 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Differentiating Between Failures and Domain Shifts in Industrial Data Streams
Mar 09, 2026Anomaly and failure detection methods are crucial in identifying deviations from normal system operational conditions, which allows for actions to be taken in advance, usually preventing more serious damages. Long-lasting deviations indicate failures, while sudden, isolated changes in the data indicate anomalies. However, in many practical applications, changes in the data do not always represent abnormal system states. Such changes may be recognized incorrectly as failures, while being a normal evolution of the system, e.g. referring to characteristics of starting the processing of a new product, i.e. realizing a domain shift. Therefore, distinguishing between failures and such ''healthy'' changes in data distribution is critical to ensure the practical robustness of the system. In this paper, we propose a method that not only detects changes in the data distribution and anomalies but also allows us to distinguish between failures and normal domain shifts inherent to a given process. The proposed method consists of a modified Page-Hinkley changepoint detector for identification of the domain shift and possible failures and supervised domain-adaptation-based algorithms for fast, online anomaly detection. These two are coupled with an explainable artificial intelligence (XAI) component that aims at helping the human operator to finally differentiate between domain shifts and failures. The method is illustrated by an experiment on a data stream from the steel factory.
An interpretable prototype parts-based neural network for medical tabular data
Mar 05, 2026The ability to interpret machine learning model decisions is critical in such domains as healthcare, where trust in model predictions is as important as their accuracy. Inspired by the development of prototype parts-based deep neural networks in computer vision, we propose a new model for tabular data, specifically tailored to medical records, that requires discretization of diagnostic result norms. Unlike the original vision models that rely on the spatial structure, our method employs trainable patching over features describing a patient, to learn meaningful prototypical parts from structured data. These parts are represented as binary or discretized feature subsets. This allows the model to express prototypes in human-readable terms, enabling alignment with clinical language and case-based reasoning. Our proposed neural network is inherently interpretable and offers interpretable concept-based predictions by comparing the patient's description to learned prototypes in the latent space of the network. In experiments, we demonstrate that the model achieves classification performance competitive to widely used baseline models on medical benchmark datasets, while also offering transparency, bridging the gap between predictive performance and interpretability in clinical decision support.
Explaining Concept Drift through the Evolution of Group Counterfactuals
Sep 11, 2025



Machine learning models in dynamic environments often suffer from concept drift, where changes in the data distribution degrade performance. While detecting this drift is a well-studied topic, explaining how and why the model's decision-making logic changes still remains a significant challenge. In this paper, we introduce a novel methodology to explain concept drift by analyzing the temporal evolution of group-based counterfactual explanations (GCEs). Our approach tracks shifts in the GCEs' cluster centroids and their associated counterfactual action vectors before and after a drift. These evolving GCEs act as an interpretable proxy, revealing structural changes in the model's decision boundary and its underlying rationale. We operationalize this analysis within a three-layer framework that synergistically combines insights from the data layer (distributional shifts), the model layer (prediction disagreement), and our proposed explanation layer. We show that such holistic view allows for a more comprehensive diagnosis of drift, making it possible to distinguish between different root causes, such as a spatial data shift versus a re-labeling of concepts.
