 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Sequence-to-Sequence Models for SPARQL Pattern Composition
Oct 21, 2020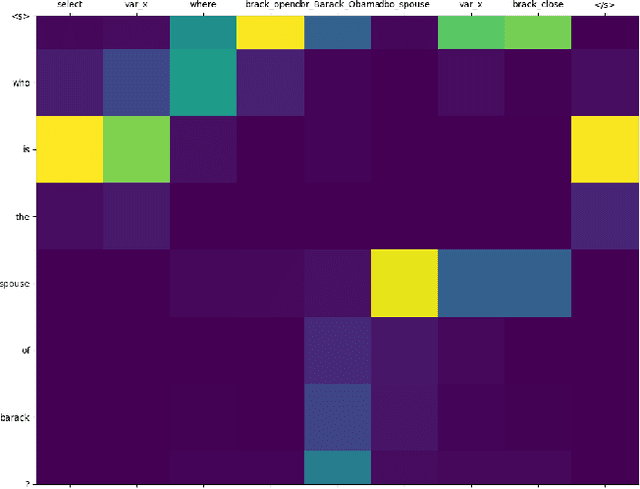
A booming amount of information is continuously added to the Internet as structured and unstructured data, feeding knowledge bases such as DBpedia and Wikidata with billions of statements describing millions of entities. The aim of Question Answering systems is to allow lay users to access such data using natural language without needing to write formal queries. However, users often submit questions that are complex and require a certain level of abstraction and reasoning to decompose them into basic graph patterns. In this short paper, we explore the use of architectures based on Neural Machine Translation called Neural SPARQL Machines to learn pattern compositions. We show that sequence-to-sequence models are a viable and promising option to transform long utterances into complex SPARQL queries.
Where is Linked Data in Question Answering over Linked Data?
May 07, 2020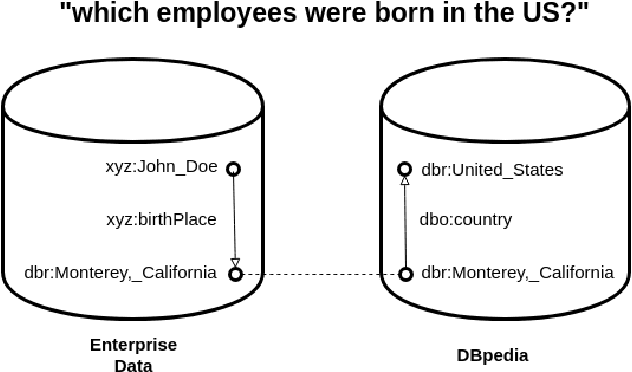
We argue that "Question Answering with Knowledge Base" and "Question Answering over Linked Data" are currently two instances of the same problem, despite one explicitly declares to deal with Linked Data. We point out the lack of existing methods to evaluate question answering on datasets which exploit external links to the rest of the cloud or share common schema. To this end, we propose the creation of new evaluation settings to leverage the advantages of the Semantic Web to achieve AI-complete question answering.
Neural Machine Translation for Query Construction and Composition
Jul 09, 2018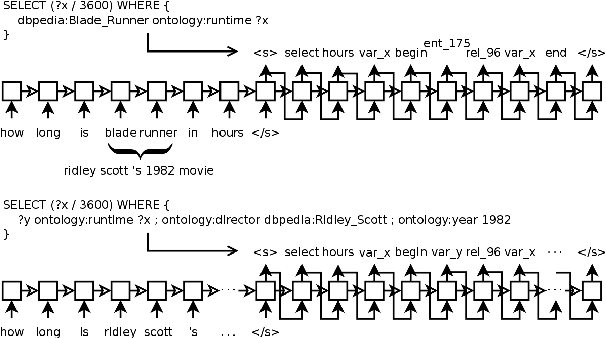
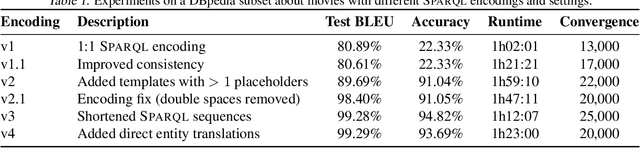

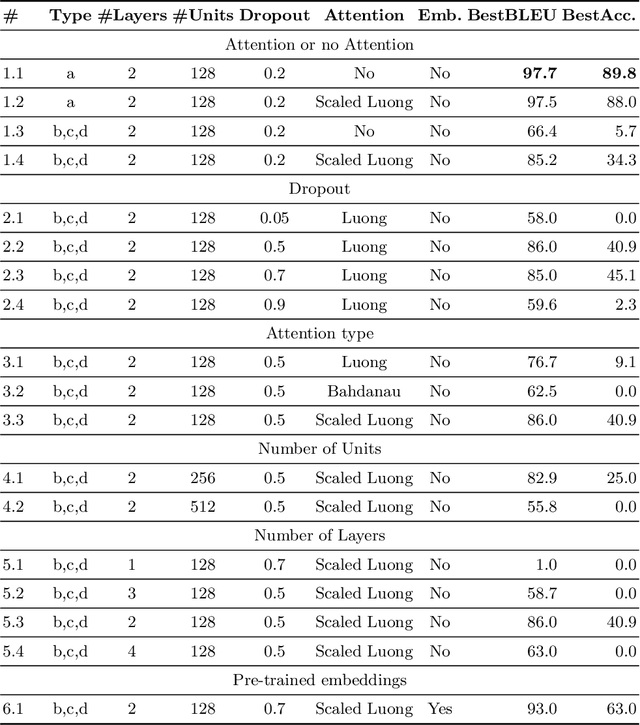
