 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality versus speed in energy demand prediction for district heating systems
May 10, 2022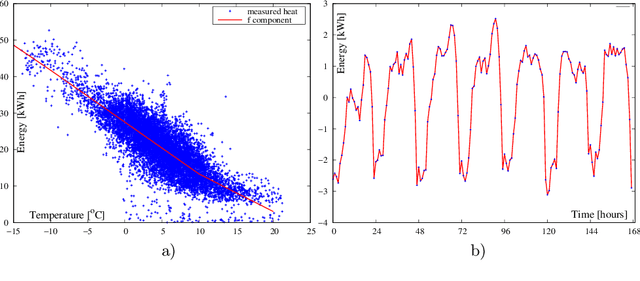
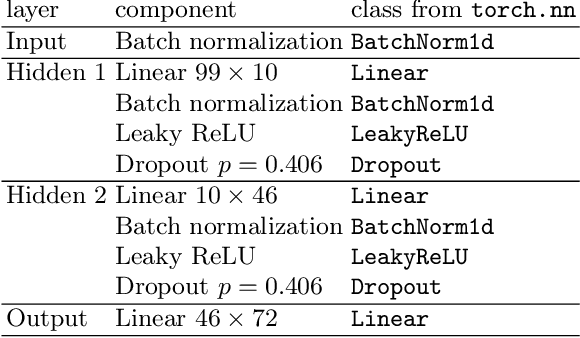
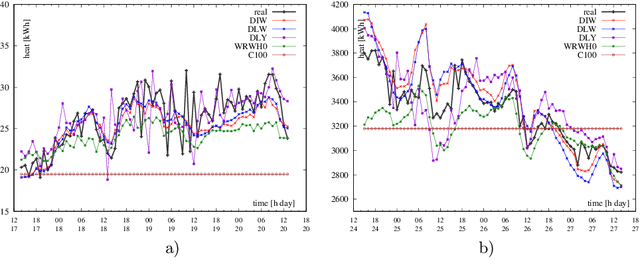
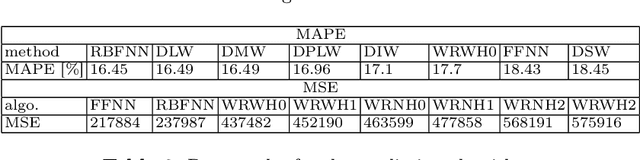
In this paper, we consider energy demand prediction in district heating systems. Effective energy demand prediction is essential in combined heat power systems when offering electrical energy in competitive electricity markets. To address this problem, we propose two sets of algorithms: (1) a novel extension to the algorithm proposed by E. Dotzauer and (2) an autoregressive predictor based on hour-of-week adjusted linear regression on moving averages of energy consumption. These two methods are compared against state-of-the-art artificial neural networks. Energy demand predictor algorithms have various computational costs and prediction quality. While prediction quality is a widely used measure of predictor superiority, computational costs are less frequently analyzed and their impact is not so extensively studied. When predictor algorithms are constantly updated using new data, some computationally expensive forecasting methods may become inapplicable. The computational costs can be split into training and execution parts. The execution part is the cost paid when the already trained algorithm is applied to predict something. In this paper, we evaluate the above methods with respect to the quality and computational costs, both in the training and in the execution. The comparison is conducted on a real-world dataset from a district heating system in the northwest part of Poland.
Competency Questions and SPARQL-OWL Queries Dataset and Analysis
Nov 23, 2018
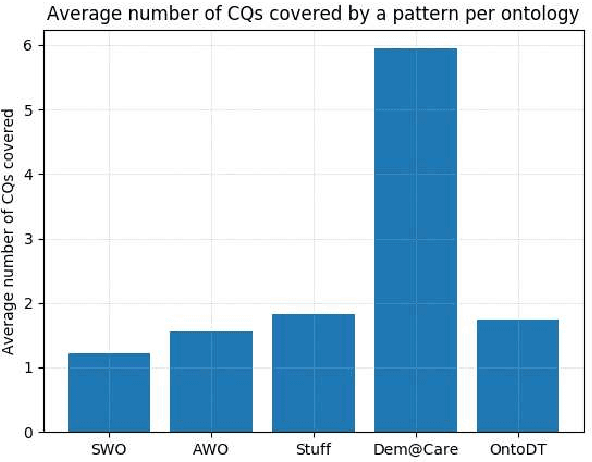
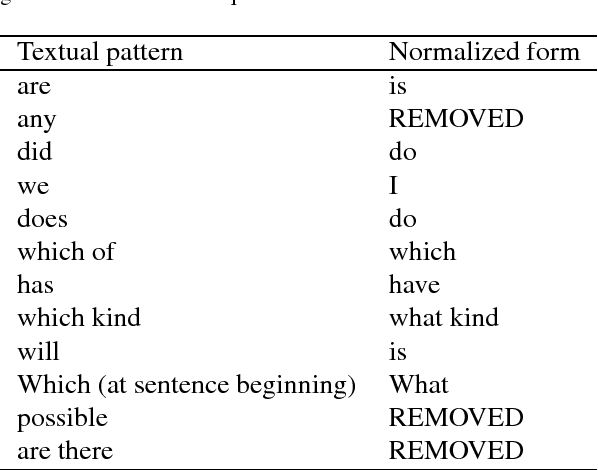
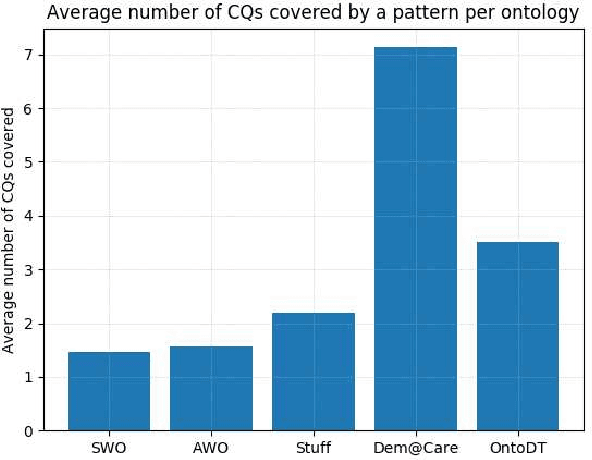
Competency Questions (CQs) are natural language questions outlining and constraining the scope of knowledge represented by an ontology. Despite that CQs are a part of several ontology engineering methodologies, we have observed that the actual publication of CQs for the available ontologies is very limited and even scarcer is the publication of their respective formalisations in terms of, e.g., SPARQL queries. This paper aims