 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscerning and Characterising Types of Competency Questions for Ontologies
Dec 18, 2024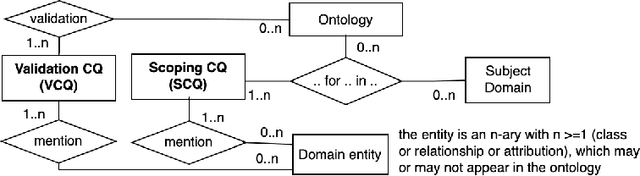
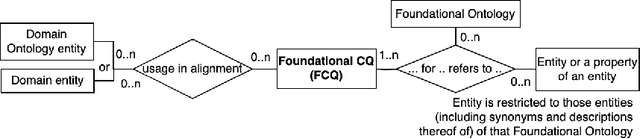
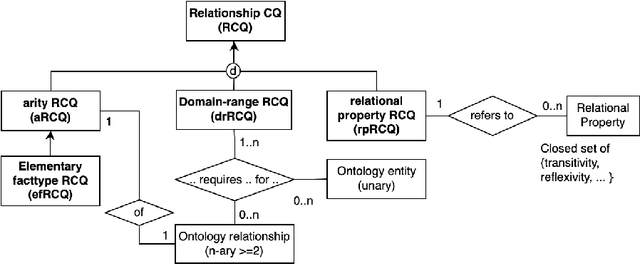
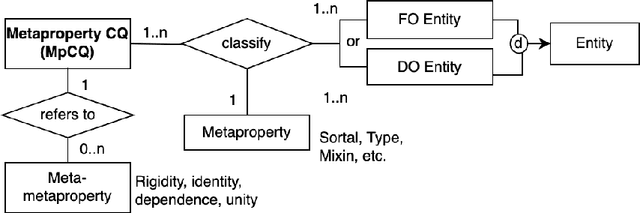
Competency Questions (CQs) are widely used in ontology development by guiding, among others, the scoping and validation stages. However, very limited guidance exists for formulating CQs and assessing whether they are good CQs, leading to issues such as ambiguity and unusable formulations. To solve this, one requires insight into the nature of CQs for ontologies and their constituent parts, as well as which ones are not. We aim to contribute to such theoretical foundations in this paper, which is informed by analysing questions, their uses, and the myriad of ontology development tasks. This resulted in a first Model for Competency Questions, which comprises five main types of CQs, each with a different purpose: Scoping (SCQ), Validating (VCQ), Foundational (FCQ), Relationship (RCQ), and Metaproperty (MpCQ) questions. This model enhances the clarity of CQs and therewith aims to improve on the effectiveness of CQs in ontology development, thanks to their respective identifiable distinct constituent elements. We illustrate and evaluate them with a user story and demonstrate where which type can be used in ontology development tasks. To foster use and research, we created an annotated repository of 438 CQs, the Repository of Ontology Competency QuestionS (ROCQS), incorporating an existing CQ dataset and new CQs and CQ templates, which further demonstrate distinctions among types of CQs.
Contextualising Levels of Language Resourcedness affecting Digital Processing of Text
Sep 29, 2023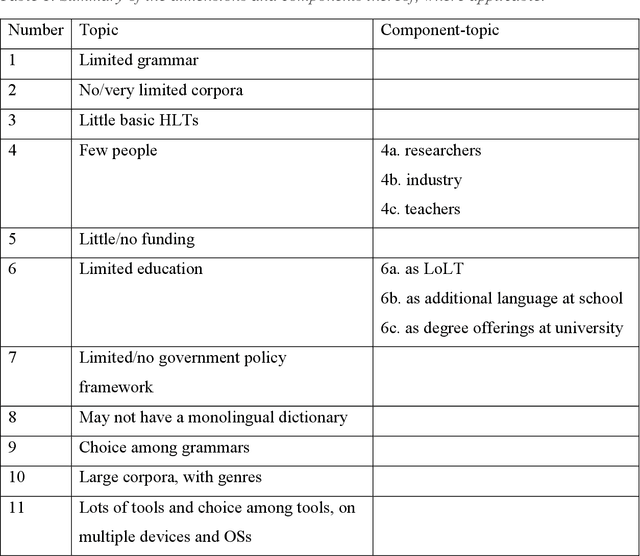
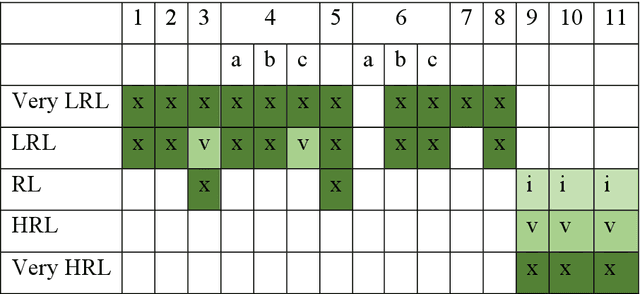
Application domains such as digital humanities and tool like chatbots involve some form of processing natural language, from digitising hardcopies to speech generation. The language of the content is typically characterised as either a low resource language (LRL) or high resource language (HRL), also known as resource-scarce and well-resourced languages, respectively. African languages have been characterized as resource-scarce languages (Bosch et al. 2007; Pretorius & Bosch 2003; Keet & Khumalo 2014) and English is by far the most well-resourced language. Varied language resources are used to develop software systems for these languages to accomplish a wide range of tasks. In this paper we argue that the dichotomous typology LRL and HRL for all languages is problematic. Through a clear understanding of language resources situated in a society, a matrix is developed that characterizes languages as Very LRL, LRL, RL, HRL and Very HRL. The characterization is based on the typology of contextual features for each category, rather than counting tools, and motivation is provided for each feature and each characterization. The contextualisation of resourcedness, with a focus on African languages in this paper, and an increased understanding of where on the scale the language used in a project is, may assist in, among others, better planning of research and implementation projects. We thus argue in this paper that the characterization of language resources within a given scale in a project is an indispensable component particularly in the context of low-resourced languages.
