 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroVLM-Bench: Evaluation of Vision-Enabled Large Language Models for Clinical Reasoning in Neurological Disorders
Mar 25, 2026Recent advances in multimodal large language models enable new possibilities for image-based decision support. However, their reliability and operational trade-offs in neuroimaging remain insufficiently understood. We present a comprehensive benchmarking study of vision-enabled large language models for 2D neuroimaging using curated MRI and CT datasets covering multiple sclerosis, stroke, brain tumors, other abnormalities, and normal controls. Models are required to generate multiple outputs simultaneously, including diagnosis, diagnosis subtype, imaging modality, specialized sequence, and anatomical plane. Performance is evaluated across four directions: discriminative classification with abstention, calibration, structured-output validity, and computational efficiency. A multi-phase framework ensures fair comparison while controlling for selection bias. Across twenty frontier multimodal models, the results show that technical imaging attributes such as modality and plane are nearly solved, whereas diagnostic reasoning, especially subtype prediction, remains challenging. Tumor classification emerges as the most reliable task, stroke is moderately solvable, while multiple sclerosis and rare abnormalities remain difficult. Few-shot prompting improves performance for several models but increases token usage, latency, and cost. Gemini-2.5-Pro and GPT-5-Chat achieve the strongest overall diagnostic performance, while Gemini-2.5-Flash offers the best efficiency-performance trade-off. Among open-weight architectures, MedGemma-1.5-4B demonstrates the most promising results, as under few-shot prompting, it approaches the zero-shot performance of several proprietary models, while maintaining perfect structured output. These findings provide practical insights into performance, reliability, and efficiency trade-offs, supporting standardized evaluation of multimodal LLMs in neuroimaging.
Deep Multimodal Fusion for Semantic Segmentation of Remote Sensing Earth Observation Data
Oct 01, 2024
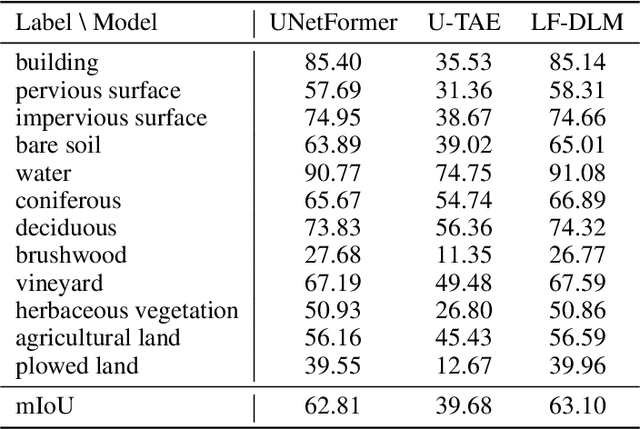
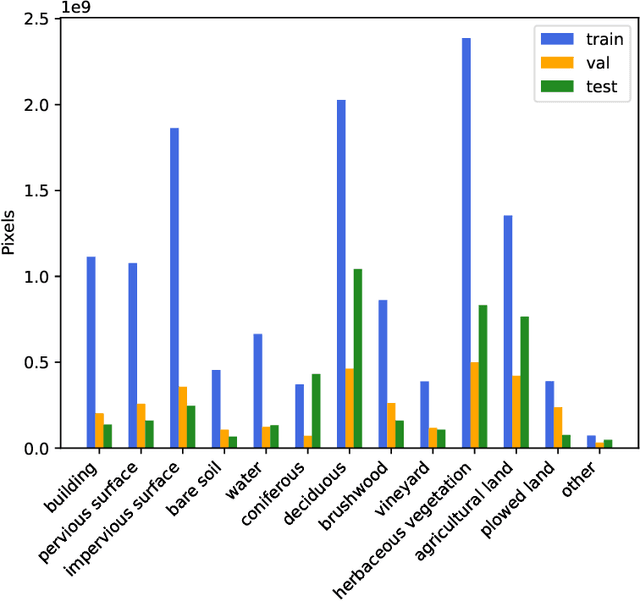
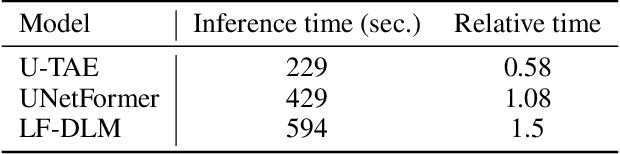
Accurate semantic segmentation of remote sensing imagery is critical for various Earth observation applications, such as land cover mapping, urban planning, and environmental monitoring. However, individual data sources often present limitations for this task. Very High Resolution (VHR) aerial imagery provides rich spatial details but cannot capture temporal information about land cover changes. Conversely, Satellite Image Time Series (SITS) capture temporal dynamics, such as seasonal variations in vegetation, but with limited spatial resolution, making it difficult to distinguish fine-scale objects. This paper proposes a late fusion deep learning model (LF-DLM) for semantic segmentation that leverages the complementary strengths of both VHR aerial imagery and SITS. The proposed model consists of two independent deep learning branches. One branch integrates