 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemRF: A Semantic Reference Frame for Residual-Stream Dynamics in Language Models
Jun 30, 2026Residual-stream analysis asks how language-model computation evolves across depth, but intermediate decoding requires comparable readout coordinates across layers. If embedding anchors and unembedding readout disagree on the chosen span, apparent motion may reflect measurement drift rather than computation. We introduce \emph{Semantic Reference Frames} (SemRF), an anchor-based formalism separating semantic measurement from residual dynamics. A SemRF fixes anchors and measures states against them. Pseudo-inverse tying gives exact synchronization; under restricted bi-invertibility, SemRF yields stable semantic-basis coordinates, distortion bounds, and near-identity changes. With the frame fixed, residual computation becomes a depthwise semantic trajectory. The anchors induce a semantic Voronoi diagram: distance, or evidence such as logits, assigns each layer to a coarse cell, while coordinates retain within-cell motion and margins. We define layerwise steps, contribution profiles, and imbalance diagnostics, then use the Voronoi trace to define a margin-relaxed tube. The canonical trace is the minimum-action path inside this tube; when nonempty with positive quadratic weight, it is unique and obeys a discrete spline equation away from active constraints. Excess action controls step, curvature, and profile mismatch. Low curvature implies piecewise-linear compressibility and local knowledge density: lower trace complexity means fewer semantic knots. Through the parameter-to-trajectory map, this gives a conditional link to parameter efficiency: among admissible settings fitting data, lower-action and lower-complexity traces use fewer semantic degrees of freedom. The guarantees require controlled interface error and small projection residual under explicit tube constraints.
Rethinking Weight Tying: Pseudo-Inverse Tying for Stable LM Training and Updates
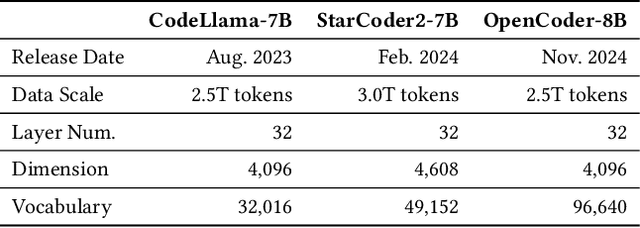
Feb 04, 2026Weight tying is widely used in compact language models to reduce parameters by sharing the token table between the input embedding and the output projection. However, weight sharing does not guarantee a stable token interface: during training, the correspondence between encoding tokens into hidden states and decoding hidden states into logits can drift, worsening optimization sensitivity and making post-training interventions such as editing, patching, and lightweight adaptation less predictable. We propose Pseudo-Inverse Tying (PIT), which synchronizes embedding and unembedding as coupled projections of a shared latent token memory, guaranteeing a pseudo-inverse-consistent interface throughout training. PIT maintains an orthonormal shared memory, obtained by thin polar decomposition for teacher initialization or random orthonormal initialization from scratch, and introduces a fully learned symmetric positive definite hidden-space transform parameterized via a Cholesky factor. The output head applies this transform to hidden states before the vocabulary projection, while the embedding applies the inverse transform to token vectors using stable triangular solves, avoiding explicit pseudo-inverse recomputation and any vocabulary-sized auxiliary parameters. We evaluate PIT on on-device models spanning 256M-1.3B parameters across pretraining and adaptation, and consistently observe improved training stability, stronger layerwise semantic consistency, and substantially reduced side effects.
SeMe: Training-Free Language Model Merging via Semantic Alignment
May 26, 2025Despite the remarkable capabilities of Language Models (LMs) across diverse tasks, no single model consistently outperforms others, necessitating efficient methods to combine their strengths without expensive retraining. Existing model merging techniques, such as parameter averaging and task-guided fusion, often rely on data-dependent computations or fail to preserve internal knowledge, limiting their robustness and scalability. We introduce SeMe (Semantic-based Merging), a novel, data-free, and training-free approach that leverages latent semantic alignment to merge LMs at a fine-grained, layer-wise level. Unlike prior work, SeMe not only preserves model behaviors but also explicitly stabilizes internal knowledge, addressing a critical gap in LM fusion. Through extensive experiments across diverse architectures and tasks, we demonstrate that SeMe outperforms existing methods in both performance and efficiency while eliminating reliance on external data. Our work establishes a new paradigm for knowledge-aware model merging and provides insights into the semantic structure of LMs, paving the way for more scalable and interpretable model composition.
