 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-domain Event Extraction and Embedding for Natural Gas Market Prediction
Dec 08, 2019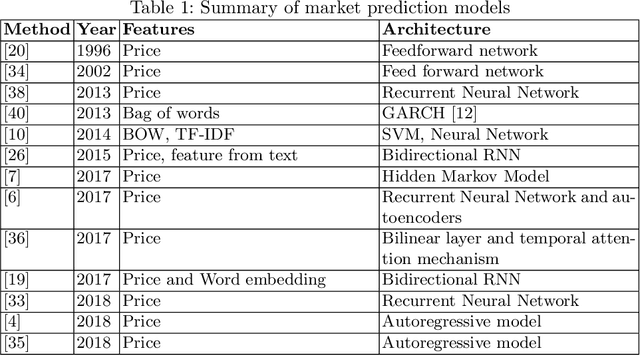
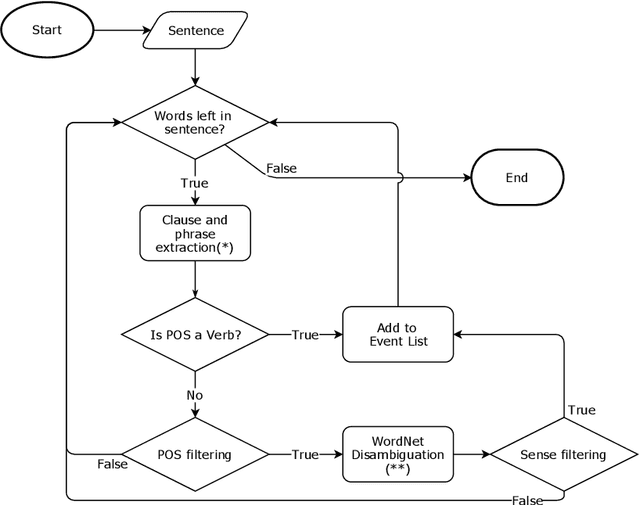

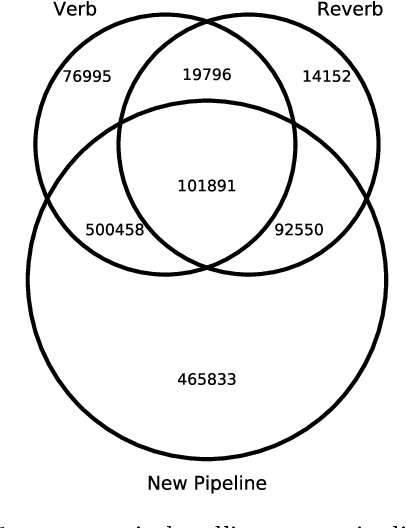
We propose an approach to predict the natural gas price in several days using historical price data and events extracted from news headlines. Most previous methods treats price as an extrapolatable time series, those analyze the relation between prices and news either trim their price data correspondingly to a public news dataset, manually annotate headlines or use off-the-shelf tools. In comparison to off-the-shelf tools, our event extraction method detects not only the occurrence of phenomena but also the changes in attribution and characteristics from public sources. Instead of using sentence embedding as a feature, we use every word of the extracted events, encode and organize them before feeding to the learning models. Empirical results show favorable results, in terms of prediction performance, money saved and scalability.