This part looks alike this: identifying important parts of explained instances and prototypes
May 08, 2025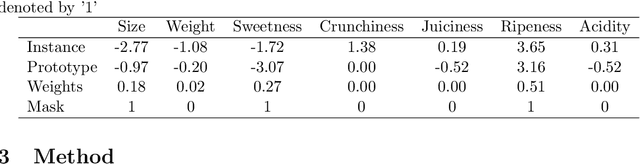
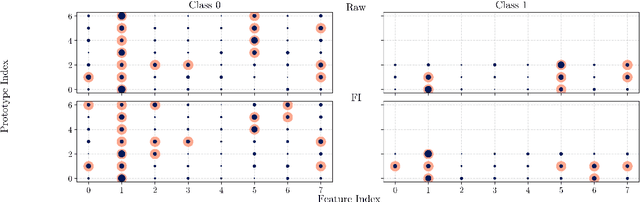
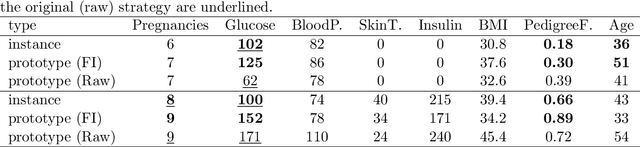
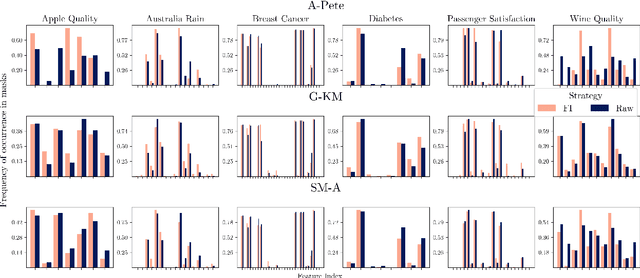
Although prototype-based explanations provide a human-understandable way of representing model predictions they often fail to direct user attention to the most relevant features. We propose a novel approach to identify the most informative features within prototypes, termed alike parts. Using feature importance scores derived from an agnostic explanation method, it emphasizes the most relevant overlapping features between an instance and its nearest prototype. Furthermore, the feature importance score is incorporated into the objective function of the prototype selection algorithms to promote global prototypes diversity. Through experiments on six benchmark datasets, we demonstrate that the proposed approach improves user comprehension while maintaining or even increasing predictive accuracy.
DetoxAI: a Python Toolkit for Debiasing Deep Learning Models in Computer Vision
May 02, 2025While machine learning fairness has made significant progress in recent years, most existing solutions focus on tabular data and are poorly suited for vision-based classification tasks, which rely heavily on deep learning. To bridge this gap, we introduce DetoxAI, an open-source Python library for improving fairness in deep learning vision classifiers through post-hoc debiasing. DetoxAI implements state-of-the-art debiasing algorithms, fairness metrics, and visualization tools. It supports debiasing via interventions in internal representations and includes attribution-based visualization tools and quantitative algorithmic fairness metrics to show how bias is mitigated. This paper presents the motivation, design, and use cases of DetoxAI, demonstrating its tangible value to engineers and researchers.
Properties of fairness measures in the context of varying class imbalance and protected group ratios
Nov 13, 2024
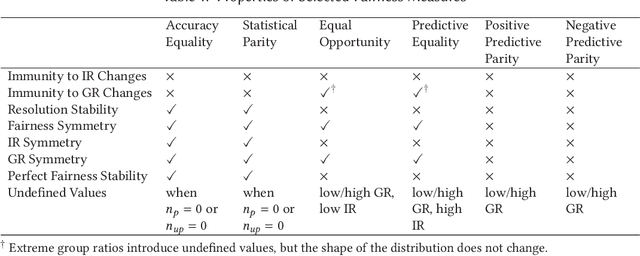

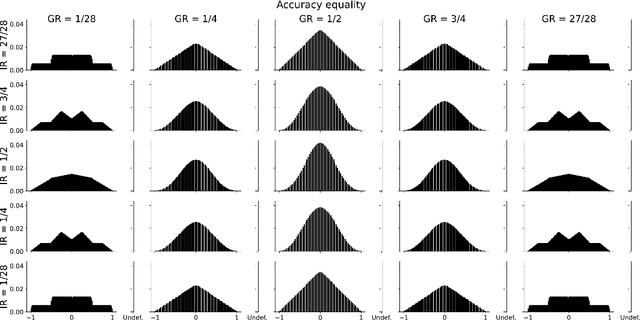
Society is increasingly relying on predictive models in fields like criminal justice, credit risk management, or hiring. To prevent such automated systems from discriminating against people belonging to certain groups, fairness measures have become a crucial component in socially relevant applications of machine learning. However, existing fairness measures have been designed to assess the bias between predictions for protected groups without considering the imbalance in the classes of the target variable. Current research on the potential effect of class imbalance on fairness focuses on practical applications rather than dataset-independent measure properties. In this paper, we study the general properties of fairness measures for changing class and protected group proportions. For this purpose, we analyze the probability mass functions of six of the most popular group fairness measures. We also measure how the probability of achieving perfect fairness changes for varying class imbalance ratios. Moreover, we relate the dataset-independent properties of fairness measures described in this paper to classifier fairness in real-life tasks. Our results show that measures such as Equal Opportunity and Positive Predictive Parity are more sensitive to changes in class imbalance than Accuracy Equality. These findings can help guide researchers and practitioners in choosing the most appropriate fairness measures for their classification problems.
