 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWineGraph: A Graph Representation For Food-Wine Pairing
Jun 27, 2024


We present WineGraph, an extended version of FlavorGraph, a heterogeneous graph incorporating wine data into its structure. This integration enables food-wine pairing based on taste and sommelier-defined rules. Leveraging a food dataset comprising 500,000 reviews and a wine reviews dataset with over 130,000 entries, we computed taste descriptors for both food and wine. This information was then utilised to pair food items with wine and augment FlavorGraph with additional data. The results demonstrate the potential of heterogeneous graphs to acquire supplementary information, proving beneficial for wine pairing.
TASTEset -- Recipe Dataset and Food Entities Recognition Benchmark
Apr 16, 2022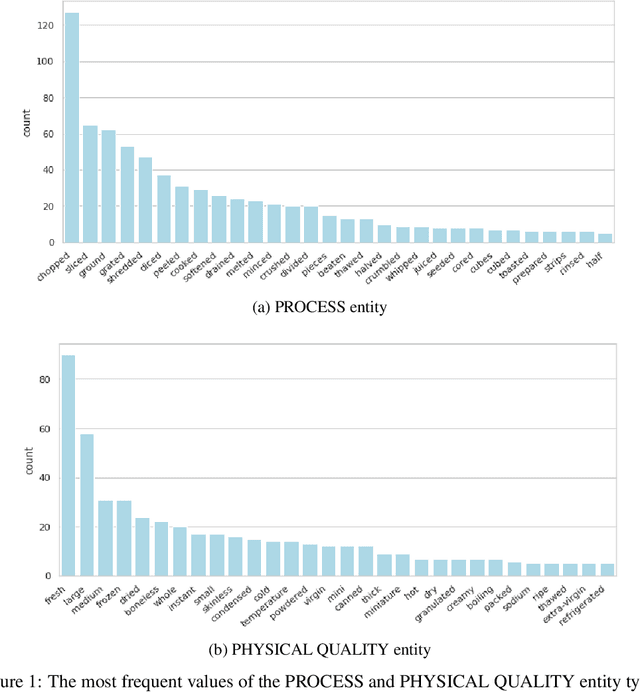
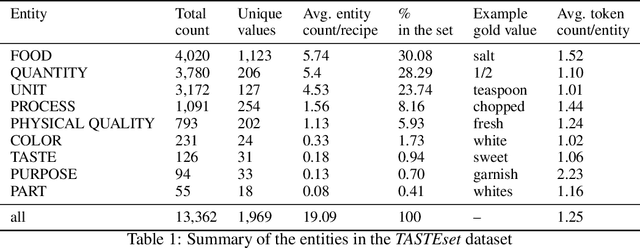
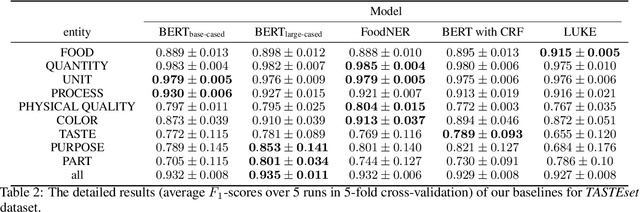
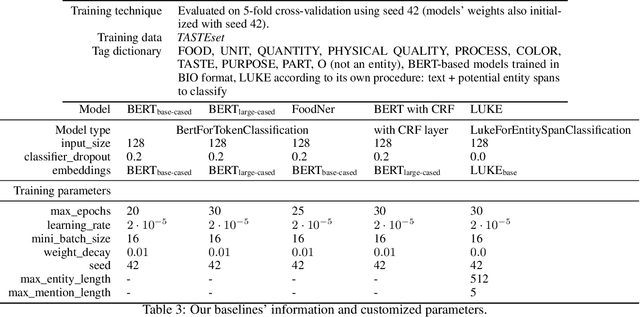
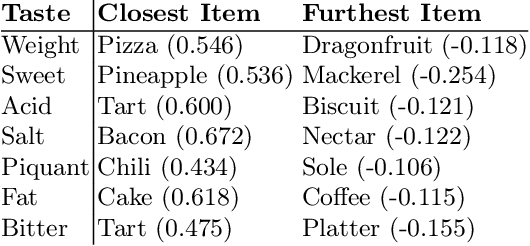
Food Computing is currently a fast-growing field of research. Natural language processing (NLP) is also increasingly essential in this field, especially for recognising food entities. However, there are still only a few well-defined tasks that serve as benchmarks for solutions in this area. We introduce a new dataset -- called \textit{TASTEset} -- to bridge this gap. In this dataset, Named Entity Recognition (NER) models are expected to find or infer various types of entities helpful in processing recipes, e.g.~food products, quantities and their units, names of cooking processes, physical quality of ingredients, their purpose, taste. The dataset consists of 700 recipes with more than 13,000 entities to extract. We provide a few state-of-the-art baselines of named entity recognition models, which show that our dataset poses a solid challenge to existing models. The best model achieved, on average, 0.95 $F_1$ score, depending on the entity type -- from 0.781 to 0.982. We share the dataset and the task to encourage progress on more in-depth and complex information extraction from recipes.
