 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Knowledge Graphs for Performance Prediction of Modular Optimization Algorithms
Jan 24, 2023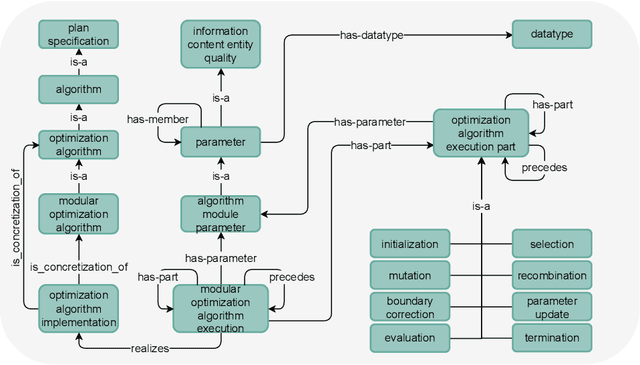
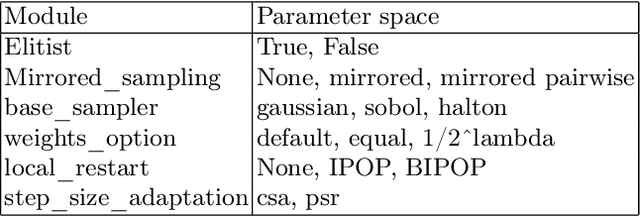
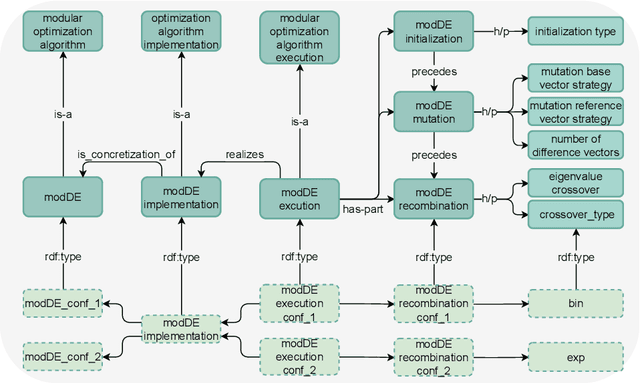

Empirical data plays an important role in evolutionary computation research. To make better use of the available data, ontologies have been proposed in the literature to organize their storage in a structured way. However, the full potential of these formal methods to capture our domain knowledge has yet to be demonstrated. In this work, we evaluate a performance prediction model built on top of the extension of the recently proposed OPTION ontology. More specifically, we first extend the OPTION ontology with the vocabulary needed to represent modular black-box optimization algorithms. Then, we use the extended OPTION ontology, to create knowledge graphs with fixed-budget performance data for two modular algorithm frameworks, modCMA, and modDE, for the 24 noiseless BBOB benchmark functions. We build the performance prediction model using a knowledge graph embedding-based methodology. Using a number of different evaluation scenarios, we show that a triple classification approach, a fairly standard predictive modeling task in the context of knowledge graphs, can correctly predict whether a given algorithm instance will be able to achieve a certain target precision for a given problem instance. This approach requires feature representation of algorithms and problems. While the latter is already well developed, we hope that our work will motivate the community to collaborate on appropriate algorithm representations.
