 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualising Levels of Language Resourcedness affecting Digital Processing of Text
Paper and Code
Sep 29, 2023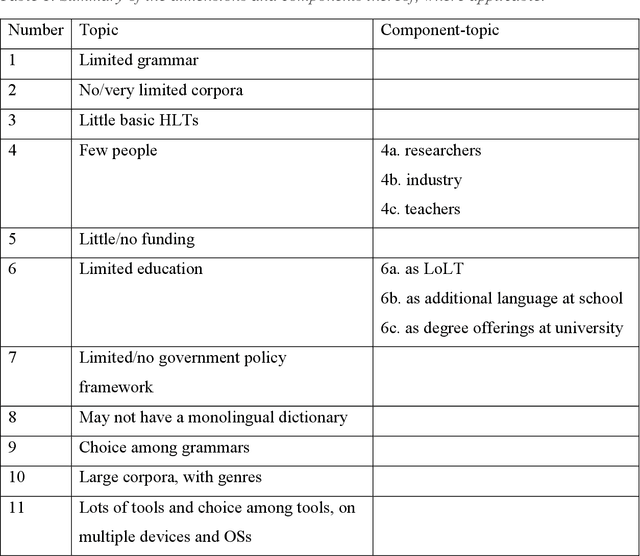
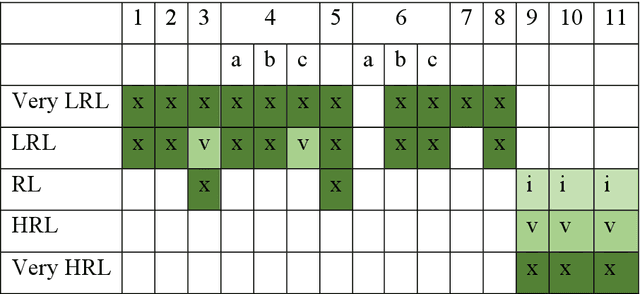
Application domains such as digital humanities and tool like chatbots involve some form of processing natural language, from digitising hardcopies to speech generation. The language of the content is typically characterised as either a low resource language (LRL) or high resource language (HRL), also known as resource-scarce and well-resourced languages, respectively. African languages have been characterized as resource-scarce languages (Bosch et al. 2007; Pretorius & Bosch 2003; Keet & Khumalo 2014) and English is by far the most well-resourced language. Varied language resources are used to develop software systems for these languages to accomplish a wide range of tasks. In this paper we argue that the dichotomous typology LRL and HRL for all languages is problematic. Through a clear understanding of language resources situated in a society, a matrix is developed that characterizes languages as Very LRL, LRL, RL, HRL and Very HRL. The characterization is based on the typology of contextual features for each category, rather than counting tools, and motivation is provided for each feature and each characterization. The contextualisation of resourcedness, with a focus on African languages in this paper, and an increased understanding of where on the scale the language used in a project is, may assist in, among others, better planning of research and implementation projects. We thus argue in this paper that the characterization of language resources within a given scale in a project is an indispensable component particularly in the context of low-resourced languages.