 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Weight Tying: Pseudo-Inverse Tying for Stable LM Training and Updates
Feb 04, 2026Weight tying is widely used in compact language models to reduce parameters by sharing the token table between the input embedding and the output projection. However, weight sharing does not guarantee a stable token interface: during training, the correspondence between encoding tokens into hidden states and decoding hidden states into logits can drift, worsening optimization sensitivity and making post-training interventions such as editing, patching, and lightweight adaptation less predictable. We propose Pseudo-Inverse Tying (PIT), which synchronizes embedding and unembedding as coupled projections of a shared latent token memory, guaranteeing a pseudo-inverse-consistent interface throughout training. PIT maintains an orthonormal shared memory, obtained by thin polar decomposition for teacher initialization or random orthonormal initialization from scratch, and introduces a fully learned symmetric positive definite hidden-space transform parameterized via a Cholesky factor. The output head applies this transform to hidden states before the vocabulary projection, while the embedding applies the inverse transform to token vectors using stable triangular solves, avoiding explicit pseudo-inverse recomputation and any vocabulary-sized auxiliary parameters. We evaluate PIT on on-device models spanning 256M-1.3B parameters across pretraining and adaptation, and consistently observe improved training stability, stronger layerwise semantic consistency, and substantially reduced side effects.
SeMe: Training-Free Language Model Merging via Semantic Alignment
May 26, 2025Despite the remarkable capabilities of Language Models (LMs) across diverse tasks, no single model consistently outperforms others, necessitating efficient methods to combine their strengths without expensive retraining. Existing model merging techniques, such as parameter averaging and task-guided fusion, often rely on data-dependent computations or fail to preserve internal knowledge, limiting their robustness and scalability. We introduce SeMe (Semantic-based Merging), a novel, data-free, and training-free approach that leverages latent semantic alignment to merge LMs at a fine-grained, layer-wise level. Unlike prior work, SeMe not only preserves model behaviors but also explicitly stabilizes internal knowledge, addressing a critical gap in LM fusion. Through extensive experiments across diverse architectures and tasks, we demonstrate that SeMe outperforms existing methods in both performance and efficiency while eliminating reliance on external data. Our work establishes a new paradigm for knowledge-aware model merging and provides insights into the semantic structure of LMs, paving the way for more scalable and interpretable model composition.
A Semantic-based Optimization Approach for Repairing LLMs: Case Study on Code Generation
Mar 17, 2025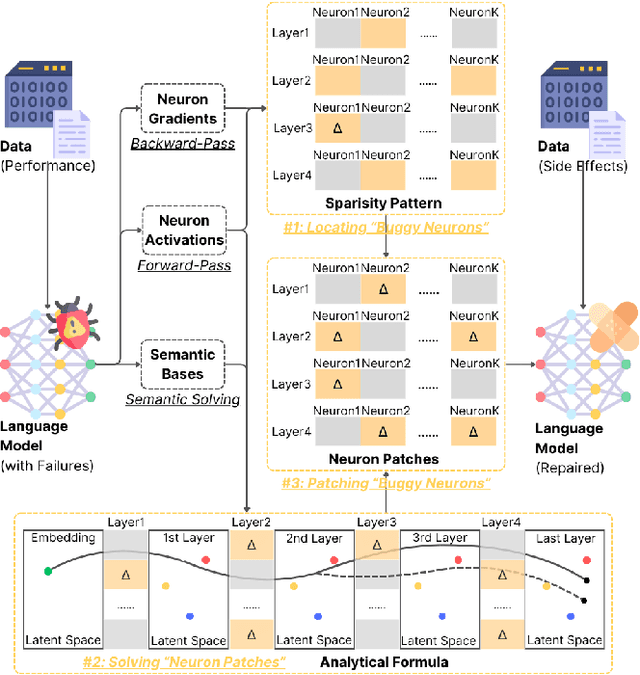
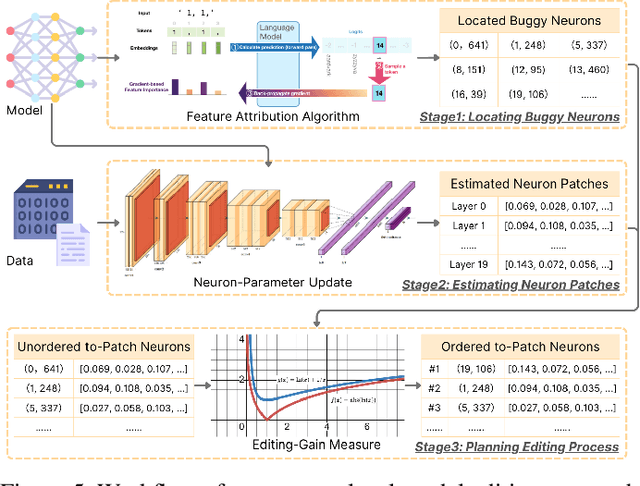
Language Models (LMs) are widely used in software engineering for code generation, but they may produce code with errors. Rather than repairing the generated code, an alternative way is to address the underlying failures of models. LM repair offers a lightweight solution to this challenge: it requires minimal data, reduces computational costs, and reduces the side effects. Unlike retraining, LM repair focuses on applying tailored updates to targeted neurons, making it ideal for scenarios with limited resources, high-performance demands, or strict safety requirements. In this paper, we propose \ul{S}emantic \ul{T}argeting for \ul{A}nalytical \ul{R}epair (\textsc{STAR}), a pioneering and novel semantic-based optimization approach for repairing LLMs. \textsc{STAR} realizes main operations in LM repair methods in an optimization process, including locating ``buggy neurons'', solving ``neuron patches'', and patching ``buggy neurons''. Correspondingly, it computes the deltas of weight matrix as the prior information to guide optimization; and attributes the targeted layers and neurons leveraging statistical insights. The neuron patches are computed with a solid