Research on question answering with knowledge base has recently seen an increasing use of deep architectures. In this extended abstract, we study the application of the neural machine translation paradigm for question parsing. We employ a sequence-to-sequence model to learn graph patterns in the SPARQL graph query language and their compositions. Instead of inducing the programs through question-answer pairs, we expect a semi-supervised approach, where alignments between questions and queries are built through templates. We argue that the coverage of language utterances can be expanded using late notable works in natural language generation.
Expeditious Generation of Knowledge Graph Embeddings
Mar 21, 2018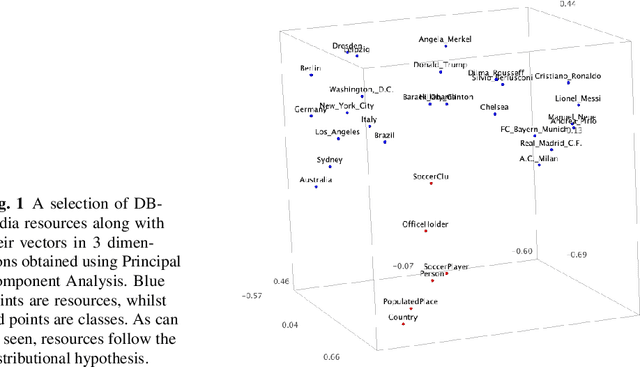
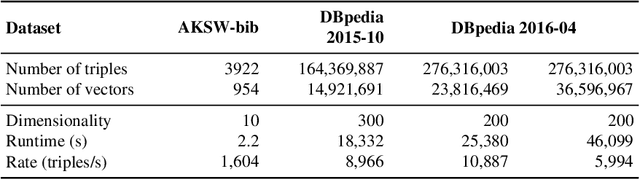
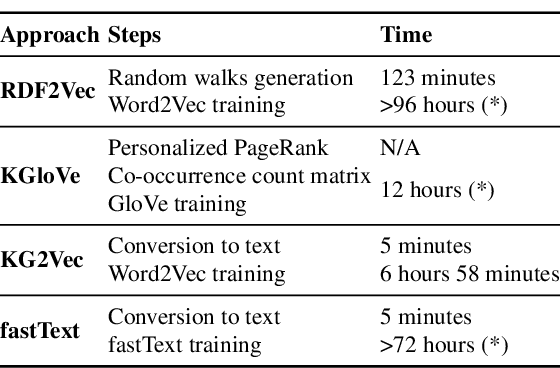
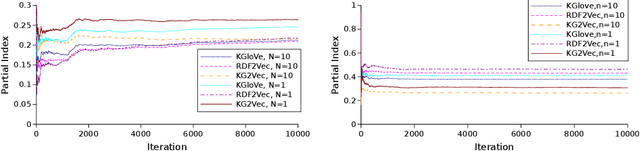
Knowledge Graph Embedding methods aim at representing entities and relations in a knowledge base as points or vectors in a continuous vector space. Several approaches using embeddings have shown promising results on tasks such as link prediction, entity recommendation, question answering, and triplet classification. However, only a few methods can compute low-dimensional embeddings of very large knowledge bases. In this paper, we propose KG2Vec, a novel approach to Knowledge Graph Embedding based on the skip-gram model. Instead of using a predefined scoring function, we learn it relying on Long Short-Term Memories. We evaluated the goodness of our embeddings on knowledge graph completion and show that KG2Vec is comparable to the quality of the scalable state-of-the-art approaches and can process large graphs by parsing more than a hundred million triples in less than 6 hours on common hardware.
