 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Trustworthiness Oracle Generation for Machine Learning Text Classifiers
Oct 30, 2024



Machine learning (ML) for text classification has been widely used in various domains, such as toxicity detection, chatbot consulting, and review analysis. These applications can significantly impact ethics, economics, and human behavior, raising serious concerns about trusting ML decisions. Several studies indicate that traditional metrics, such as model confidence and accuracy, are insufficient to build human trust in ML models. These models often learn spurious correlations during training and predict based on them during inference. In the real world, where such correlations are absent, their performance can deteriorate significantly. To avoid this, a common practice is to test whether predictions are reasonable. Along with this, a challenge known as the trustworthiness oracle problem has been introduced. Due to the lack of automated trustworthiness oracles, the assessment requires manual validation of the decision process disclosed by explanation methods, which is time-consuming and not scalable. We propose TOKI, the first automated trustworthiness oracle generation method for text classifiers, which automatically checks whether the prediction-contributing words are related to the predicted class using explanation methods and word embeddings. To demonstrate its practical usefulness, we introduce a novel adversarial attack method targeting trustworthiness issues identified by TOKI. We compare TOKI with a naive baseline based solely on model confidence using human-created ground truths of 6,000 predictions. We also compare TOKI-guided adversarial attack method with A2T, a SOTA adversarial attack method. Results show that relying on prediction uncertainty cannot distinguish between trustworthy and untrustworthy predictions, TOKI achieves 142% higher accuracy than the naive baseline, and TOKI-guided adversarial attack method is more effective with fewer perturbations than A2T.
Automated Trustworthiness Testing for Machine Learning Classifiers
Jun 07, 2024



Machine Learning (ML) has become an integral part of our society, commonly used in critical domains such as finance, healthcare, and transportation. Therefore, it is crucial to evaluate not only whether ML models make correct predictions but also whether they do so for the correct reasons, ensuring our trust that will perform well on unseen data. This concept is known as trustworthiness in ML. Recently, explainable techniques (e.g., LIME, SHAP) have been developed to interpret the decision-making processes of ML models, providing explanations for their predictions (e.g., words in the input that influenced the prediction the most). Assessing the plausibility of these explanations can enhance our confidence in the models' trustworthiness. However, current approaches typically rely on human judgment to determine the plausibility of these explanations. This paper proposes TOWER, the first technique to automatically create trustworthiness oracles that determine whether text classifier predictions are trustworthy. It leverages word embeddings to automatically evaluate the trustworthiness of a model-agnostic text classifiers based on the outputs of explanatory techniques. Our hypothesis is that a prediction is trustworthy if the words in its explanation are semantically related to the predicted class. We perform unsupervised learning with untrustworthy models obtained from noisy data to find the optimal configuration of TOWER. We then evaluated TOWER on a human-labeled trustworthiness dataset that we created. The results show that TOWER can detect a decrease in trustworthiness as noise increases, but is not effective when evaluated against the human-labeled dataset. Our initial experiments suggest that our hypothesis is valid and promising, but further research is needed to better understand the relationship between explanations and trustworthiness issues.
SGP-DT: Semantic Genetic Programming Based on Dynamic Targets
Jan 30, 2020
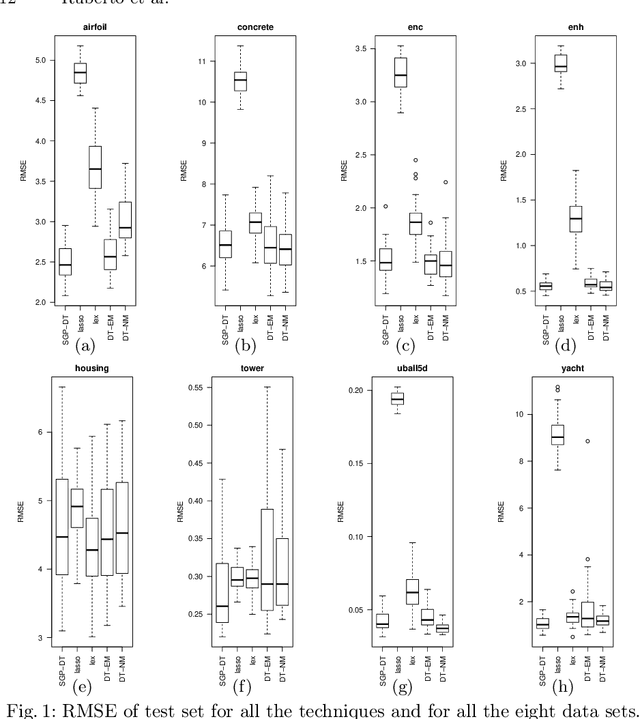