FAIRification of MLC data
Nov 23, 2022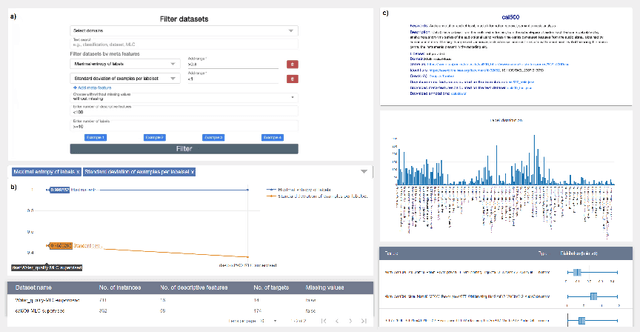
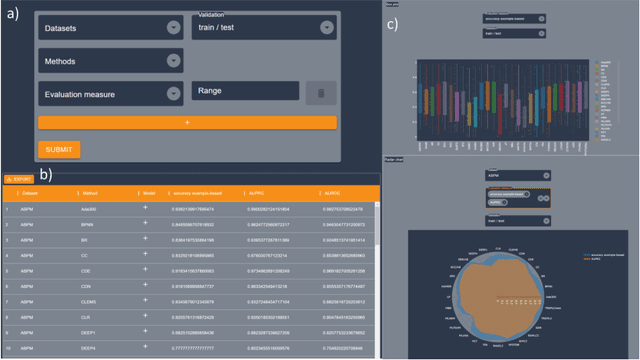
The multi-label classification (MLC) task has increasingly been receiving interest from the machine learning (ML) community, as evidenced by the growing number of papers and methods that appear in the literature. Hence, ensuring proper, correct, robust, and trustworthy benchmarking is of utmost importance for the further development of the field. We believe that this can be achieved by adhering to the recently emerged data management standards, such as the FAIR (Findable, Accessible, Interoperable, and Reusable) and TRUST (Transparency, Responsibility, User focus, Sustainability, and Technology) principles. To FAIRify the MLC datasets, we introduce an ontology-based online catalogue of MLC datasets that follow these principles. The catalogue extensively describes many MLC datasets with comprehensible meta-features, MLC-specific semantic descriptions, and different data provenance information. The MLC data catalogue is extensively described in our recent publication in Nature Scientific Reports, Kostovska & Bogatinovski et al., and available at: http://semantichub.ijs.si/MLCdatasets. In addition, we provide an ontology-based system for easy access and querying of performance/benchmark data obtained from a comprehensive MLC benchmark study. The system is available at: http://semantichub.ijs.si/MLCbenchmark.
OPTION: OPTImization Algorithm Benchmarking ONtology
Nov 21, 2022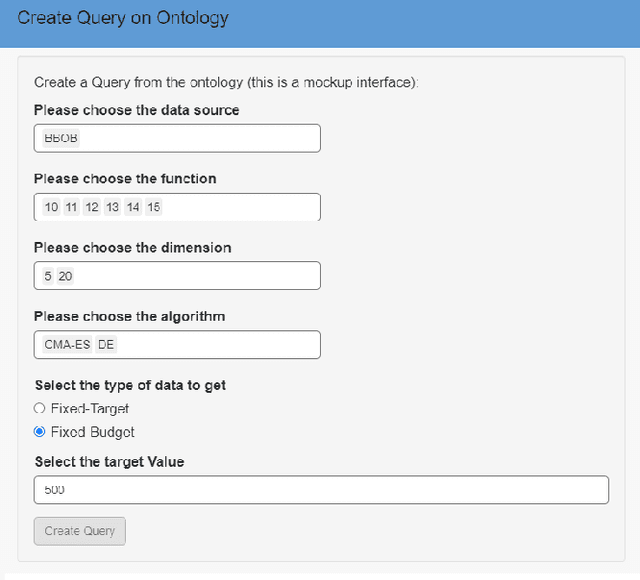
Many optimization algorithm benchmarking platforms allow users to share their experimental data to promote reproducible and reusable research. However, different platforms use different data models and formats, which drastically complicates the identification of relevant datasets, their interpretation, and their interoperability. Therefore, a semantically rich, ontology-based, machine-readable data model that can be used by different platforms is highly desirable. In this paper, we report on the development of such an ontology, which we call OPTION (OPTImization algorithm benchmarking ONtology). Our ontology provides the vocabulary needed for semantic annotation of the core entities involved in the benchmarking process, such as algorithms, problems, and evaluation measures. It also provides means for automatic data integration, improved interoperability, and powerful querying capabilities, thereby increasing the value of the benchmarking data. We demonstrate the utility of OPTION, by annotating and querying a corpus of benchmark performance data from the BBOB collection of the COCO framework and from the Yet Another Black-Box Optimization Benchmark (YABBOB) family of the Nevergrad environment. In addition, we integrate features of the BBOB functional performance landscape into the OPTION knowledge base using publicly available datasets with exploratory landscape analysis. Finally, we integrate the OPTION knowledge base into the IOHprofiler environment and provide users with the ability to perform meta-analysis of performance data.