Beyond Markov Logic: Efficient Mining of Prediction Rules in Large Graphs
Feb 13, 2018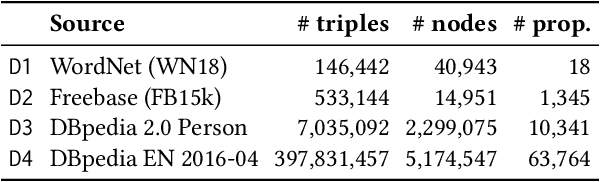
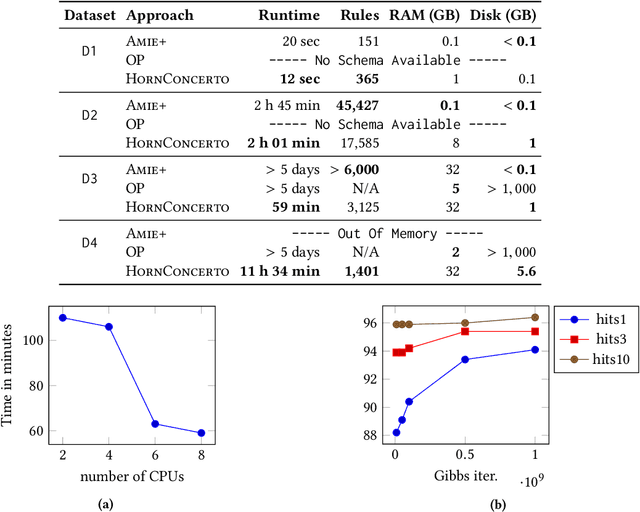
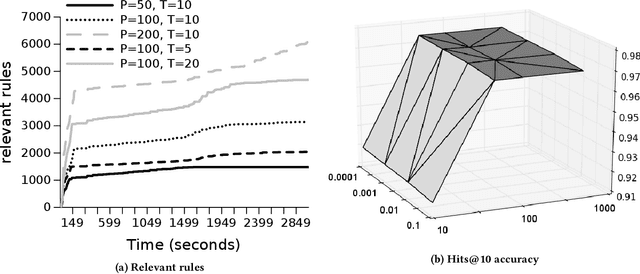
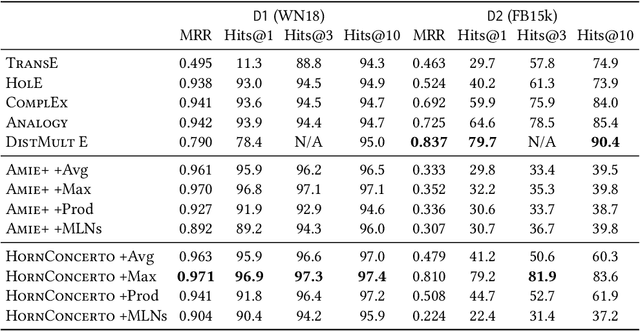
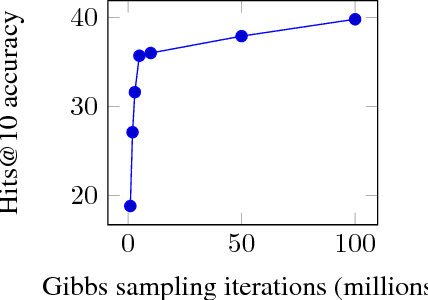
Graph representations of large knowledge bases may comprise billions of edges. Usually built upon human-generated ontologies, several knowledge bases do not feature declared ontological rules and are far from being complete. Current rule mining approaches rely on schemata or store the graph in-memory, which can be unfeasible for large graphs. In this paper, we introduce HornConcerto, an algorithm to discover Horn clauses in large graphs without the need of a schema. Using a standard fact-based confidence score, we can mine close Horn rules having an arbitrary body size. We show that our method can outperform existing approaches in terms of runtime and memory consumption and mine high-quality rules for the link prediction task, achieving state-of-the-art results on a widely-used benchmark. Moreover, we find that rules alone can perform inference significantly faster than embedding-based methods and achieve accuracies on link prediction comparable to resource-demanding approaches such as Markov Logic Networks.