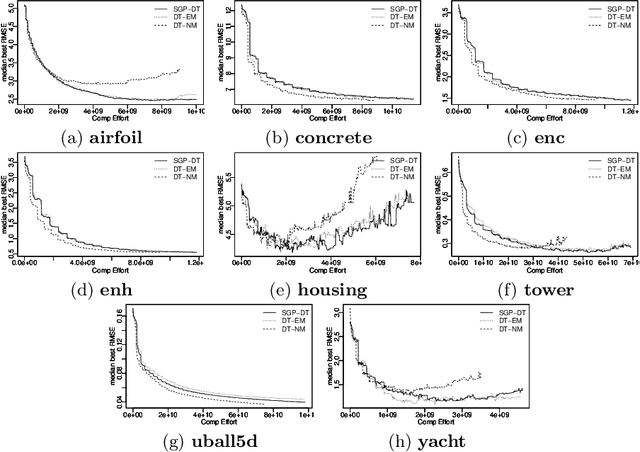
Semantic GP is a promising approach that introduces semantic awareness during genetic evolution. This paper presents a new Semantic GP approach based on Dynamic Target (SGP-DT) that divides the search problem into multiple GP runs. The evolution in each run is guided by a new (dynamic) target based on the residual errors. To obtain the final solution, SGP-DT combines the solutions of each run using linear scaling. SGP-DT presents a new methodology to produce the offspring that does not rely on the classic crossover. The synergy between such a methodology and linear scaling yields to final solutions with low approximation error and computational cost. We evaluate SGP-DT on eight well-known data sets and compare with {\epsilon}-lexicase, a state-of-the-art evolutionary technique. SGP-DT achieves small RMSE values, on average 23.19% smaller than the one of {\epsilon}-lexicase.
Expeditious Generation of Knowledge Graph Embeddings
Mar 21, 2018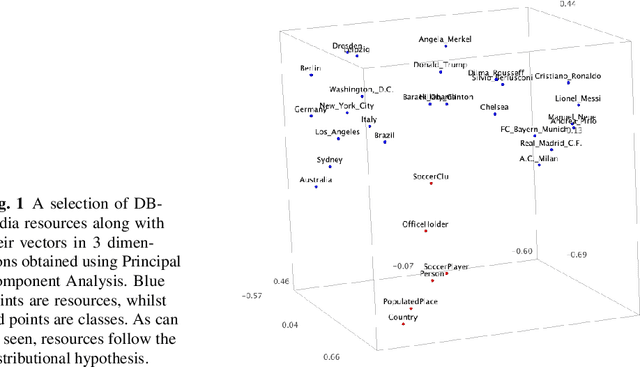
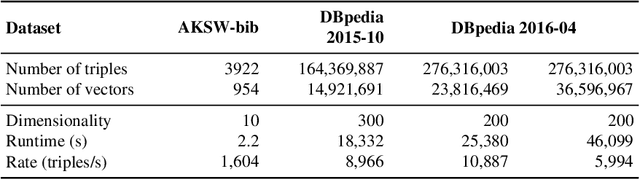
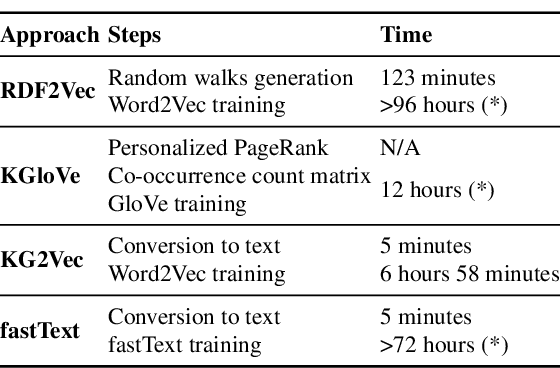
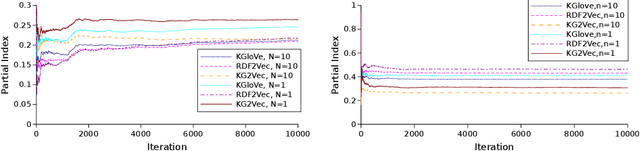
Knowledge Graph Embedding methods aim at representing entities and relations in a knowledge base as points or vectors in a continuous vector space. Several approaches using embeddings have shown promising results on tasks such as link prediction, entity recommendation, question answering, and triplet classification. However, only a few methods can compute low-dimensional embeddings of very large knowledge bases. In this paper, we propose KG2Vec, a novel approach to Knowledge Graph Embedding based on the skip-gram model. Instead of using a predefined scoring function, we learn it relying on Long Short-Term Memories. We evaluated the goodness of our embeddings on knowledge graph completion and show that KG2Vec is comparable to the quality of the scalable state-of-the-art approaches and can process large graphs by parsing more than a hundred million triples in less than 6 hours on common hardware.