semantic-based analytical formula, which directly bridges the changes to logits with the deltas of neurons, by steering latent representations. Compared to the prior work of LM repair (\textsc{MINT}) and optimization methods (\textsc{SGD}), \textsc{STAR} integrates their strengths while mitigating their limitations. \textsc{STAR} supports solving multiple failures together, significantly improving the usefulness. Evaluated on three code generation tasks using popular code LMs, \textsc{STAR} demonstrates superior effectiveness. Additionally, \textsc{STAR} exhibits better efficiency. In terms of side effects, namely the balance between generalization and specificity, \textsc{STAR} outperforms prior work by a significant margin.
MORTAR: Metamorphic Multi-turn Testing for LLM-based Dialogue Systems
Dec 20, 2024With the widespread application of LLM-based dialogue systems in daily life, quality assurance has become more important than ever. Recent research has successfully introduced methods to identify unexpected behaviour in single-turn scenarios. However, multi-turn dialogue testing remains underexplored, with the Oracle problem in multi-turn testing posing a persistent challenge for dialogue system developers and researchers. In this paper, we propose MORTAR, a MetamORphic multi-TuRn diAlogue testing appRoach, which mitigates the test oracle problem in the assessment of LLM-based dialogue systems. MORTAR automates the generation of follow-up question-answer (QA) dialogue test cases with multiple dialogue-level perturbations and metamorphic relations. MORTAR employs a novel knowledge graph-based dialogue information model which effectively generates perturbed dialogue test datasets and detects bugs of multi-turn dialogue systems in a low-cost manner. The proposed approach does not require an LLM as a judge, eliminating potential of any biases in the evaluation step. According to the experiment results on multiple LLM-based dialogue systems and comparisons with single-turn metamorphic testing approaches, MORTAR explores more unique bugs in LLM-based dialogue systems, especially for severe bugs that MORTAR detects up to four times more unique bugs than the most effective existing metamorphic testing approach.
Automated Trustworthiness Oracle Generation for Machine Learning Text Classifiers
Oct 30, 2024



Machine learning (ML) for text classification has been widely used in various domains, such as toxicity detection, chatbot consulting, and review analysis. These applications can significantly impact ethics, economics, and human behavior, raising serious concerns about trusting ML decisions. Several studies indicate that traditional metrics, such as model confidence and accuracy, are insufficient to build human trust in ML models. These models often learn spurious correlations during training and predict based on them during inference. In the real world, where such correlations are absent, their performance can deteriorate significantly. To avoid this, a common practice is to test whether predictions are reasonable. Along with this, a challenge known as the trustworthiness oracle problem has been introduced. Due to the lack of automated trustworthiness oracles, the assessment requires manual validation of the decision process disclosed by explanation methods, which is time-consuming and not scalable. We propose TOKI, the first automated trustworthiness oracle generation method for text classifiers, which automatically checks whether the prediction-contributing words are related to the predicted class using explanation methods and word embeddings. To demonstrate its practical usefulness, we introduce a novel adversarial attack method targeting trustworthiness issues identified by TOKI. We compare TOKI with a naive baseline based solely on model confidence using human-created ground truths of 6,000 predictions. We also compare TOKI-guided adversarial attack method with A2T, a SOTA adversarial attack method. Results show that relying on prediction uncertainty cannot distinguish between trustworthy and untrustworthy predictions, TOKI achieves 142% higher accuracy than the naive baseline, and TOKI-guided adversarial attack method is more effective with fewer perturbations than A2T.