A Semantic-based Optimization Approach for Repairing LLMs: Case Study on Code Generation
Mar 17, 2025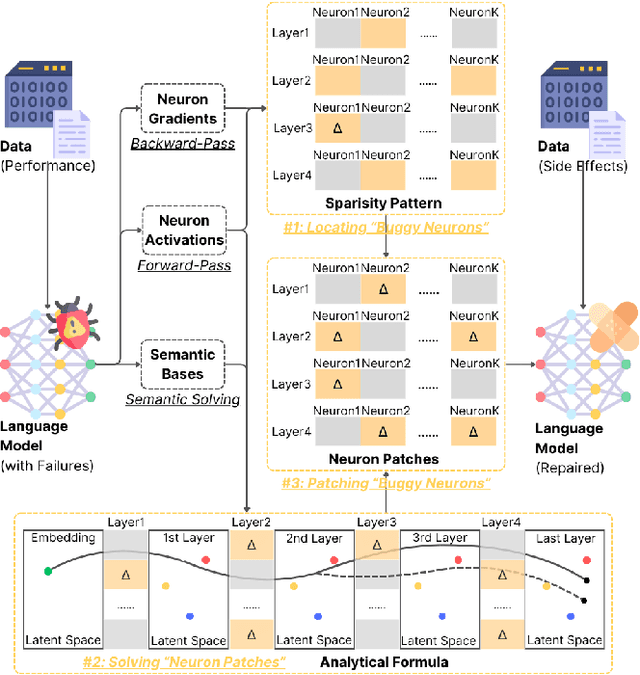
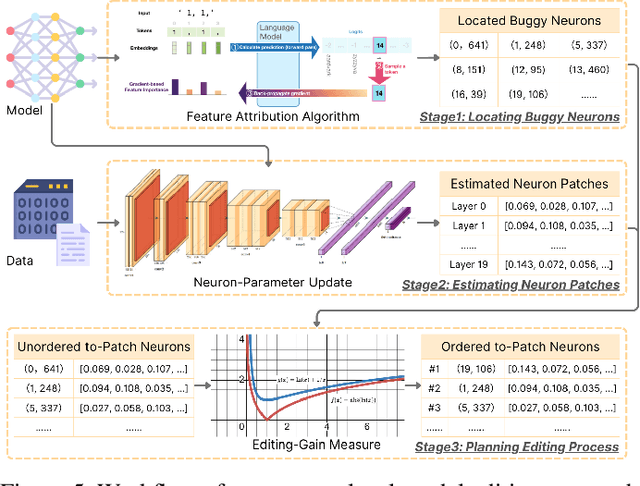
Language Models (LMs) are widely used in software engineering for code generation, but they may produce code with errors. Rather than repairing the generated code, an alternative way is to address the underlying failures of models. LM repair offers a lightweight solution to this challenge: it requires minimal data, reduces computational costs, and reduces the side effects. Unlike retraining, LM repair focuses on applying tailored updates to targeted neurons, making it ideal for scenarios with limited resources, high-performance demands, or strict safety requirements. In this paper, we propose \ul{S}emantic \ul{T}argeting for \ul{A}nalytical \ul{R}epair (\textsc{STAR}), a pioneering and novel semantic-based optimization approach for repairing LLMs. \textsc{STAR} realizes main operations in LM repair methods in an optimization process, including locating ``buggy neurons'', solving ``neuron patches'', and patching ``buggy neurons''. Correspondingly, it computes the deltas of weight matrix as the prior information to guide optimization; and attributes the targeted layers and neurons leveraging statistical insights. The neuron patches are computed with a solid semantic-based analytical formula, which directly bridges the changes to logits with the deltas of neurons, by steering latent representations. Compared to the prior work of LM repair (\textsc{MINT}) and optimization methods (\textsc{SGD}), \textsc{STAR} integrates their strengths while mitigating their limitations. \textsc{STAR} supports solving multiple failures together, significantly improving the usefulness. Evaluated on three code generation tasks using popular code LMs, \textsc{STAR} demonstrates superior effectiveness. Additionally, \textsc{STAR} exhibits better efficiency. In terms of side effects, namely the balance between generalization and specificity, \textsc{STAR} outperforms prior work by a significant margin.