Improving Online Bagging for Complex Imbalanced Data Stream
Oct 04, 2024Learning classifiers from imbalanced and concept drifting data streams is still a challenge. Most of the current proposals focus on taking into account changes in the global imbalance ratio only and ignore the local difficulty factors, such as the minority class decomposition into sub-concepts and the presence of unsafe types of examples (borderline or rare ones). As the above factors present in the stream may deteriorate the performance of popular online classifiers, we propose extensions of resampling online bagging, namely Neighbourhood Undersampling or Oversampling Online Bagging to take better account of the presence of unsafe minority examples. The performed computational experiments with synthetic complex imbalanced data streams have shown their advantage over earlier variants of online bagging resampling ensembles.
Counterfactual Explanations with Probabilistic Guarantees on their Robustness to Model Change
Aug 09, 2024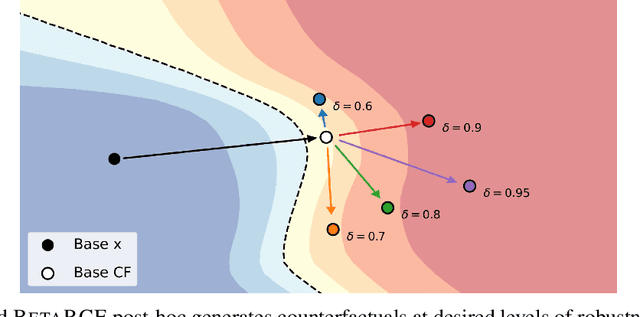
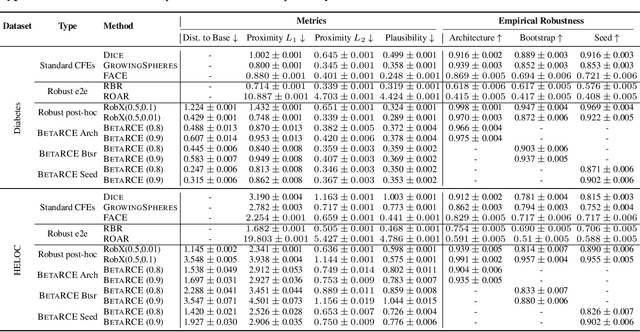
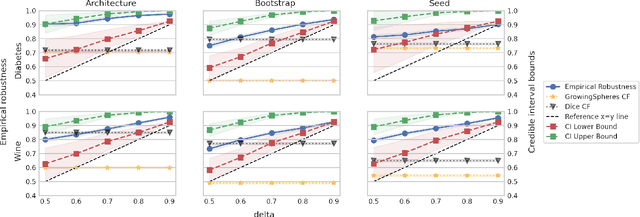
Counterfactual explanations (CFEs) guide users on how to adjust inputs to machine learning models to achieve desired outputs. While existing research primarily addresses static scenarios, real-world applications often involve data or model changes, potentially invalidating previously generated CFEs and rendering user-induced input changes ineffective. Current methods addressing this issue often support only specific models or change types, require extensive hyperparameter tuning, or fail to provide probabilistic guarantees on CFE robustness to model changes. This paper proposes a novel approach for generating CFEs that provides probabilistic guarantees for any model and change type, while offering interpretable and easy-to-select hyperparameters. We establish a theoretical framework for probabilistically defining robustness to model change and demonstrate how our BetaRCE method directly stems from it. BetaRCE is a post-hoc method applied alongside a chosen base CFE generation method to enhance the quality of the explanation beyond robustness. It facilitates a transition from the base explanation to a more robust one with user-adjusted probability bounds. Through experimental comparisons with baselines, we show that BetaRCE yields robust, most plausible, and closest to baseline counterfactual explanations.