CoSMo: A constructor specification language for Abstract Wikipedia's content selection process
Aug 01, 2023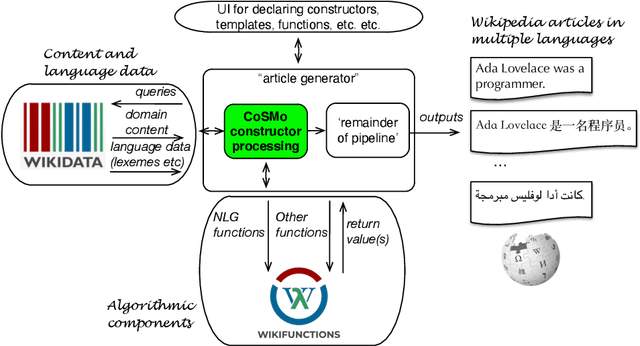
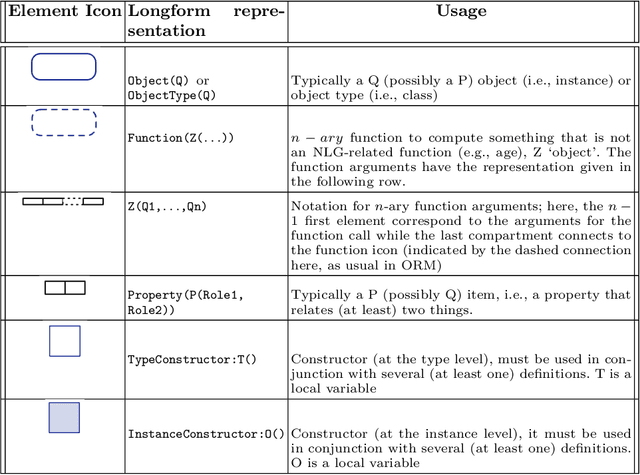
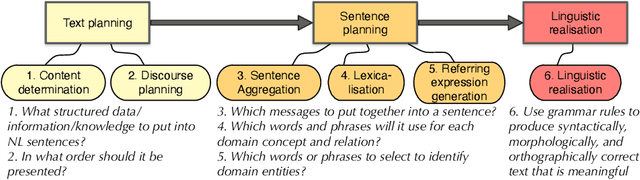
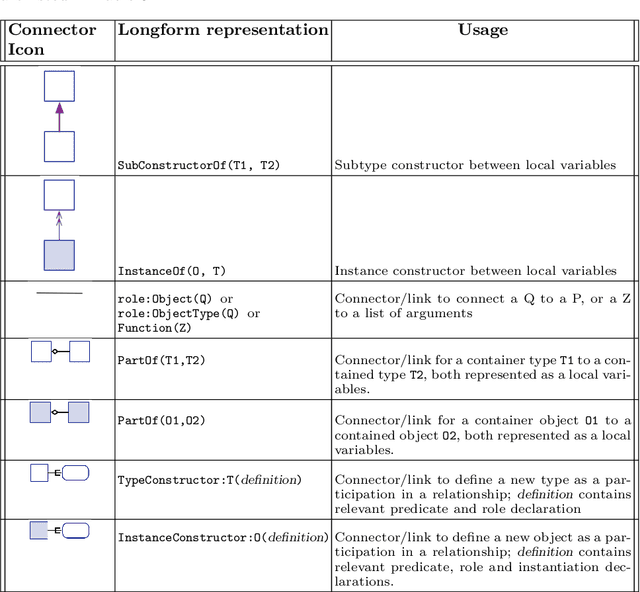
Representing snippets of information abstractly is a task that needs to be performed for various purposes, such as database view specification and the first stage in the natural language generation pipeline for generative AI from structured input, i.e., the content selection stage to determine what needs to be verbalised. For the Abstract Wikipedia project, requirements analysis revealed that such an abstract representation requires multilingual modelling, content selection covering declarative content and functions, and both classes and instances. There is no modelling language that meets either of the three features, let alone a combination. Following a rigorous language design process inclusive of broad stakeholder consultation, we created CoSMo, a novel {\sc Co}ntent {\sc S}election {\sc Mo}deling language that meets these and other requirements so that it may be useful both in Abstract Wikipedia as well as other contexts. We describe the design process, rationale and choices, the specification, and preliminary evaluation of the language.