detailed textures from aerial imagery captured by UNetFormer with a Multi-Axis Vision Transformer (MaxViT) backbone. The other branch captures complex spatio-temporal dynamics from the Sentinel-2 satellite image time series using a U-Net with Temporal Attention Encoder (U-TAE). This approach leads to state-of-the-art results on the FLAIR dataset, a large-scale benchmark for land cover segmentation using multi-source optical imagery. The findings highlight the importance of multi-modality fusion in improving the accuracy and robustness of semantic segmentation in remote sensing applications.
Semantic Segmentation of Unmanned Aerial Vehicle Remote Sensing Images using SegFormer
Oct 01, 2024The escalating use of Unmanned Aerial Vehicles (UAVs) as remote sensing platforms has garnered considerable attention, proving invaluable for ground object recognition. While satellite remote sensing images face limitations in resolution and weather susceptibility, UAV remote sensing, employing low-speed unmanned aircraft, offers enhanced object resolution and agility. The advent of advanced machine learning techniques has propelled significant strides in image analysis, particularly in semantic segmentation for UAV remote sensing images. This paper evaluates the effectiveness and efficiency of SegFormer, a semantic segmentation framework, for the semantic segmentation of UAV images. SegFormer variants, ranging from real-time (B0) to high-performance (B5) models, are assessed using the UAVid dataset tailored for semantic segmentation tasks. The research details the architecture and training procedures specific to SegFormer in the context of UAV semantic segmentation. Experimental results showcase the model's performance on benchmark dataset, highlighting its ability to accurately delineate objects and land cover features in diverse UAV scenarios, leading to both high efficiency and performance.
In-Domain Self-Supervised Learning Can Lead to Improvements in Remote Sensing Image Classification
Jul 04, 2023


Self-supervised learning (SSL) has emerged as a promising approach for remote sensing image classification due to its ability to leverage large amounts of unlabeled data. In contrast to traditional supervised learning, SSL aims to learn representations of data without the need for explicit labels. This is achieved by formulating auxiliary tasks that can be used to create pseudo-labels for the unlabeled data and learn pre-trained models. The pre-trained models can then be fine-tuned on downstream tasks such as remote sensing image scene classification. The paper analyzes the effectiveness of SSL pre-training using Million AID - a large unlabeled remote sensing dataset on various remote sensing image scene classification datasets as downstream tasks. More specifically, we evaluate the effectiveness of SSL pre-training using the iBOT framework coupled with Vision transformers (ViT) in contrast to supervised pre-training of ViT using the ImageNet dataset. The comprehensive experimental work across 14 datasets with diverse properties reveals that in-domain SSL leads to improved predictive performance of models compared to the supervised counterparts.
