 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetoxAI: a Python Toolkit for Debiasing Deep Learning Models in Computer Vision
May 02, 2025While machine learning fairness has made significant progress in recent years, most existing solutions focus on tabular data and are poorly suited for vision-based classification tasks, which rely heavily on deep learning. To bridge this gap, we introduce DetoxAI, an open-source Python library for improving fairness in deep learning vision classifiers through post-hoc debiasing. DetoxAI implements state-of-the-art debiasing algorithms, fairness metrics, and visualization tools. It supports debiasing via interventions in internal representations and includes attribution-based visualization tools and quantitative algorithmic fairness metrics to show how bias is mitigated. This paper presents the motivation, design, and use cases of DetoxAI, demonstrating its tangible value to engineers and researchers.
Exploring Loss Design Techniques For Decision Tree Robustness To Label Noise
May 27, 2024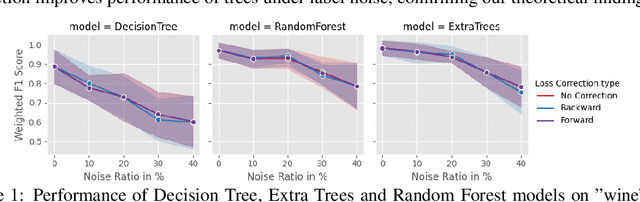
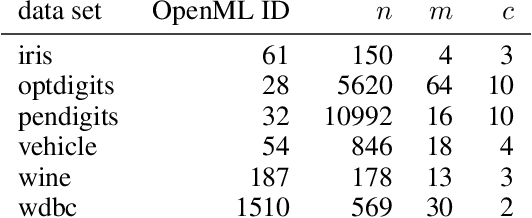
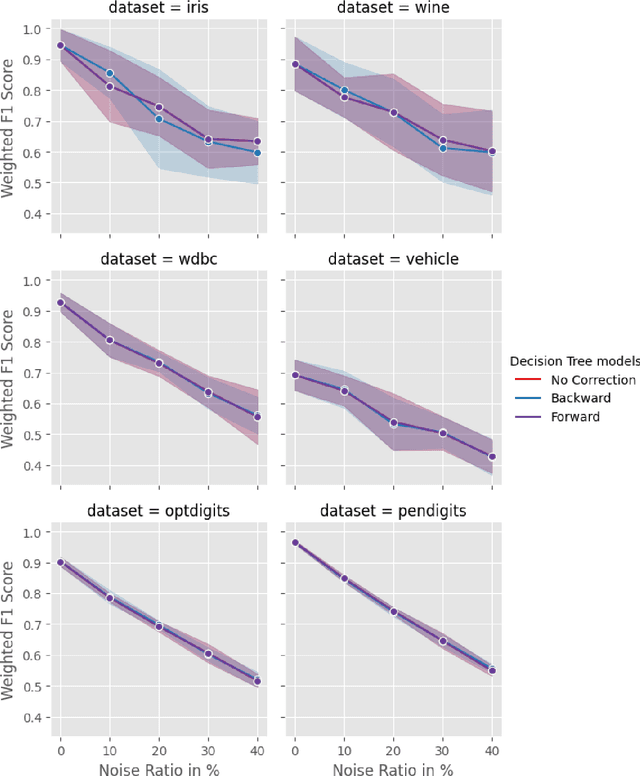

In the real world, data is often noisy, affecting not only the quality of features but also the accuracy of labels. Current research on mitigating label errors stems primarily from advances in deep learning, and a gap exists in exploring interpretable models, particularly those rooted in decision trees. In this study, we investigate whether ideas from deep learning loss design can be applied to improve the robustness of decision trees. In particular, we show that loss correction and symmetric losses, both standard approaches, are not effective. We argue that other directions need to be explored to improve the robustness of decision trees to label noise.