A Review of Multilingualism in and for Ontologies
Oct 06, 2022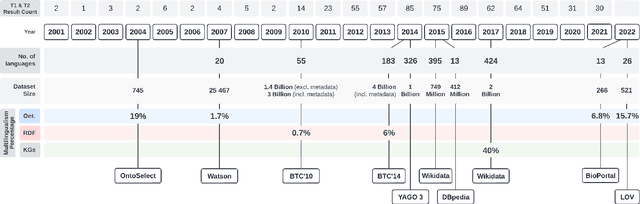
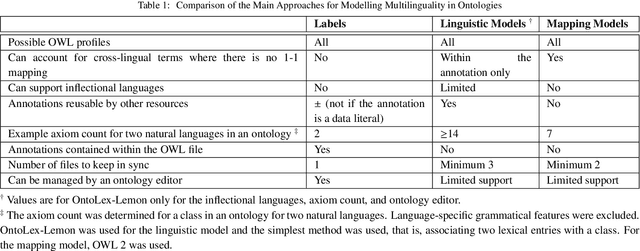
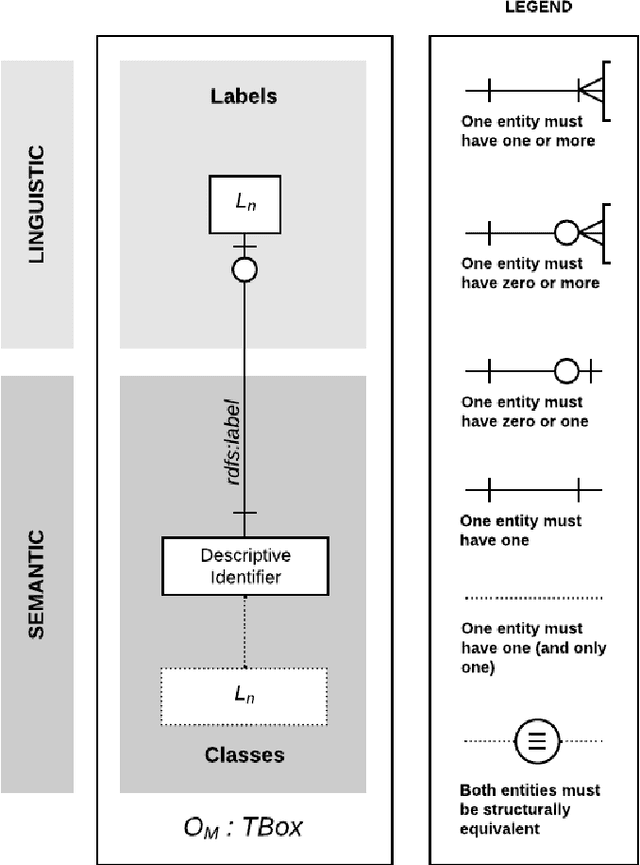

The Multilingual Semantic Web has been in focus for over a decade. Multilingualism in Linked Data and RDF has shown substantial adoption, but this is unclear for ontologies since the last review 15 years ago. One of the design goals for OWL was internationalisation, with the aim that an ontology is usable across languages and cultures. Much research to improve on multilingual ontologies has taken place in the meantime, and presumably multilingual linked data could use multilingual ontologies. Therefore, this review seeks to (i) elucidate and compare the modelling options for multilingual ontologies, (ii) examine extant ontologies for their multilingualism, and (iii) evaluate ontology editors for their ability to manage a multilingual ontology. Nine different principal approaches for modelling multilinguality in ontologies were identified, which fall into either of the following approaches: using multilingual labels, linguistic models, or a mapping-based approach. They are compared on design by means of an ad hoc visualisation mode of modelling multilingual information for ontologies, shortcomings, and what issues they aim to solve. For the ontologies, we extracted production-level and accessible ontologies from BioPortal and the LOV repositories, which had, at best, 6.77% and 15.74% multilingual ontologies, respectively, where most of them have only partial translations and they all use a labels-based approach only. Based on a set of nine tool requirements for managing multilingual ontologies, the assessment of seven relevant ontology editors showed that there are significant gaps in tooling support, with VocBench 3 nearest of meeting them all. This stock-taking may function as a new baseline and motivate new research directions for multilingual ontologies.