DeFactoNLP: Fact Verification using Entity Recognition, TFIDF Vector Comparison and Decomposable Attention
Sep 03, 2018
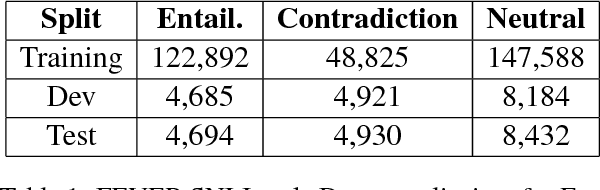
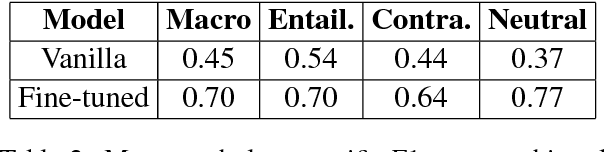
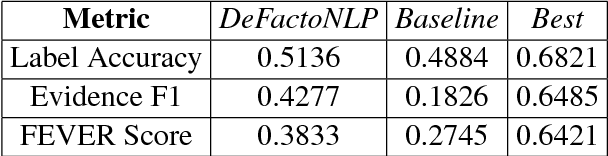
In this paper, we describe DeFactoNLP, the system we designed for the FEVER 2018 Shared Task. The aim of this task was to conceive a system that can not only automatically assess the veracity of a claim but also retrieve evidence supporting this assessment from Wikipedia. In our approach, the Wikipedia documents whose Term Frequency-Inverse Document Frequency (TFIDF) vectors are most similar to the vector of the claim and those documents whose names are similar to those of the named entities (NEs) mentioned in the claim are identified as the documents which might contain evidence. The sentences in these documents are then supplied to a textual entailment recognition module. This module calculates the probability of each sentence supporting the claim, contradicting the claim or not providing any relevant information to assess the veracity of the claim. Various features computed using these probabilities are finally used by a Random Forest classifier to determine the overall truthfulness of the claim. The sentences which support this classification are returned as evidence. Our approach achieved a 0.4277 evidence F1-score, a 0.5136 label accuracy and a 0.3833 FEVER score.
Belittling the Source: Trustworthiness Indicators to Obfuscate Fake News on the Web
Sep 03, 2018
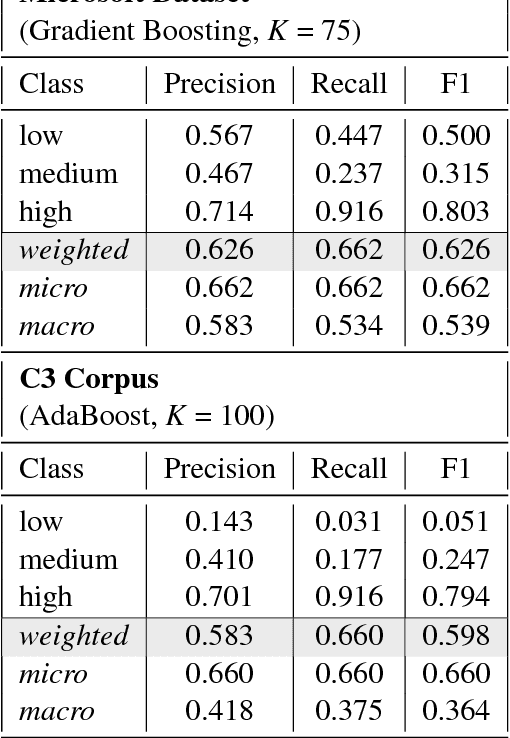
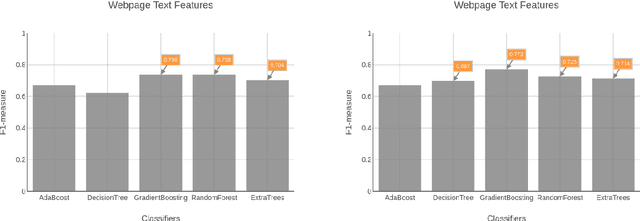
With the growth of the internet, the number of fake-news online has been proliferating every year. The consequences of such phenomena are manifold, ranging from lousy decision-making process to bullying and violence episodes. Therefore, fact-checking algorithms became a valuable asset. To this aim, an important step to detect fake-news is to have access to a credibility score for a given information source. However, most of the widely used Web indicators have either been shut-down to the public (e.g., Google PageRank) or are not free for use (Alexa Rank). Further existing databases are short-manually curated lists of online sources, which do not scale. Finally, most of the research on the topic is theoretical-based or explore confidential data in a restricted simulation environment. In this paper we explore current research, highlight the challenges and propose solutions to tackle the problem of classifying websites into a credibility scale. The proposed model automatically extracts source reputation cues and computes a credibility factor, providing valuable insights which can help in belittling dubious and confirming trustful unknown websites. Experimental results outperform state of the art in the 2-classes and 5-classes setting.