Current Trends in Deep Learning for Earth Observation: An Open-source Benchmark Arena for Image Classification
Jul 14, 2022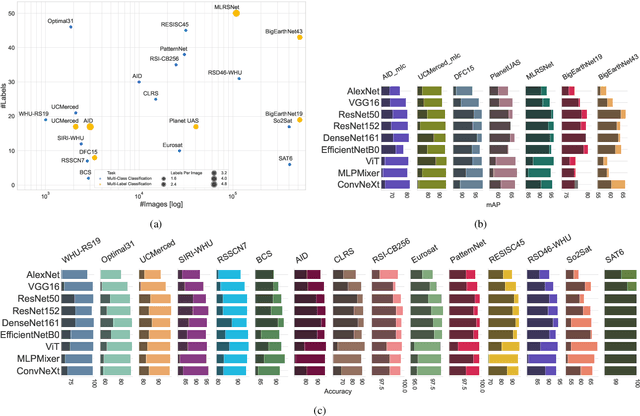
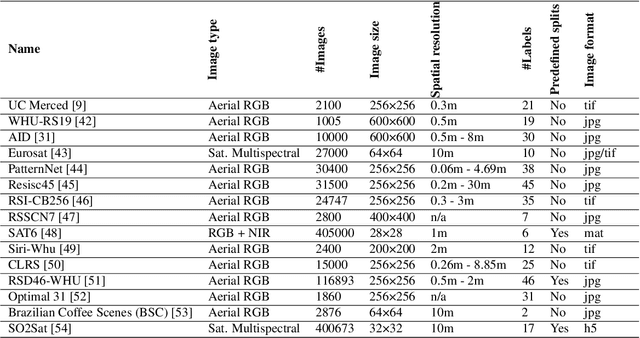
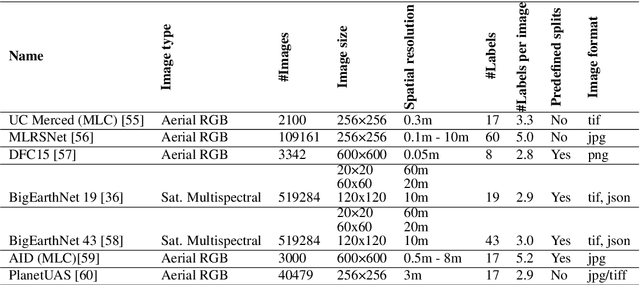
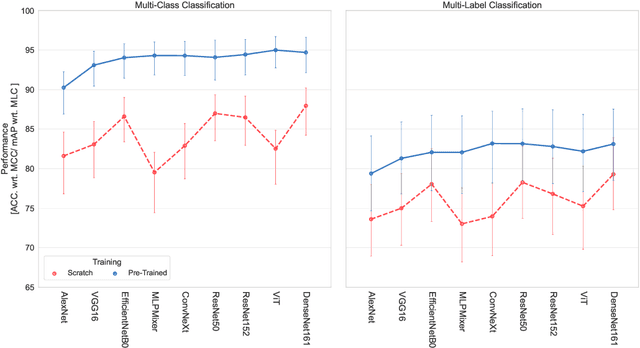
We present 'AiTLAS: Benchmark Arena' -- an open-source benchmark framework for evaluating state-of-the-art deep learning approaches for image classification in Earth Observation (EO). To this end, we present a comprehensive comparative analysis of more than 400 models derived from nine different state-of-the-art architectures, and compare them to a variety of multi-class and multi-label classification tasks from 22 datasets with different sizes and properties. In addition to models trained entirely on these datasets, we also benchmark models trained in the context of transfer learning, leveraging pre-trained model variants, as it is typically performed in practice. All presented approaches are general and can be easily extended to many other remote sensing image classification tasks not considered in this study. To ensure reproducibility and facilitate better usability and further developments, all of the experimental resources including the trained models, model configurations and processing details of the datasets (with their corresponding splits used for training and evaluating the models) are publicly available on the repository: https://github.com/biasvariancelabs/aitlas-arena.
AiTLAS: Artificial Intelligence Toolbox for Earth Observation
Jan 21, 2022
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which further allows benchmarking of various existing and novel AI methods tailored for EO data.