 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality versus speed in energy demand prediction for district heating systems
May 10, 2022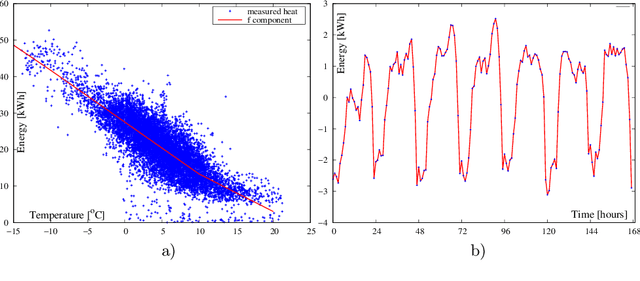
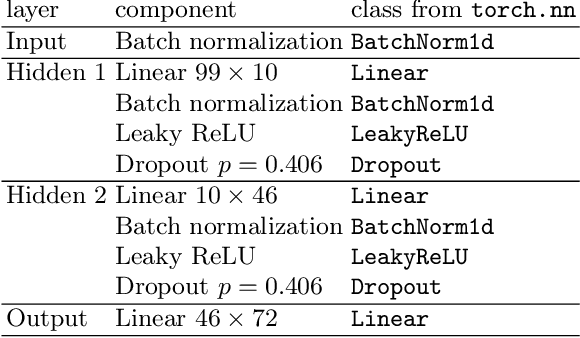
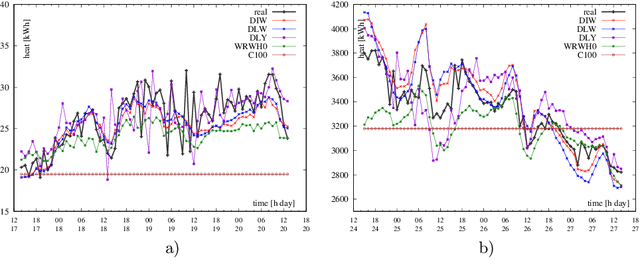
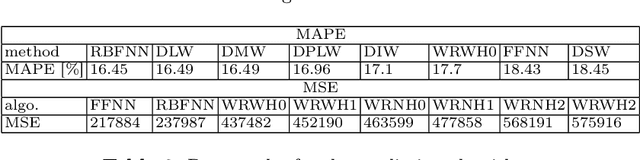
In this paper, we consider energy demand prediction in district heating systems. Effective energy demand prediction is essential in combined heat power systems when offering electrical energy in competitive electricity markets. To address this problem, we propose two sets of algorithms: (1) a novel extension to the algorithm proposed by E. Dotzauer and (2) an autoregressive predictor based on hour-of-week adjusted linear regression on moving averages of energy consumption. These two methods are compared against state-of-the-art artificial neural networks. Energy demand predictor algorithms have various computational costs and prediction quality. While prediction quality is a widely used measure of predictor superiority, computational costs are less frequently analyzed and their impact is not so extensively studied. When predictor algorithms are constantly updated using new data, some computationally expensive forecasting methods may become inapplicable. The computational costs can be split into training and execution parts. The execution part is the cost paid when the already trained algorithm is applied to predict something. In this paper, we evaluate the above methods with respect to the quality and computational costs, both in the training and in the execution. The comparison is conducted on a real-world dataset from a district heating system in the northwest part of Poland.
PRESISTANT: Learning based assistant for data pre-processing
Mar 02, 2018



Data pre-processing is one of the most time consuming and relevant steps in a data analysis process (e.g., classification task). A given data pre-processing operator (e.g., transformation) can have positive, negative or zero impact on the final result of the analysis. Expert users have the required knowledge to find the right pre-processing operators. However, when it comes to non-experts, they are overwhelmed by the amount of pre-processing operators and it is challenging for them to find operators that would positively impact their analysis (e.g., increase the predictive accuracy of a classifier). Existing solutions either assume that users have expert knowledge, or they recommend pre-processing operators that are only "syntactically" applicable to a dataset, without taking into account their impact on the final analysis. In this work, we aim at providing assistance to non-expert users by recommending data pre-processing operators that are ranked according to their impact on the final analysis. We developed a tool PRESISTANT, that uses Random Forests to learn the impact of pre-processing operators on the performance (e.g., predictive accuracy) of 5 different classification algorithms, such as J48, Naive Bayes, PART, Logistic Regression, and Nearest Neighbor. Extensive evaluations on the recommendations provided by our tool, show that PRESISTANT can effectively help non-experts in order to achieve improved results in their analytical tasks.