ML-Schema: Exposing the Semantics of Machine Learning with Schemas and Ontologies
Jul 14, 2018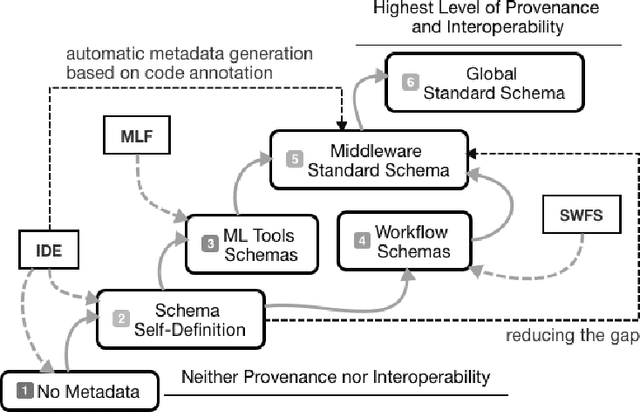
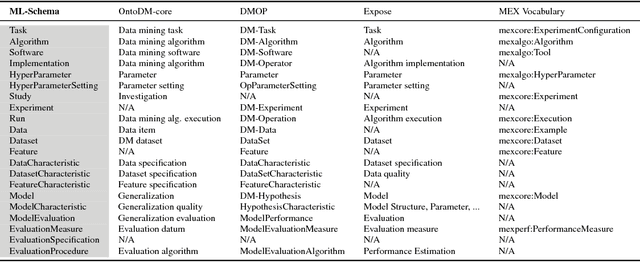
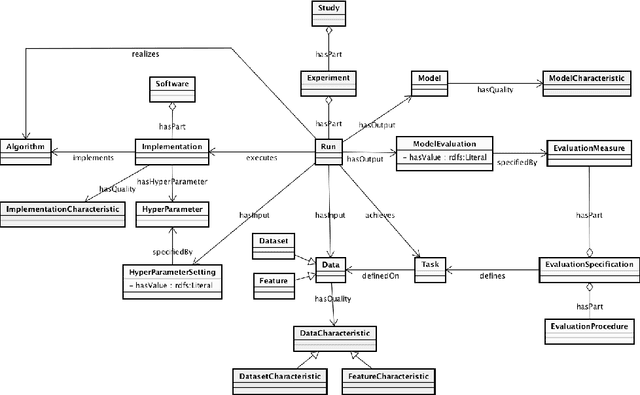
The ML-Schema, proposed by the W3C Machine Learning Schema Community Group, is a top-level ontology that provides a set of classes, properties, and restrictions for representing and interchanging information on machine learning algorithms, datasets, and experiments. It can be easily extended and specialized and it is also mapped to other more domain-specific ontologies developed in the area of machine learning and data mining. In this paper we overview existing state-of-the-art machine learning interchange formats and present the first release of ML-Schema, a canonical format resulted of more than seven years of experience among different research institutions. We argue that exposing semantics of machine learning algorithms, models, and experiments through a canonical format may pave the way to better interpretability and to realistically achieve the full interoperability of experiments regardless of platform or adopted workflow solution.
Neural Machine Translation for Query Construction and Composition
Jul 09, 2018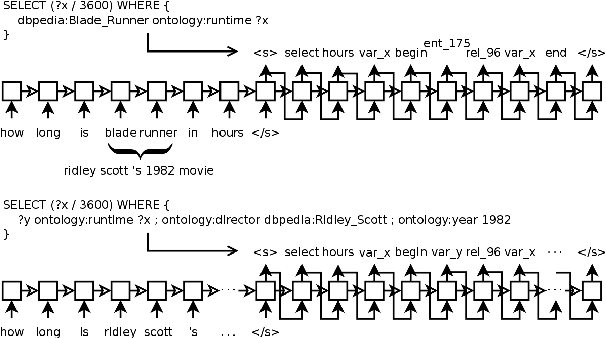
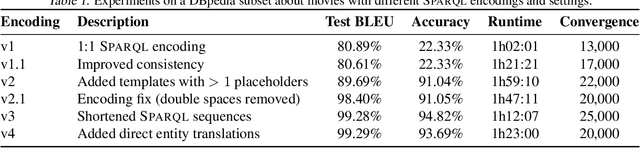

Research on question answering with knowledge base has recently seen an increasing use of deep architectures. In this extended abstract, we study the application of the neural machine translation paradigm for question parsing. We employ a sequence-to-sequence model to learn graph patterns in the SPARQL graph query language and their compositions. Instead of inducing the programs through question-answer pairs, we expect a semi-supervised approach, where alignments between questions and queries are built through templates. We argue that the coverage of language utterances can be expanded using late notable works in natural language generation.