Mandolin: A Knowledge Discovery Framework for the Web of Data
Nov 03, 2017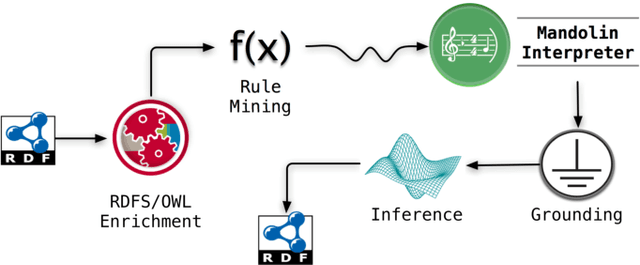

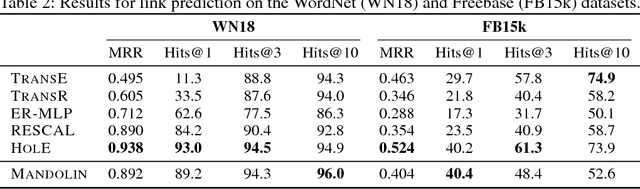
Markov Logic Networks join probabilistic modeling with first-order logic and have been shown to integrate well with the Semantic Web foundations. While several approaches have been devised to tackle the subproblems of rule mining, grounding, and inference, no comprehensive workflow has been proposed so far. In this paper, we fill this gap by introducing a framework called Mandolin, which implements a workflow for knowledge discovery specifically on RDF datasets. Our framework imports knowledge from referenced graphs, creates similarity relationships among similar literals, and relies on state-of-the-art techniques for rule mining, grounding, and inference computation. We show that our best configuration scales well and achieves at least comparable results with respect to other statistical-relational-learning algorithms on link prediction.
SPARQL as a Foreign Language
Aug 25, 2017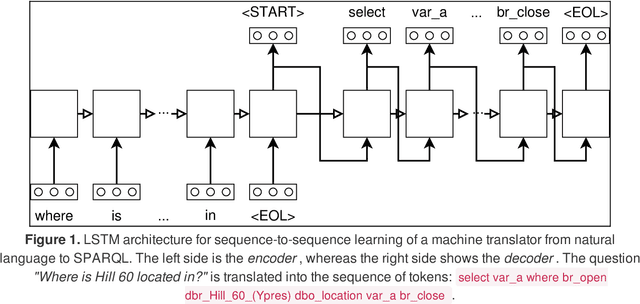

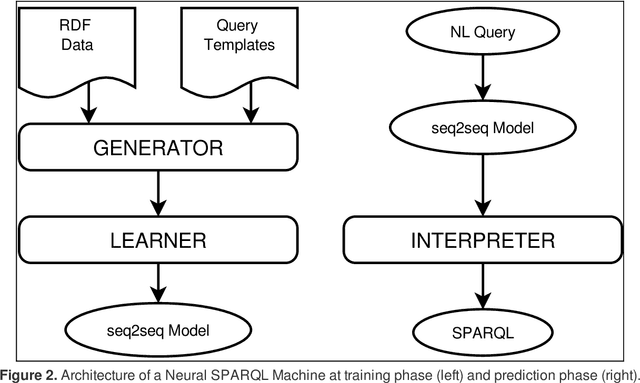

In the last years, the Linked Data Cloud has achieved a size of more than 100 billion facts pertaining to a multitude of domains. However, accessing this information has been significantly challenging for lay users. Approaches to problems such as Question Answering on Linked Data and Link Discovery have notably played a role in increasing information access. These approaches are often based on handcrafted and/or statistical models derived from data observation. Recently, Deep Learning architectures based on Neural Networks called seq2seq have shown to achieve state-of-the-art results at translating sequences into sequences. In this direction, we propose Neural SPARQL Machines, end-to-end deep architectures to translate any natural language expression into sentences encoding SPARQL queries. Our preliminary results, restricted on selected DBpedia classes, show that Neural SPARQL Machines are a promising approach for Question Answering on Linked Data, as they can deal with known problems such as vocabulary mismatch and perform graph pattern composition.