 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining the Performance of Multi-label Classification Methods with Data Set Properties
Paper and Code
Jun 28, 2021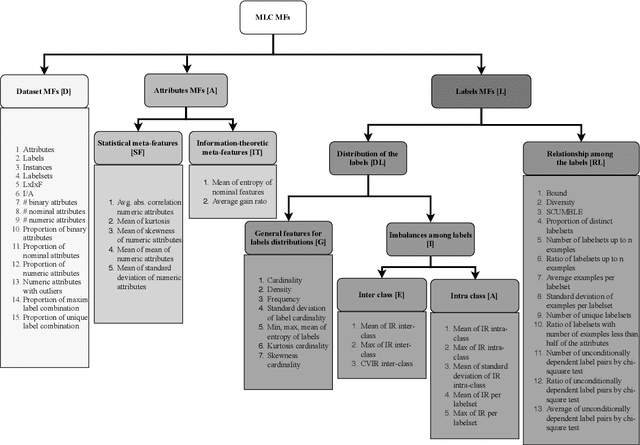

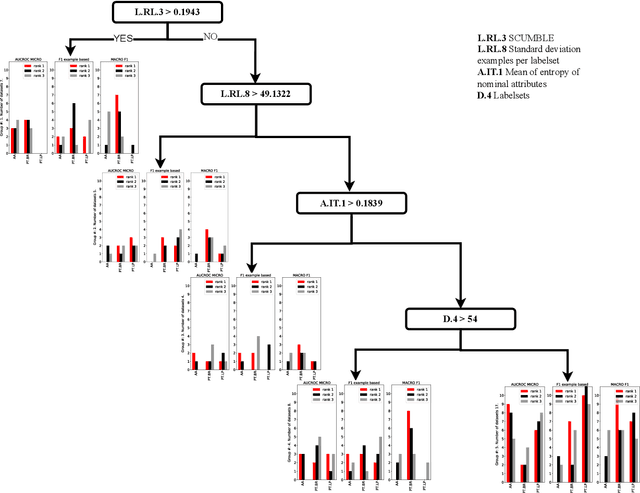

Meta learning generalizes the empirical experience with different learning tasks and holds promise for providing important empirical insight into the behaviour of machine learning algorithms. In this paper, we present a comprehensive meta-learning study of data sets and methods for multi-label classification (MLC). MLC is a practically relevant machine learning task where each example is labelled with multiple labels simultaneously. Here, we analyze 40 MLC data sets by using 50 meta features describing different properties of the data. The main findings of this study are as follows. First, the most prominent meta features that describe the space of MLC data sets are the ones assessing different aspects of the label space. Second, the meta models show that the most important meta features describe the label space, and, the meta features describing the relationships among the labels tend to occur a bit more often than the meta features describing the distributions between and within the individual labels. Third, the optimization of the hyperparameters can improve the predictive performance, however, quite often the extent of the improvements does not always justify the resource utilization.