An evaluation of template and ML-based generation of user-readable text from a knowledge graph
Jun 06, 2021
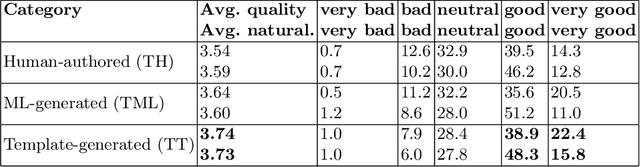
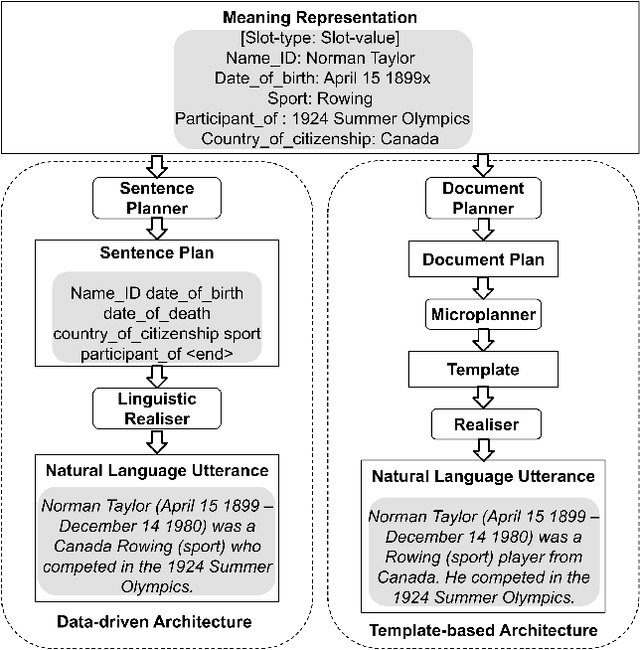
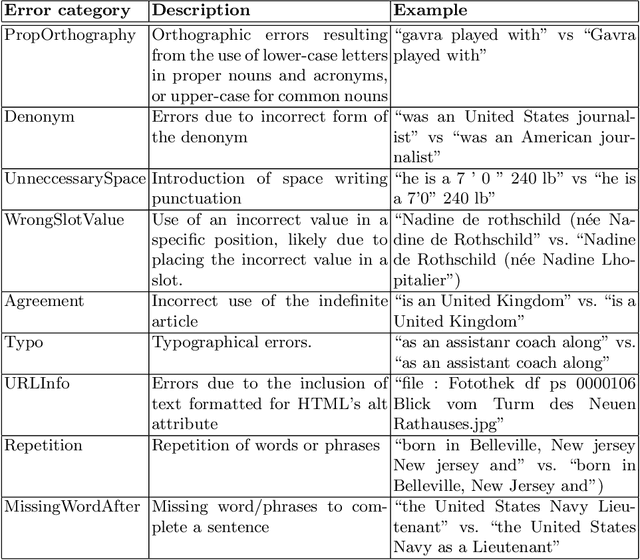
Typical user-friendly renderings of knowledge graphs are visualisations and natural language text. Within the latter HCI solution approach, data-driven natural language generation systems receive increased attention, but they are often outperformed by template-based systems due to suffering from errors such as content dropping, hallucination, or repetition. It is unknown which of those errors are associated significantly with low quality judgements by humans who the text is aimed for, which hampers addressing errors based on their impact on improving human evaluations. We assessed their possible association with an experiment availing of expert and crowdsourced evaluations of human authored text, template generated text, and sequence-to-sequence model generated text. The results showed that there was no significant association between human authored texts with errors and the low human judgements of naturalness and quality. There was also no significant association between machine learning generated texts with dropped or hallucinated slots and the low human judgements of naturalness and quality. Thus, both approaches appear to be viable options for designing a natural language interface for knowledge graphs.
