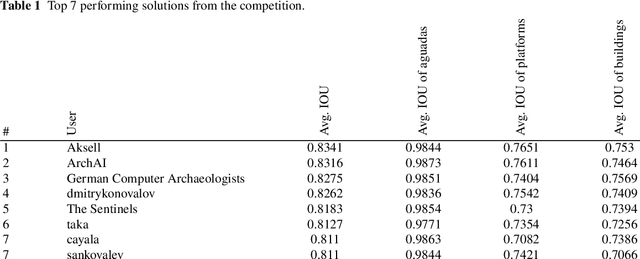
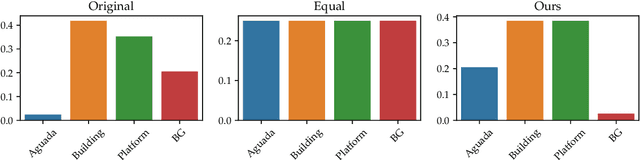


The volume contains selected contributions from the Machine Learning Challenge "Discover the Mysteries of the Maya", presented at the Discovery Challenge Track of The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD 2021). Remote sensing has greatly accelerated traditional archaeological landscape surveys in the forested regions of the ancient Maya. Typical exploration and discovery attempts, beside focusing on whole ancient cities, focus also on individual buildings and structures. Recently, there have been several successful attempts of utilizing machine learning for identifying ancient Maya settlements. These attempts, while relevant, focus on narrow areas and rely on high-quality aerial laser scanning (ALS) data which covers only a fraction of the region where ancient Maya were once settled. Satellite image data, on the other hand, produced by the European Space Agency's (ESA) Sentinel missions, is abundant and, more importantly, publicly available. The "Discover the Mysteries of the Maya" challenge aimed at locating and identifying ancient Maya architectures (buildings, aguadas, and platforms) by performing integrated image segmentation of different types of satellite imagery (from Sentinel-1 and Sentinel-2) data and ALS (lidar) data.
Semi-supervised Predictive Clustering Trees for (Hierarchical) Multi-label Classification
Jul 19, 2022


Semi-supervised learning (SSL) is a common approach to learning predictive models using not only labeled examples, but also unlabeled examples. While SSL for the simple tasks of classification and regression has received a lot of attention from the research community, this is not properly investigated for complex prediction tasks with structurally dependent variables. This is the case of multi-label classification and hierarchical multi-label classification tasks, which may require additional information, possibly coming from the underlying distribution in the descriptive space provided by unlabeled examples, to better face the challenging task of predicting simultaneously multiple class labels. In this paper, we investigate this aspect and propose a (hierarchical) multi-label classification method based on semi-supervised learning of predictive clustering trees. We also extend the method towards ensemble learning and propose a method based on the random forest approach. Extensive experimental evaluation conducted on 23 datasets shows significant advantages of the proposed method and its extension with respect to their supervised counterparts. Moreover, the method preserves interpretability and reduces the time complexity of classical tree-based models.
Current Trends in Deep Learning for Earth Observation: An Open-source Benchmark Arena for Image Classification