Explainable Model-specific Algorithm Selection for Multi-Label Classification
Nov 21, 2022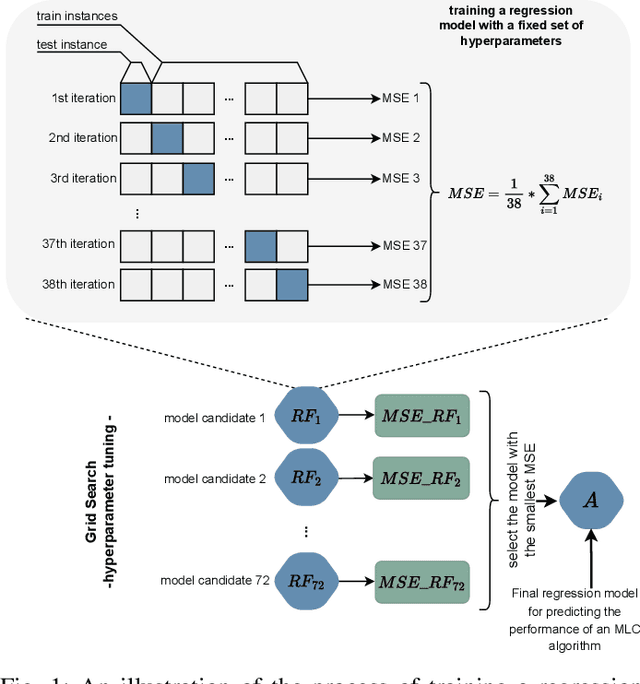
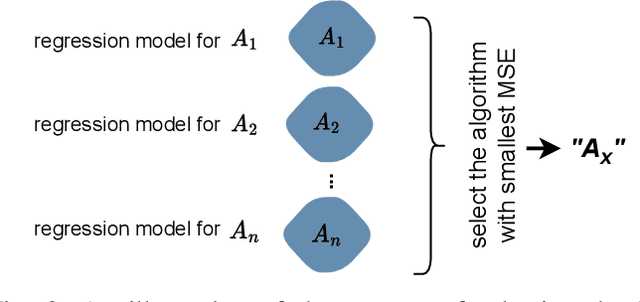
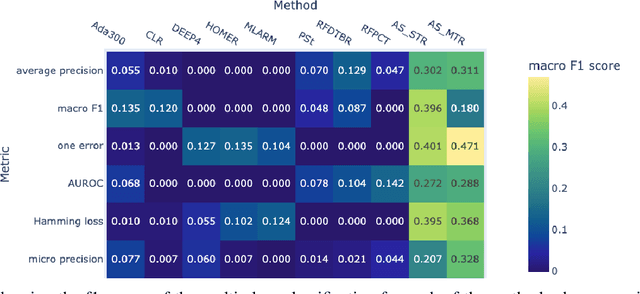
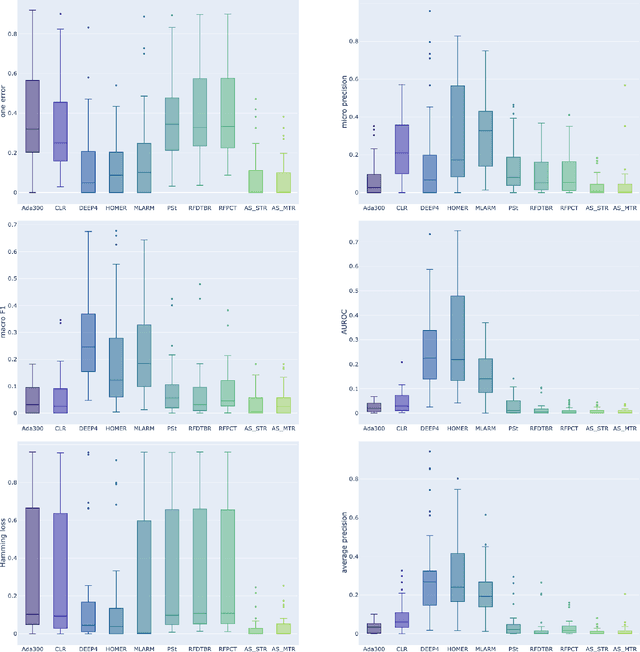
Multi-label classification (MLC) is an ML task of predictive modeling in which a data instance can simultaneously belong to multiple classes. MLC is increasingly gaining interest in different application domains such as text mining, computer vision, and bioinformatics. Several MLC algorithms have been proposed in the literature, resulting in a meta-optimization problem that the user needs to address: which MLC approach to select for a given dataset? To address this algorithm selection problem, we investigate in this work the quality of an automated approach that uses characteristics of the datasets - so-called features - and a trained algorithm selector to choose which algorithm to apply for a given task. For our empirical evaluation, we use a portfolio of 38 datasets. We consider eight MLC algorithms, whose quality we evaluate using six different performance metrics. We show that our automated algorithm selector outperforms any of the single MLC algorithms, and this is for all evaluated performance measures. Our selection approach is explainable, a characteristic that we exploit to investigate which meta-features have the largest influence on the decisions made by the algorithm selector. Finally, we also quantify the importance of the most significant meta-features for various domains.