Bias in ontologies -- a preliminary assessment
Jan 20, 2021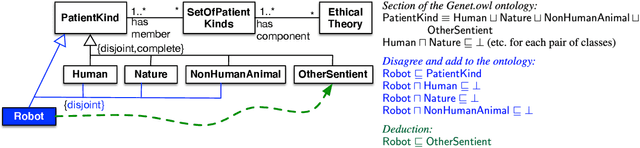
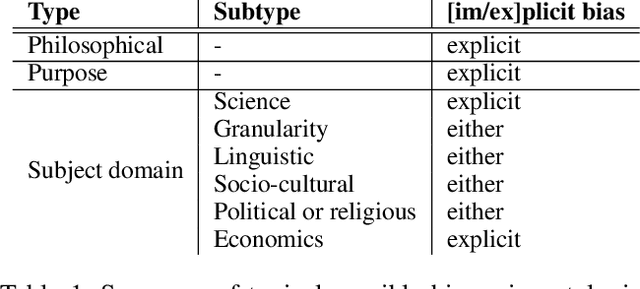
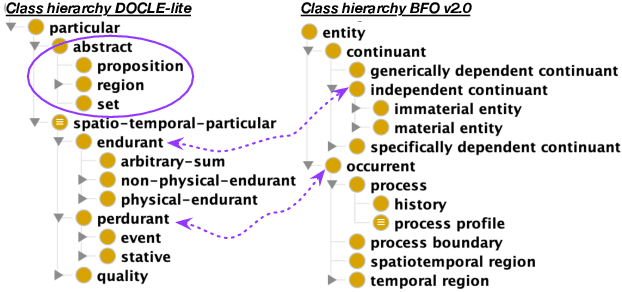
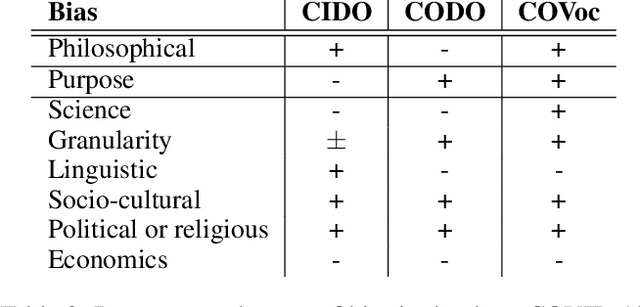
Logical theories in the form of ontologies and similar artefacts in computing and IT are used for structuring, annotating, and querying data, among others, and therewith influence data analytics regarding what is fed into the algorithms. Algorithmic bias is a well-known notion, but what does bias mean in the context of ontologies that provide a structuring mechanism for an algorithm's input? What are the sources of bias there and how would they manifest themselves in ontologies? We examine and enumerate types of bias relevant for ontologies, and whether they are explicit or implicit. These eight types are illustrated with examples from extant production-level ontologies and samples from the literature. We then assessed three concurrently developed COVID-19 ontologies on bias and detected different subsets of types of bias in each one, to a greater or lesser extent. This first characterisation aims contribute to a sensitisation of ethical aspects of ontologies primarily regarding representation of information and knowledge.
Why a computer program is a functional whole
Jul 21, 2020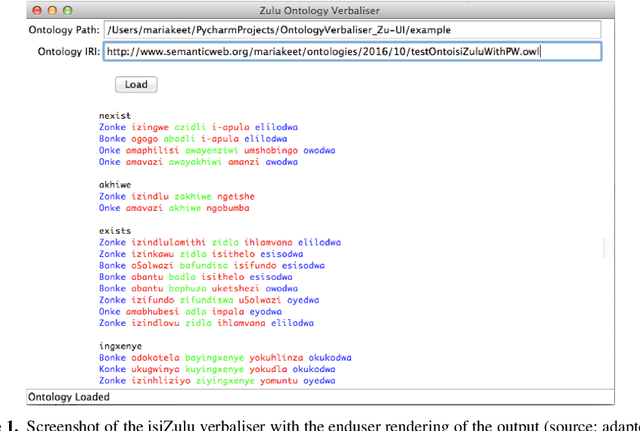
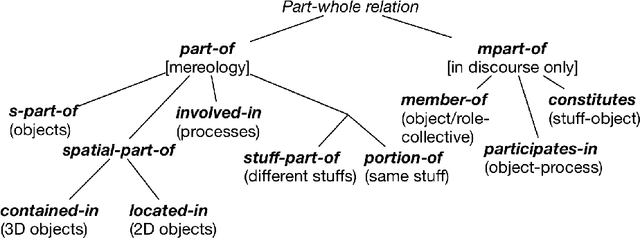
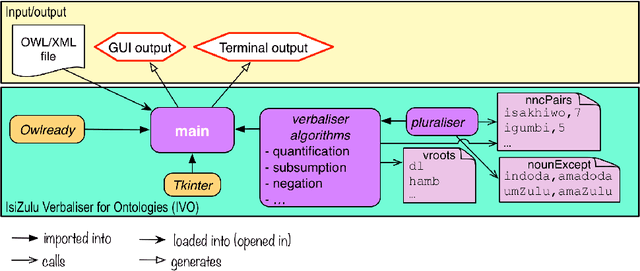

Sharing, downloading, and reusing software is common-place, some of which is carried out legally with open source software. When it is not legal, it is unclear just how many copyright infringements and trade secret violations have taken place: does an infringement count for the artefact as a whole or perhaps for each file of the program? To answer this question, it must first be established whether a program should be considered as an integral whole, a collection, or a mere set of distinct files, and why. We argue that a program is a functional whole, availing of, and combining, arguments from mereology, granularity, modularity, unity, and function to substantiate the claim. The argumentation and answer contributes to the ontology of software artefacts, may assist industry in litigation cases, and demonstrates that the notion of unifying relation is operationalisable. Indirectly, it provides support for continued modular design of artefacts following established engineering practices.