Jul 14, 2022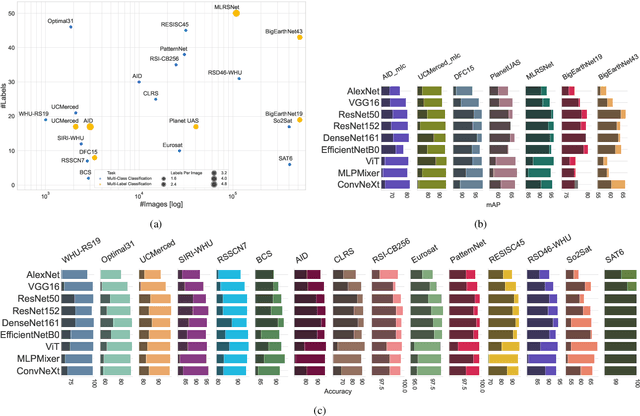
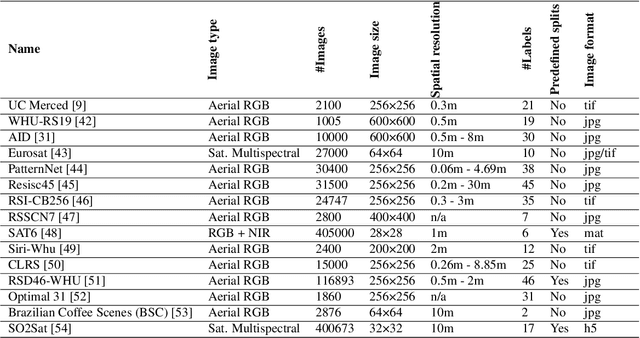
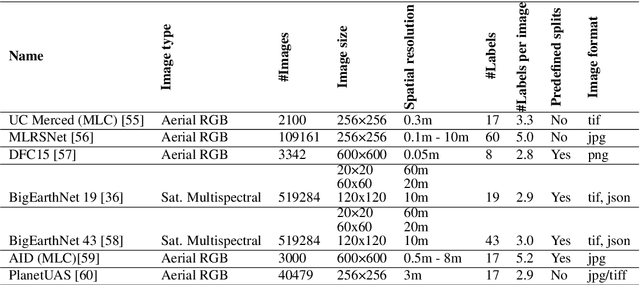
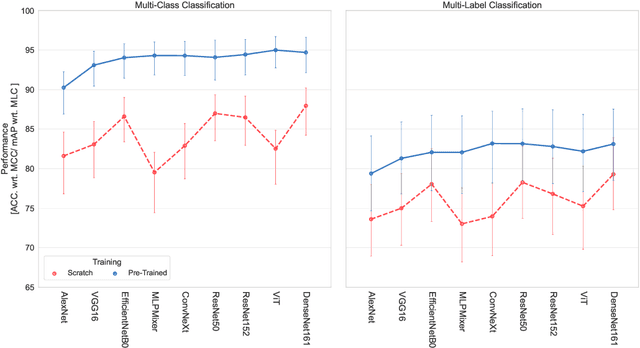
We present 'AiTLAS: Benchmark Arena' -- an open-source benchmark framework for evaluating state-of-the-art deep learning approaches for image classification in Earth Observation (EO). To this end, we present a comprehensive comparative analysis of more than 400 models derived from nine different state-of-the-art architectures, and compare them to a variety of multi-class and multi-label classification tasks from 22 datasets with different sizes and properties. In addition to models trained entirely on these datasets, we also benchmark models trained in the context of transfer learning, leveraging pre-trained model variants, as it is typically performed in practice. All presented approaches are general and can be easily extended to many other remote sensing image classification tasks not considered in this study. To ensure reproducibility and facilitate better usability and further developments, all of the experimental resources including the trained models, model configurations and processing details of the datasets (with their corresponding splits used for training and evaluating the models) are publicly available on the repository: https://github.com/biasvariancelabs/aitlas-arena.
AiTLAS: Artificial Intelligence Toolbox for Earth Observation
Jan 21, 2022
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which further allows benchmarking of various existing and novel AI methods tailored for EO data.
GalaxAI: Machine learning toolbox for interpretable analysis of spacecraft telemetry data
Aug 09, 2021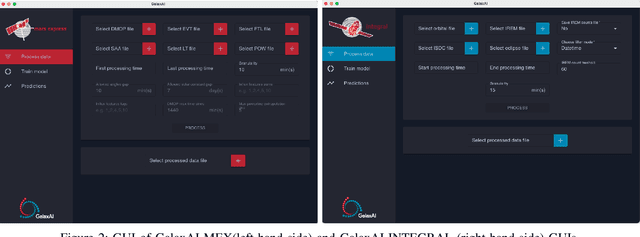
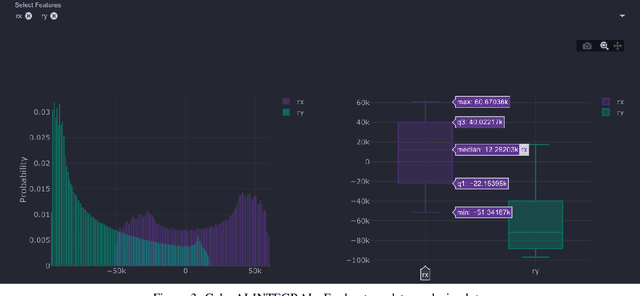
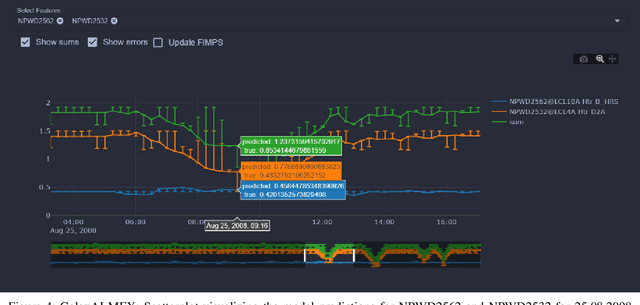
We present GalaxAI - a versatile machine learning toolbox for efficient and interpretable end-to-end analysis of spacecraft telemetry data. GalaxAI employs various machine learning algorithms for multivariate time series analyses, classification, regression and structured output prediction, capable of handling high-throughput heterogeneous data. These methods allow for the construction of robust and accurate predictive models, that are in turn applied to different tasks of spacecraft monitoring and operations planning. More importantly, besides the accurate building of models, GalaxAI implements a visualisation layer, providing mission specialists and operators with a full, detailed and interpretable view of the data analysis process. We show the utility and versatility of GalaxAI on two use-cases concerning two different spacecraft: i) analysis and planning of Mars Express thermal power consumption and ii) predicting of INTEGRAL's crossings through Van Allen belts.