AiTLAS: Artificial Intelligence Toolbox for Earth Observation
Jan 21, 2022
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which further allows benchmarking of various existing and novel AI methods tailored for EO data.
GalaxAI: Machine learning toolbox for interpretable analysis of spacecraft telemetry data
Aug 09, 2021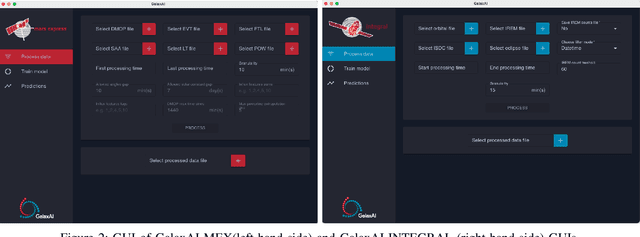
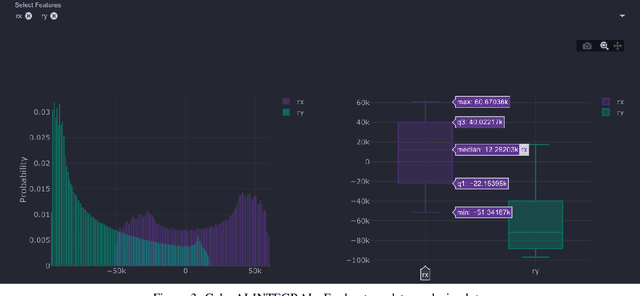
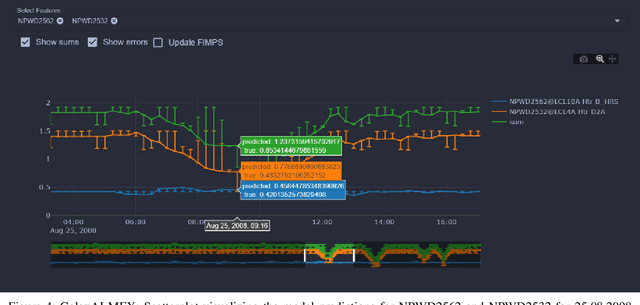
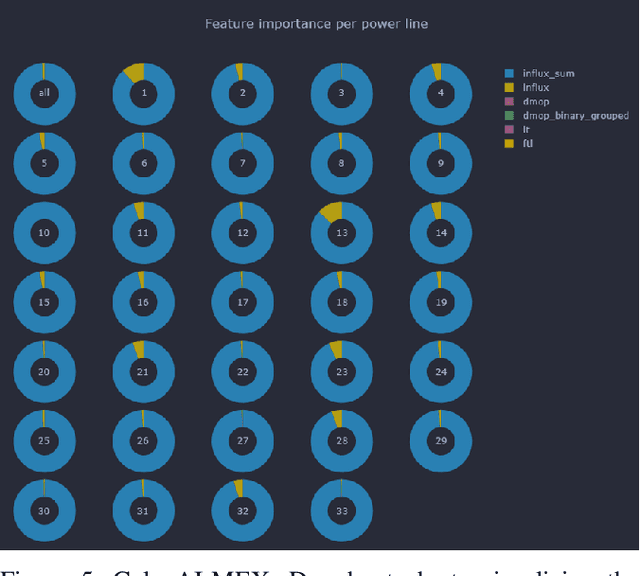
We present GalaxAI - a versatile machine learning toolbox for efficient and interpretable end-to-end analysis of spacecraft telemetry data. GalaxAI employs various machine learning algorithms for multivariate time series analyses, classification, regression and structured output prediction, capable of handling high-throughput heterogeneous data. These methods allow for the construction of robust and accurate predictive models, that are in turn applied to different tasks of spacecraft monitoring and operations planning. More importantly, besides the accurate building of models, GalaxAI implements a visualisation layer, providing mission specialists and operators with a