Expeditious Generation of Knowledge Graph Embeddings
Mar 21, 2018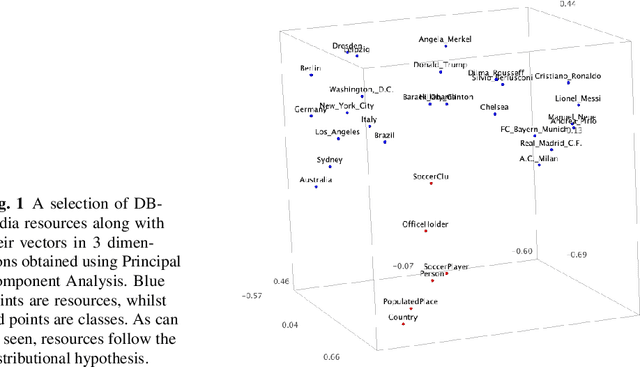
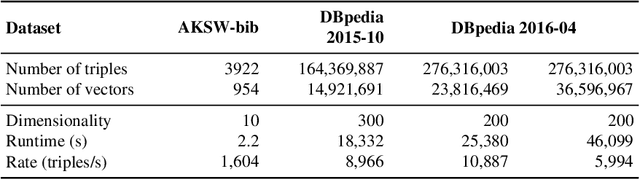
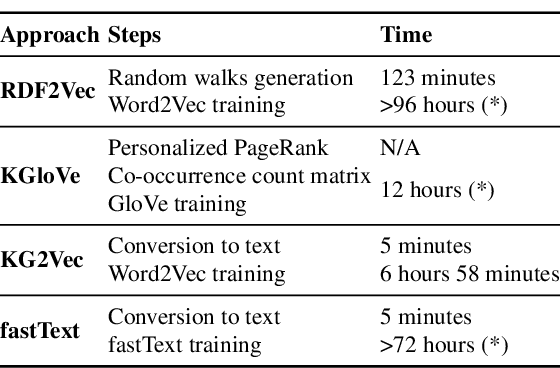
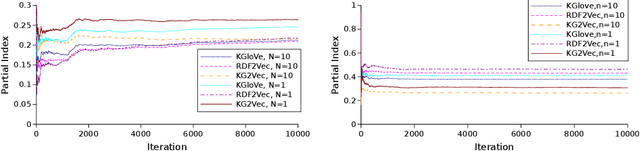
Knowledge Graph Embedding methods aim at representing entities and relations in a knowledge base as points or vectors in a continuous vector space. Several approaches using embeddings have shown promising results on tasks such as link prediction, entity recommendation, question answering, and triplet classification. However, only a few methods can compute low-dimensional embeddings of very large knowledge bases. In this paper, we propose KG2Vec, a novel approach to Knowledge Graph Embedding based on the skip-gram model. Instead of using a predefined scoring function, we learn it relying on Long Short-Term Memories. We evaluated the goodness of our embeddings on knowledge graph completion and show that KG2Vec is comparable to the quality of the scalable state-of-the-art approaches and can process large graphs by parsing more than a hundred million triples in less than 6 hours on common hardware.
