 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn evaluation of template and ML-based generation of user-readable text from a knowledge graph
Paper and Code

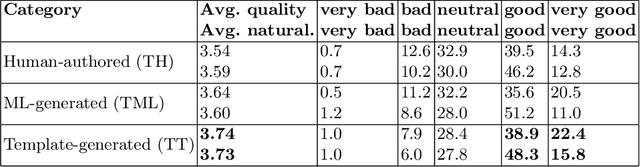
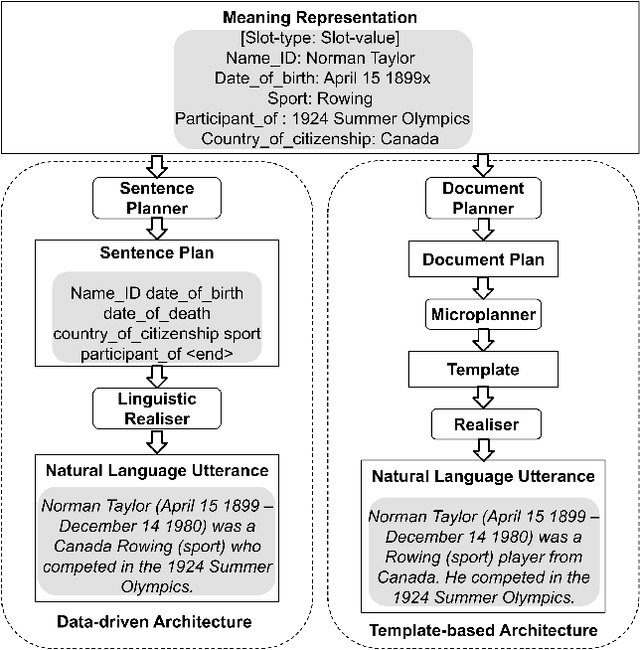
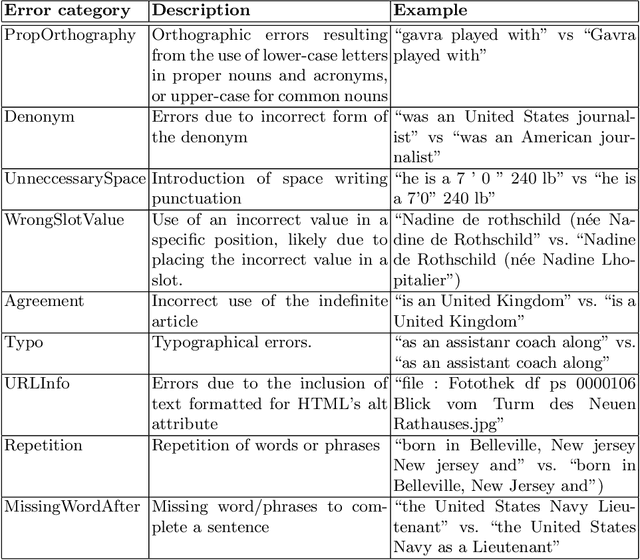
Typical user-friendly renderings of knowledge graphs are visualisations and natural language text. Within the latter HCI solution approach, data-driven natural language generation systems receive increased attention, but they are often outperformed by template-based systems due to suffering from errors such as content dropping, hallucination, or repetition. It is unknown which of those errors are associated significantly with low quality judgements by humans who the text is aimed for, which hampers addressing errors based on their impact on improving human evaluations. We assessed their possible association with an experiment availing of expert and crowdsourced evaluations of human authored text, template generated text, and sequence-to-sequence model generated text. The results showed that there was no significant association between human authored texts with errors and the low human judgements of naturalness and quality. There was also no significant association between machine learning generated texts with dropped or hallucinated slots and the low human judgements of naturalness and quality. Thus, both approaches appear to be viable options for designing a natural language interface for knowledge graphs.