Toward equipping Artificial Moral Agents with multiple ethical theories
Mar 02, 2020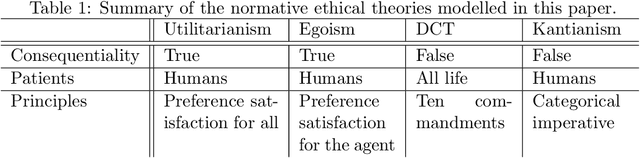
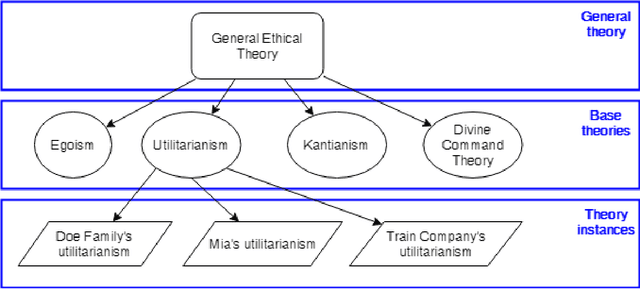
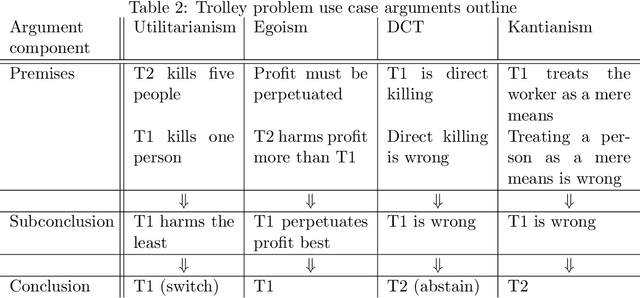
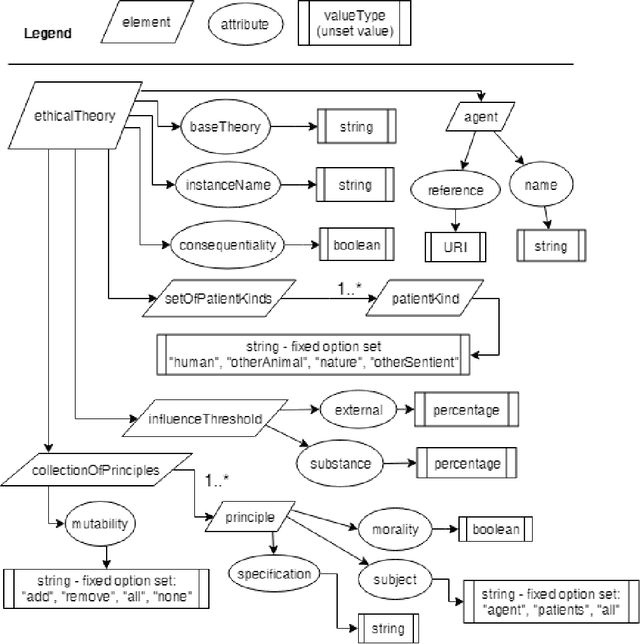
Artificial Moral Agents (AMA's) is a field in computer science with the purpose of creating autonomous machines that can make moral decisions akin to how humans do. Researchers have proposed theoretical means of creating such machines, while philosophers have made arguments as to how these machines ought to behave, or whether they should even exist. Of the currently theorised AMA's, all research and design has been done with either none or at most one specified normative ethical theory as basis. This is problematic because it narrows down the AMA's functional ability and versatility which in turn causes moral outcomes that a limited number of people agree with (thereby undermining an AMA's ability to be moral in a human sense). As solution we design a three-layer model for general normative ethical theories that can be used to serialise the ethical views of people and businesses for an AMA to use during reasoning. Four specific ethical norms (Kantianism, divine command theory, utilitarianism, and egoism) were modelled and evaluated as proof of concept for normative modelling. Furthermore, all models were serialised to XML/XSD as proof of support for computerisation.