LIDIOMS: A Multilingual Linked Idioms Data Set
Feb 22, 2018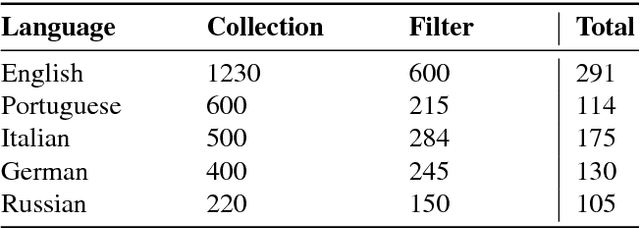



In this paper, we describe the LIDIOMS data set, a multilingual RDF representation of idioms currently containing five languages: English, German, Italian, Portuguese, and Russian. The data set is intended to support natural language processing applications by providing links between idioms across languages. The underlying data was crawled and integrated from various sources. To ensure the quality of the crawled data, all idioms were evaluated by at least two native speakers. Herein, we present the model devised for structuring the data. We also provide the details of linking LIDIOMS to well-known multilingual data sets such as BabelNet. The resulting data set complies with best practices according to Linguistic Linked Open Data Community.
Mandolin: A Knowledge Discovery Framework for the Web of Data
Nov 03, 2017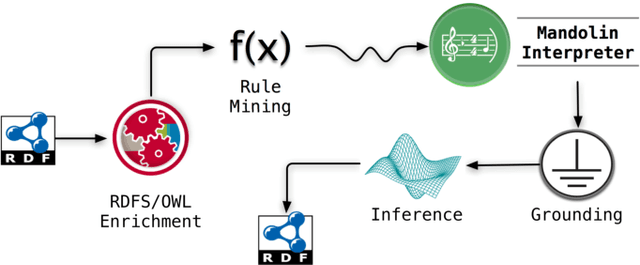

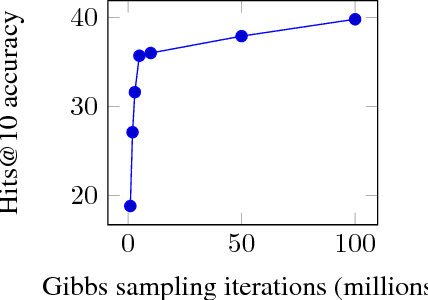
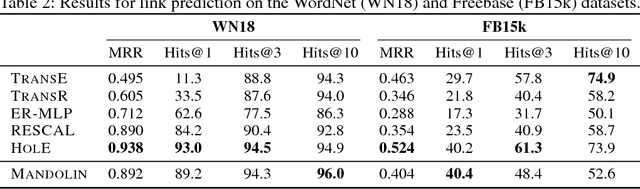
Markov Logic Networks join probabilistic modeling with first-order logic and have been shown to integrate well with the Semantic Web foundations. While several approaches have been devised to tackle the subproblems of rule mining, grounding, and inference, no comprehensive workflow has been proposed so far. In this paper, we fill this gap by introducing a framework called Mandolin, which implements a workflow for knowledge discovery specifically on RDF datasets. Our framework imports knowledge from referenced graphs, creates similarity relationships among similar literals, and relies on state-of-the-art techniques for rule mining, grounding, and inference computation. We show that our best configuration scales well and achieves at least comparable results with respect to other statistical-relational-learning algorithms on link prediction.
Named Entity Recognition in Twitter using Images and Text
Oct 30, 2017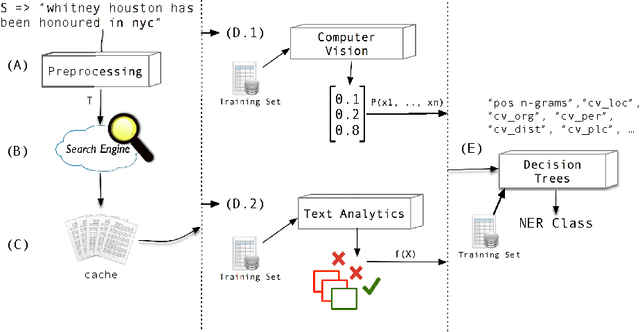

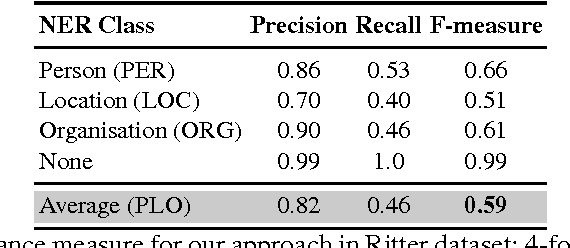

Named Entity Recognition (NER) is an important subtask of information extraction that seeks to locate and recognise named entities. Despite recent achievements, we still face limitations with correctly detecting and classifying entities, prominently in short and noisy text, such as Twitter. An important negative aspect in most of NER approaches is the high dependency on hand-crafted features and domain-specific knowledge, necessary to achieve state-of-the-art results. Thus, devising models to deal with such linguistically complex contexts is still challenging. In this paper, we propose a novel multi-level architecture that does not rely on any specific linguistic resource or encoded rule. Unlike traditional approaches, we use features extracted from images and text to classify named entities. Experimental tests against state-of-the-art NER for Twitter on the Ritter dataset present competitive results (0.59 F-measure), indicating that this approach may lead towards better NER models.