full, detailed and interpretable view of the data analysis process. We show the utility and versatility of GalaxAI on two use-cases concerning two different spacecraft: i) analysis and planning of Mars Express thermal power consumption and ii) predicting of INTEGRAL's crossings through Van Allen belts.
Discovering outliers in the Mars Express thermal power consumption patterns
Aug 04, 2021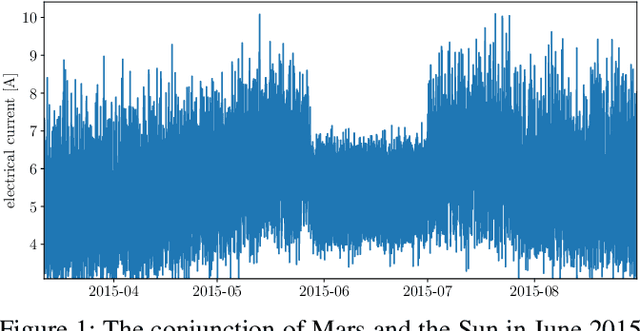
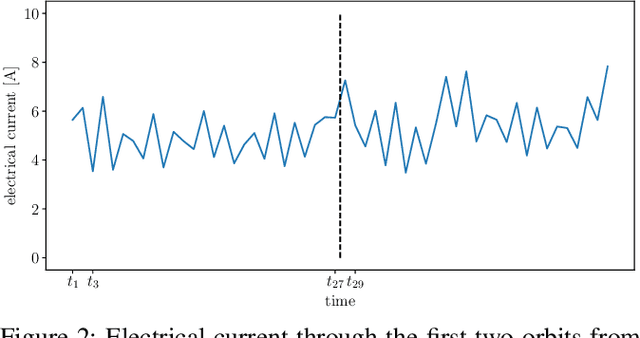
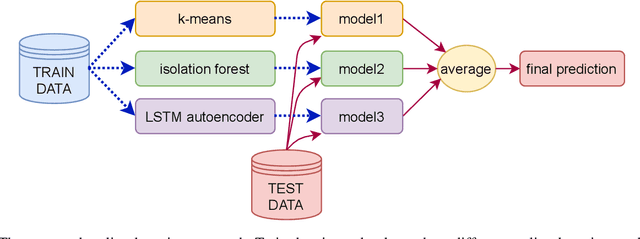
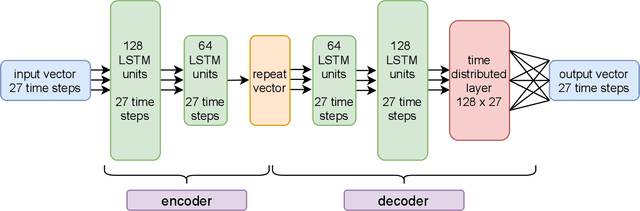
The Mars Express (MEX) spacecraft has been orbiting Mars since 2004. The operators need to constantly monitor its behavior and handle sporadic deviations (outliers) from the expected patterns of measurements of quantities that the satellite is sending to Earth. In this paper, we analyze the patterns of the electrical power consumption of MEX's thermal subsystem, that maintains the spacecraft's temperature at the desired level. The consumption is not constant, but should be roughly periodic in the short term, with the period that corresponds to one orbit around Mars. By using long short-term memory neural networks, we show that the consumption pattern is more irregular than expected, and successfully detect such irregularities, opening possibility for automatic outlier detection on MEX in the future.