CLaRO: a Data-driven CNL for Specifying Competency Questions
Jul 17, 2019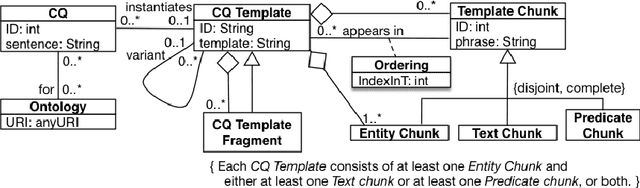
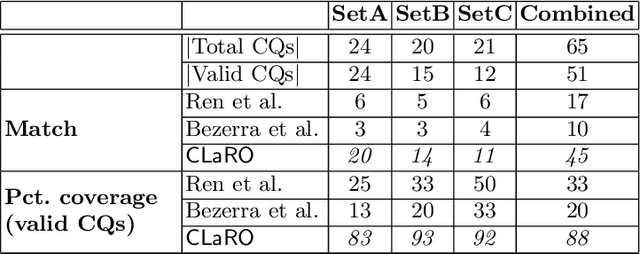
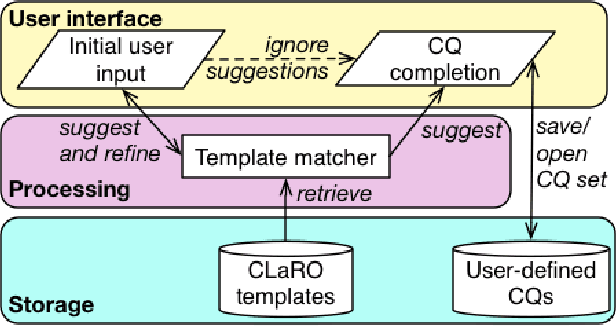
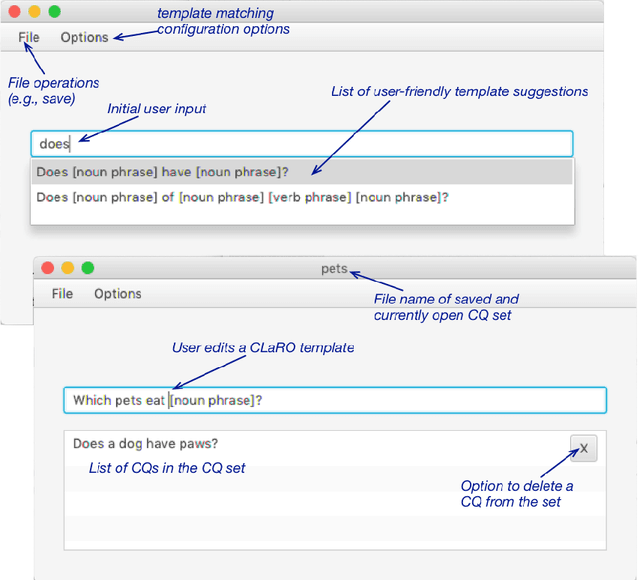
Competency Questions (CQs) for an ontology and similar artefacts aim to provide insights into the contents of an ontology and to demarcate its scope. The absence of a controlled natural language, tooling and automation to support the authoring of CQs has hampered their effective use in ontology development and evaluation. The few question templates that exists are based on informal analyses of a small number of CQs and have limited coverage of question types and sentence constructions. We aim to fill this gap by proposing a template-based CNL to author CQs, called CLaRO. For its design, we exploited a new dataset of 234 CQs that had been processed automatically into 106 patterns, which we analysed and used to design a template-based CNL, with an additional CNL model and XML serialisation. The CNL was evaluated with a subset of questions from the original dataset and with two sets of newly sourced CQs. The coverage of CLaRO, with its 93 main templates and 41 linguistic variants, is about 90% for unseen questions. CLaRO has the potential to facilitate streamlining formalising ontology content requirements and, given that about one third of the competency questions in the test sets turned out to be invalid questions, assist in writing good questions.
More Effective Ontology Authoring with Test-Driven Development
Dec 14, 2018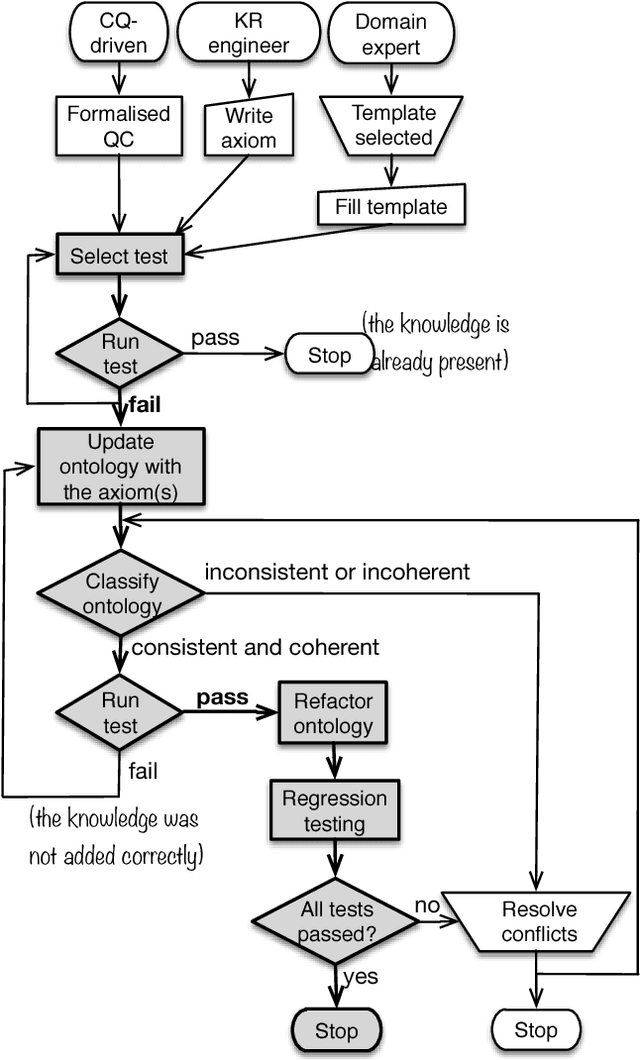
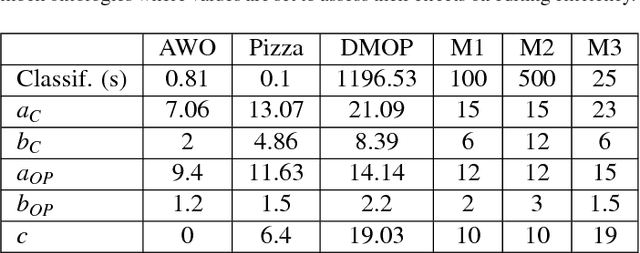