BigCQ: A large-scale synthetic dataset of competency question patterns formalized into SPARQL-OWL query templates
May 20, 2021
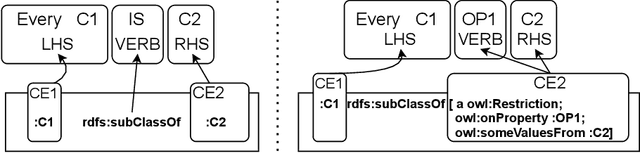

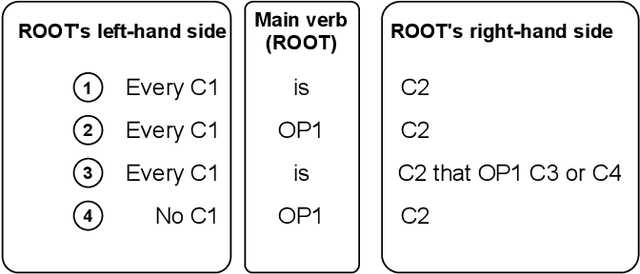
Competency Questions (CQs) are used in many ontology engineering methodologies to collect requirements and track the completeness and correctness of an ontology being constructed. Although they are frequently suggested by ontology engineering methodologies, the publicly available datasets of CQs and their formalizations in ontology query languages are very scarce. Since first efforts to automate processes utilizing CQs are being made, it is of high importance to provide large and diverse datasets to fuel these solutions. In this paper, we present BigCQ, the biggest dataset of CQ templates with their formalizations into SPARQL-OWL query templates. BigCQ is created automatically from a dataset of frequently used axiom shapes. These pairs of CQ templates and query templates can be then materialized as actual CQs and SPARQL-OWL queries if filled with resource labels and IRIs from a given ontology. We describe the dataset in detail, provide a description of the process leading to the creation of the dataset and analyze how well the dataset covers real-world examples. We also publish the dataset as well as scripts transforming axiom shapes into pairs of CQ patterns and SPARQL-OWL templates, to make engineers able to adapt the process to their particular needs.