ML-Schema: Exposing the Semantics of Machine Learning with Schemas and Ontologies
Jul 14, 2018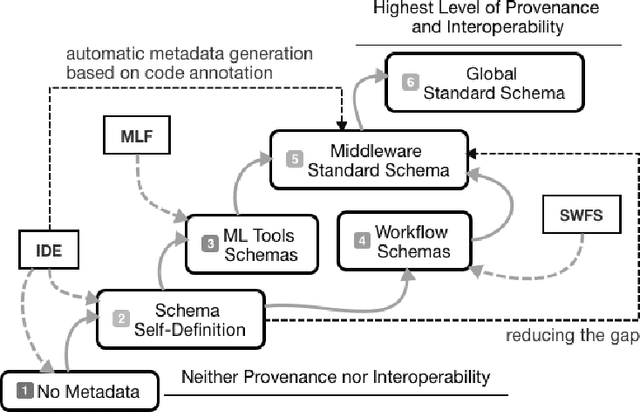
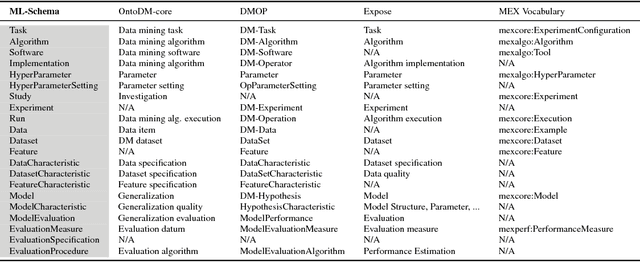
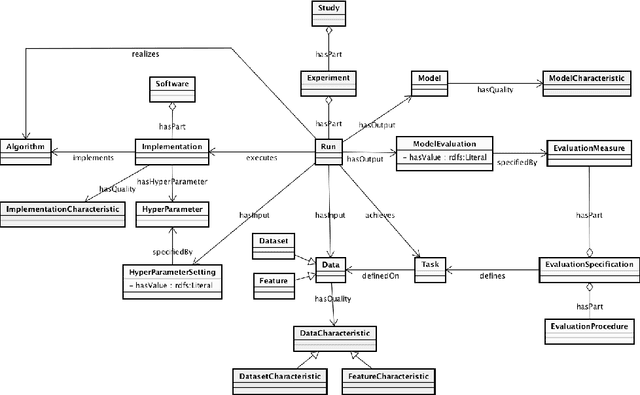
The ML-Schema, proposed by the W3C Machine Learning Schema Community Group, is a top-level ontology that provides a set of classes, properties, and restrictions for representing and interchanging information on machine learning algorithms, datasets, and experiments. It can be easily extended and specialized and it is also mapped to other more domain-specific ontologies developed in the area of machine learning and data mining. In this paper we overview existing state-of-the-art machine learning interchange formats and present the first release of ML-Schema, a canonical format resulted of more than seven years of experience among different research institutions. We argue that exposing semantics of machine learning algorithms, models, and experiments through a canonical format may pave the way to better interpretability and to realistically achieve the full interoperability of experiments regardless of platform or adopted workflow solution.