to contribute to addressing the engineering shortcomings of using CQs in ontology development, to facilitate wider use of CQs. In order to understand the relation between CQs and the queries over the ontology to test the CQs on an ontology, we gather, analyse, and publicly release a set of 234 CQs and their translations to SPARQL-OWL for several ontologies in different domains developed by different groups. We analysed the CQs in two principal ways. The first stage focused on a linguistic analysis of the natural language text itself, i.e., a lexico-syntactic analysis without any presuppositions of ontology elements, and a subsequent step of semantic analysis in order to find patterns. This increased diversity of CQ sources resulted in a 5-fold increase of hitherto published patterns, to 106 distinct CQ patterns, which have a limited subset of few patterns shared across the CQ sets from the different ontologies. Next, we analysed the relation between the found CQ patterns and the 46 SPARQL-OWL query signatures, which revealed that one CQ pattern may be realised by more than one SPARQL-OWL query signature, and vice versa. We hope that our work will contribute to establishing common practices, templates, automation, and user tools that will support CQ formulation, formalisation, execution, and general management.
Swift Linked Data Miner: Mining OWL 2 EL class expressions directly from online RDF datasets
Oct 19, 2017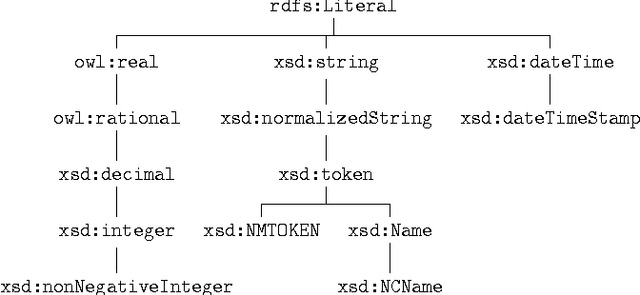
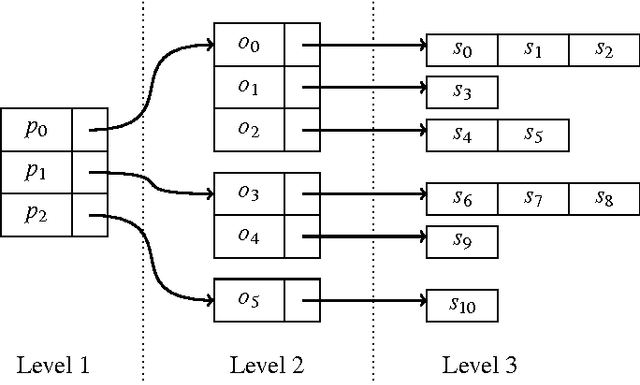

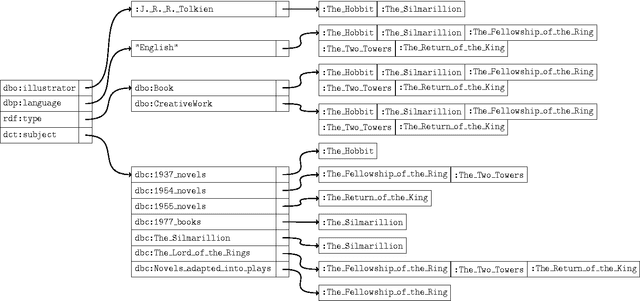
In this study, we present Swift Linked Data Miner, an interruptible algorithm that can directly mine an online Linked Data source (e.g., a SPARQL endpoint) for OWL 2 EL class expressions to extend an ontology with new SubClassOf: axioms. The algorithm works by downloading only a small part of the Linked Data source at a time, building a smart index in the memory and swiftly iterating over the index to mine axioms. We propose a transformation function from mined axioms to RDF Data Shapes. We show, by means of a crowdsourcing experiment, that most of the axioms mined by Swift Linked Data Miner are correct and can be added to an ontology. We provide a ready to use Prot\'eg\'e plugin implementing the algorithm, to support ontology engineers in their daily modeling work.