ML-Schema: Exposing the Semantics of Machine Learning with Schemas and Ontologies
Jul 14, 2018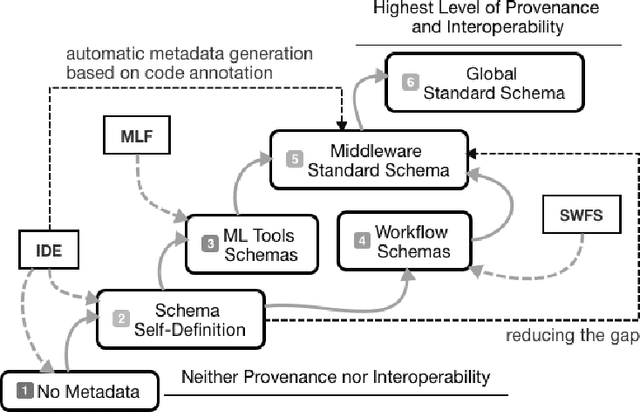
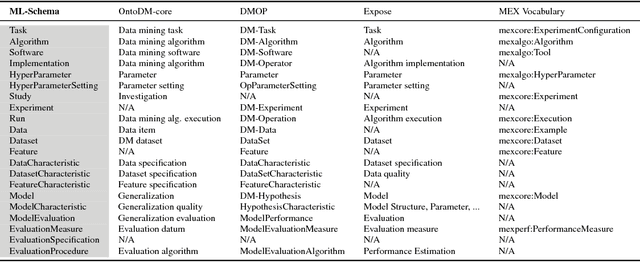
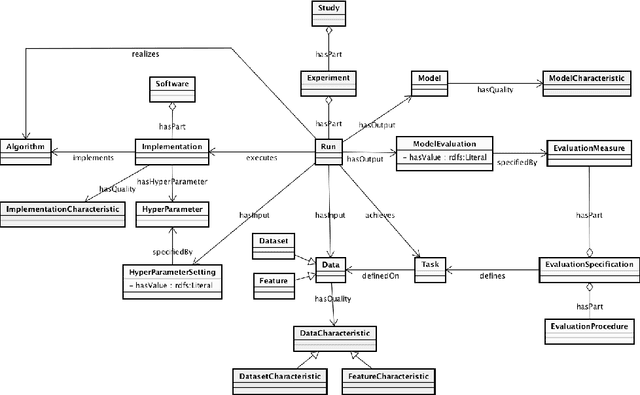
The ML-Schema, proposed by the W3C Machine Learning Schema Community Group, is a top-level ontology that provides a set of classes, properties, and restrictions for representing and interchanging information on machine learning algorithms, datasets, and experiments. It can be easily extended and specialized and it is also mapped to other more domain-specific ontologies developed in the area of machine learning and data mining. In this paper we overview existing state-of-the-art machine learning interchange formats and present the first release of ML-Schema, a canonical format resulted of more than seven years of experience among different research institutions. We argue that exposing semantics of machine learning algorithms, models, and experiments through a canonical format may pave the way to better interpretability and to realistically achieve the full interoperability of experiments regardless of platform or adopted workflow solution.
Swift Linked Data Miner: Mining OWL 2 EL class expressions directly from online RDF datasets
Oct 19, 2017
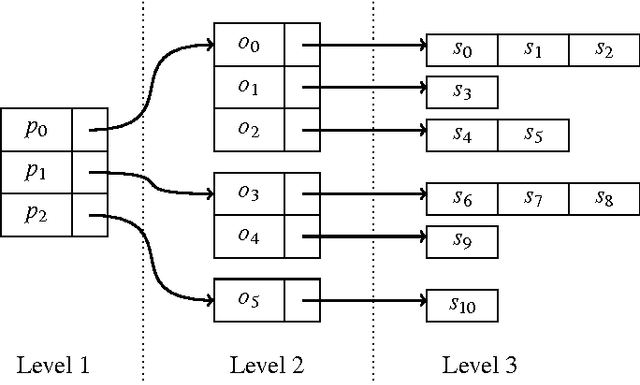

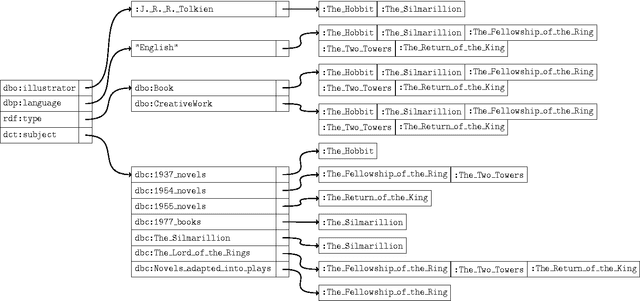
In this study, we present Swift Linked Data Miner, an interruptible algorithm that can directly mine an online Linked Data source (e.g., a SPARQL endpoint) for OWL 2 EL class expressions to extend an ontology with new SubClassOf: axioms. The algorithm works by downloading only a small part of the Linked Data source at a time, building a smart index in the memory and swiftly iterating over the index to mine axioms. We propose a transformation function from mined axioms to RDF Data Shapes. We show, by means of a crowdsourcing experiment, that most of the axioms mined by Swift Linked Data Miner are correct and can be added to an ontology. We provide a ready to use Prot\'eg\'e plugin implementing the algorithm, to support ontology engineers in their daily modeling work.