A Semantic-based Layer Freezing Approach to Efficient Fine-Tuning of Language Models
Jun 17, 2024



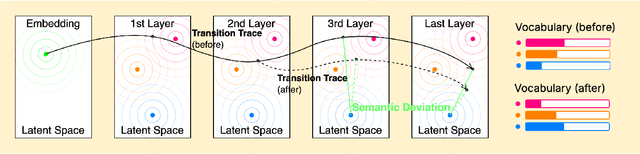
Finetuning language models (LMs) is crucial for adapting the models to downstream data and tasks. However, full finetuning is usually costly. Existing work, such as parameter-efficient finetuning (PEFT), often focuses on \textit{how to finetune} but neglects the issue of \textit{where to finetune}. As a pioneering work on answering where to finetune (at the layer level), we conduct a semantic analysis of the LM inference process. We first propose a virtual transition of the latent representation and then trace its factual transition. Based on the deviation in transitions, we estimate the gain of finetuning each model layer, and further, narrow down the scope for finetuning. We perform extensive experiments across well-known LMs and datasets. The results show that our approach is effective and efficient, and outperforms the existing baselines. Our approach is orthogonal to existing efficient techniques, such as PEFT methods, offering practical values on LM finetuning.
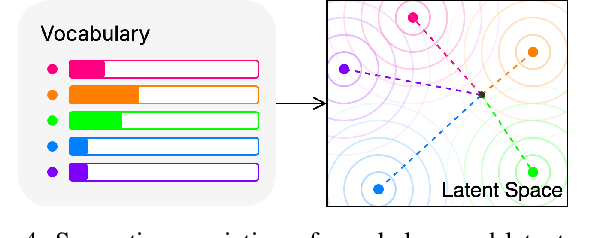
On the Semantics of LM Latent Space: A Vocabulary-defined Approach
Feb 02, 2024



Understanding the latent space of language models (LM) is crucial to refining their performance and interpretability. Existing analyses often fall short in providing disentangled (model-centric) insights into LM semantics, and neglect essential aspects of LM adaption. In response, we introduce a pioneering method called vocabulary-defined semantics, which establishes a reference frame within the LM latent space, ensuring disentangled semantic analysis grounded in LM vocabulary. Our approach transcends prior entangled analysis, leveraging LM vocabulary for model-centric insights. Furthermore, we propose a novel technique to compute logits, emphasising differentiability and local isotropy, and introduce a neural clustering module for semantically calibrating data representations during LM adaptation. Through extensive experiments across diverse text understanding datasets, our approach outperforms state-of-the-art methods of retrieval-augmented generation and parameter-efficient finetuning, showcasing its efficacy and broad applicability. Our findings not only shed light on LM mechanics, but also offer practical solutions to enhance LM performance and interpretability.