TANKER: Distributed Architecture for Named Entity Recognition and Disambiguation
Oct 25, 2017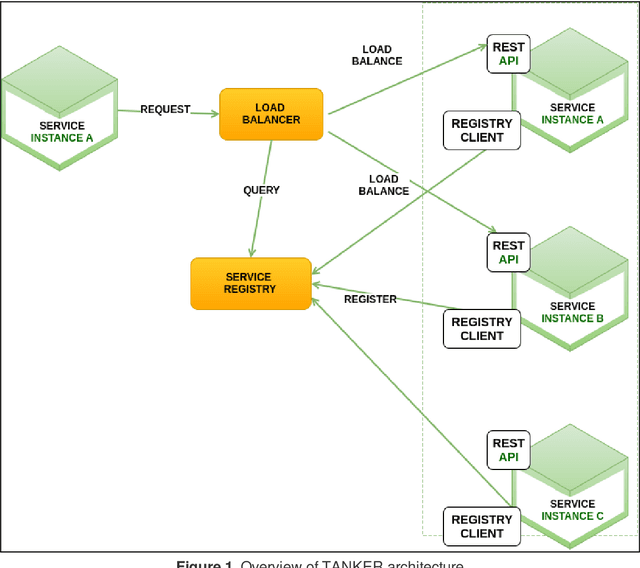
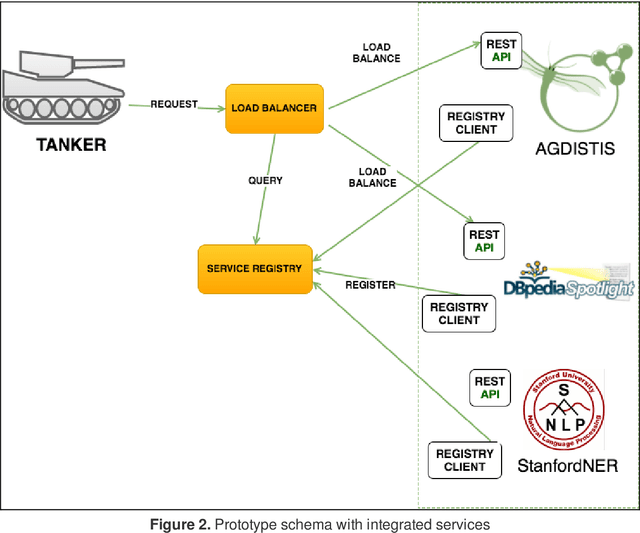
Named Entity Recognition and Disambiguation (NERD) systems have recently been widely researched to deal with the significant growth of the Web. NERD systems are crucial for several Natural Language Processing (NLP) tasks such as summarization, understanding, and machine translation. However, there is no standard interface specification, i.e. these systems may vary significantly either for exporting their outputs or for processing the inputs. Thus, when a given company desires to implement more than one NERD system, the process is quite exhaustive and prone to failure. In addition, industrial solutions demand critical requirements, e.g., large-scale processing, completeness, versatility, and licenses. Commonly, these requirements impose a limitation, making good NERD models to be ignored by companies. This paper presents TANKER, a distributed architecture which aims to overcome scalability, reliability and failure tolerance limitations related to industrial needs by combining NERD systems. To this end, TANKER relies on a micro-services oriented architecture, which enables agile development and delivery of complex enterprise applications. In addition, TANKER provides a standardized API which makes possible to combine several NERD systems at once.