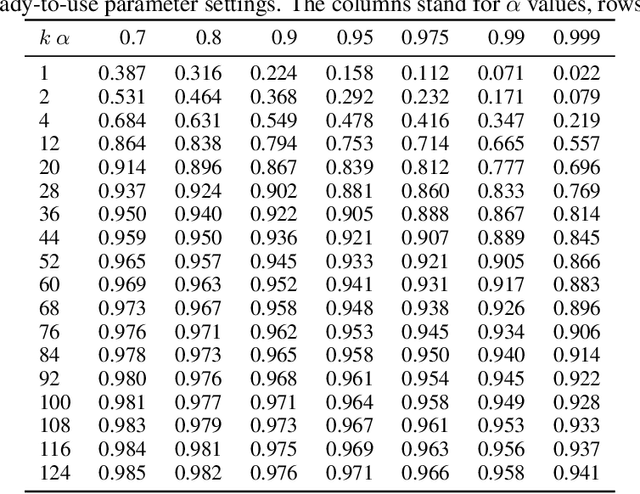
A-PETE: Adaptive Prototype Explanations of Tree Ensembles
May 31, 2024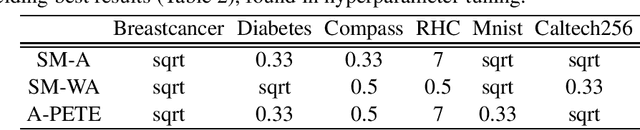
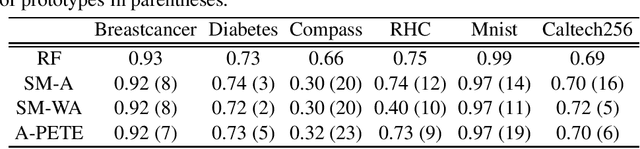
The need for interpreting machine learning models is addressed through prototype explanations within the context of tree ensembles. An algorithm named Adaptive Prototype Explanations of Tree Ensembles (A-PETE) is proposed to automatise the selection of prototypes for these classifiers. Its unique characteristics is using a specialised distance measure and a modified k-medoid approach. Experiments demonstrated its competitive predictive accuracy with respect to earlier explanation algorithms. It also provides a a sufficient number of prototypes for the purpose of interpreting the random forest classifier.
Unifying Perspectives: Plausible Counterfactual Explanations on Global, Group-wise, and Local Levels
May 27, 2024Growing regulatory and societal pressures demand increased transparency in AI, particularly in understanding the decisions made by complex machine learning models. Counterfactual Explanations (CFs) have emerged as a promising technique within Explainable AI (xAI), offering insights into individual model predictions. However, to understand the systemic biases and disparate impacts of AI models, it is crucial to move beyond local CFs and embrace global explanations, which offer a~holistic view across diverse scenarios and populations. Unfortunately, generating Global Counterfactual Explanations (GCEs) faces challenges in computational complexity, defining the scope of "global," and ensuring the explanations are both globally representative and locally plausible. We introduce a novel unified approach for generating Local, Group-wise, and Global Counterfactual Explanations for differentiable classification models via gradient-based optimization to address these challenges. This framework aims to bridge the gap between individual and systemic insights, enabling a deeper understanding of model decisions and their potential impact on diverse populations. Our approach further innovates by incorporating a probabilistic plausibility criterion, enhancing actionability and trustworthiness. By offering a cohesive solution to the optimization and plausibility challenges in GCEs, our work significantly advances the interpretability and accountability of AI models, marking a step forward in the pursuit of transparent AI.