Neuron Patching: Neuron-level Model Editing on Code Generation and LLMs
Dec 08, 2023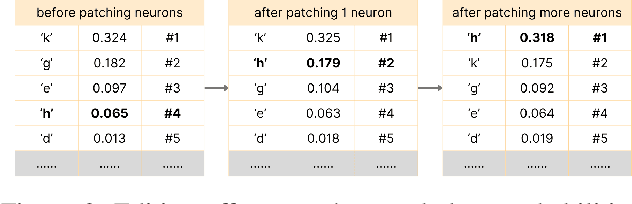
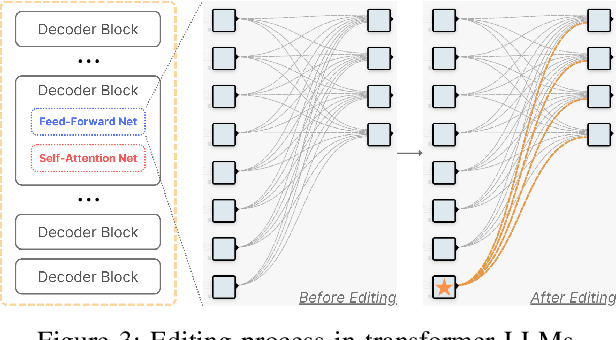
Large Language Models are successfully adopted in software engineering, especially in code generation. Updating these models with new knowledge is very expensive, and is often required to fully realize their value. In this paper, we propose a novel and effective model editing approach, \textsc{MENT}, to patch LLMs in coding tasks. Based on the mechanism of generative LLMs, \textsc{MENT} enables model editing in next-token predictions, and further supports common coding tasks. \textsc{MENT} is effective, efficient, and reliable. It can correct a neural model by patching 1 or 2 neurons. As the pioneer work on neuron-level model editing of generative models, we formalize the editing process and introduce the involved concepts. Besides, we also introduce new measures to evaluate its generalization ability, and build a benchmark for further study. Our approach is evaluated on three coding tasks, including API-seq recommendation, line-level code generation, and pseudocode-to-code transaction. It outperforms the state-of-the-art by a significant margin on both effectiveness and efficiency measures. In addition, we demonstrate the usages of \textsc{MENT} for LLM reasoning in software engineering. By editing the LLM knowledge with \textsc{MENT}, the directly or indirectly dependent behaviors in the chain-of-thought change accordingly and automatically.
The Neighbours' Similar Fitness Property for Local Search
Jan 09, 2020
For most practical optimisation problems local search outperforms random sampling - despite the "No Free Lunch Theorem". This paper introduces a property of search landscapes termed Neighbours' Similar Fitness (NSF) that underlies the good performance of neighbourhood search in terms of local improvement. Though necessary, NSF is not sufficient to ensure that searching for improvement among the neighbours of a good solution is better than random search. The paper introduces an additional (natural) property which supports a general proof that, for NSF landscapes, neighbourhood search beats random search.
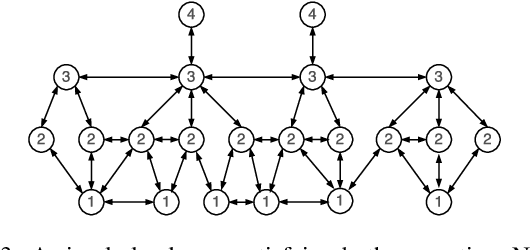
Is perturbation an effective restart strategy?
Dec 05, 2019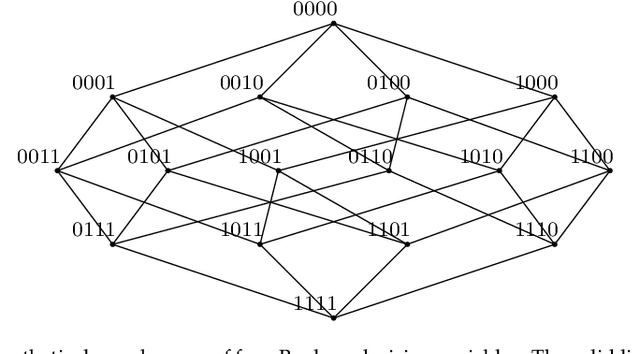
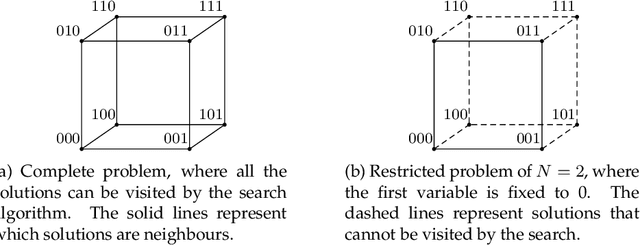
Premature convergence can be detrimental to the performance of search methods, which is why many search algorithms include restart strategies to deal with it. While it is common to perturb the incumbent solution with diversification steps of various sizes with the hope that the search method will find a new basin of attraction leading to a better local optimum, it is usually not clear how big the perturbation step should be. We introduce a new property of fitness landscapes termed "Neighbours with Similar Fitness" and we demonstrate that the effectiveness of a restart strategy depends on this property.