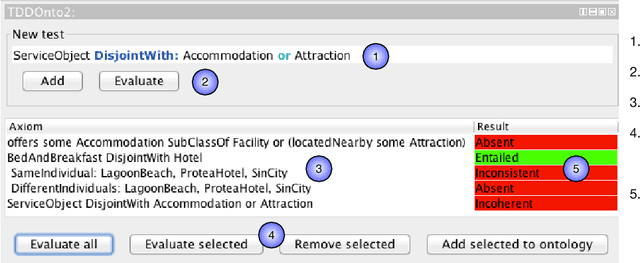
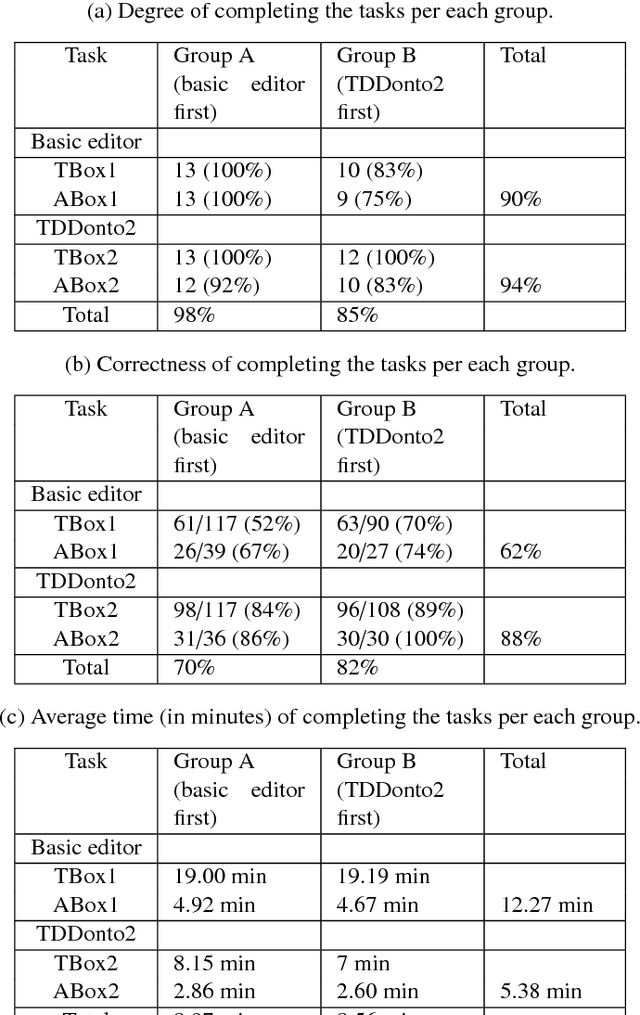
Ontology authoring is a complex process, where commonly the automated reasoner is invoked for verification of newly introduced changes, therewith amounting to a time-consuming test-last approach. Test-Driven Development (TDD) for ontology authoring is a recent {\em test-first} approach that aims to reduce authoring time and increase authoring efficiency. Current TDD testing falls short on coverage of OWL features and possible test outcomes, the rigorous foundation thereof, and evaluations to ascertain its effectiveness. We aim to address these issues in one instantiation of TDD for ontology authoring. We first propose a succinct, logic-based model of TDD testing and present novel TDD algorithms so as to cover also any OWL 2 class expression for the TBox and for the principal ABox assertions, and prove their correctness. The algorithms use methods from the OWL API directly such that reclassification is not necessary for test execution, therewith reducing ontology authoring time. The algorithms were implemented in TDDonto2, a Prot\'eg\'e plugin. TDDonto2 was evaluated on editing efficiency and by users. The editing efficiency study demonstrated that it is faster than a typical ontology authoring interface, especially for medium size and large ontologies. The user evaluation demonstrated that modellers make significantly less errors with TDDonto2 compared to the standard Prot\'eg\'e interface and complete their tasks better using less time. Thus, the results indicate that Test-Driven Development is a promising approach in an ontology development methodology.