A Semantic-based Layer Freezing Approach to Efficient Fine-Tuning of Language Models
Jun 17, 2024



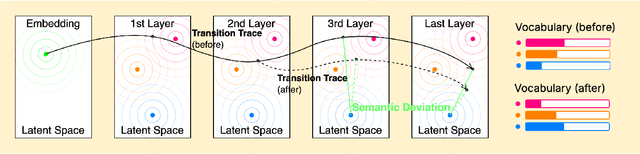
Finetuning language models (LMs) is crucial for adapting the models to downstream data and tasks. However, full finetuning is usually costly. Existing work, such as parameter-efficient finetuning (PEFT), often focuses on \textit{how to finetune} but neglects the issue of \textit{where to finetune}. As a pioneering work on answering where to finetune (at the layer level), we conduct a semantic analysis of the LM inference process. We first propose a virtual transition of the latent representation and then trace its factual transition. Based on the deviation in transitions, we estimate the gain of finetuning each model layer, and further, narrow down the scope for finetuning. We perform extensive experiments across well-known LMs and datasets. The results show that our approach is effective and efficient, and outperforms the existing baselines. Our approach is orthogonal to existing efficient techniques, such as PEFT methods, offering practical values on LM finetuning.
On the Semantics of LM Latent Space: A Vocabulary-defined Approach
Feb 02, 2024



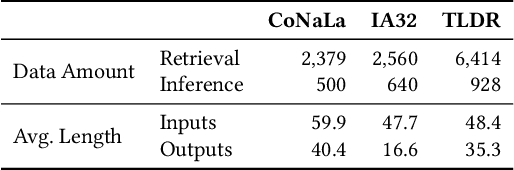
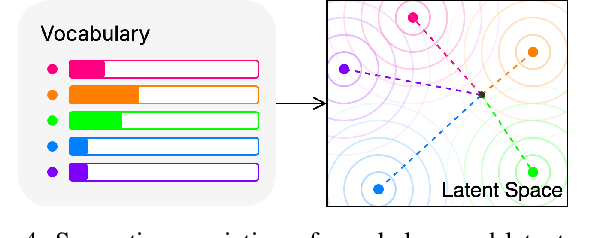
Understanding the latent space of language models (LM) is crucial to refining their performance and interpretability. Existing analyses often fall short in providing disentangled (model-centric) insights into LM semantics, and neglect essential aspects of LM adaption. In response, we introduce a pioneering method called vocabulary-defined semantics, which establishes a reference frame within the LM latent space, ensuring disentangled semantic analysis grounded in LM vocabulary. Our approach transcends prior entangled analysis, leveraging LM vocabulary for model-centric insights. Furthermore, we propose a novel technique to compute logits, emphasising differentiability and local isotropy, and introduce a neural clustering module for semantically calibrating data representations during LM adaptation. Through extensive experiments across diverse text understanding datasets, our approach outperforms state-of-the-art methods of retrieval-augmented generation and parameter-efficient finetuning, showcasing its efficacy and broad applicability. Our findings not only shed light on LM mechanics, but also offer practical solutions to enhance LM performance and interpretability.
Neuron Patching: Neuron-level Model Editing on Code Generation and LLMs
Dec 08, 2023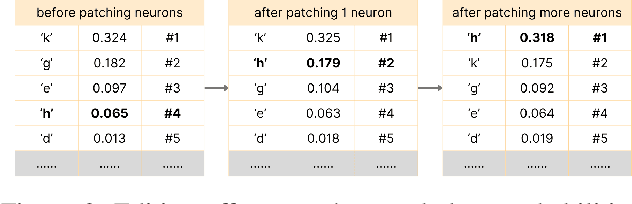
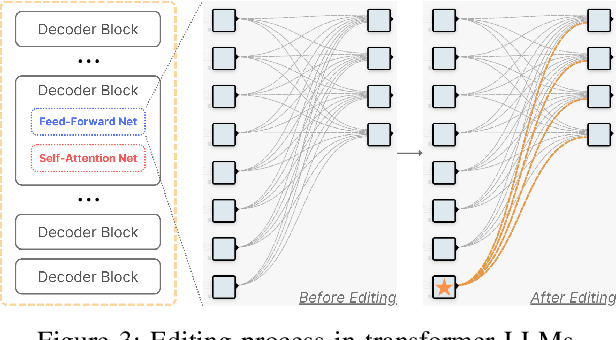
Large Language Models are successfully adopted in software engineering, especially in code generation. Updating these models with new knowledge is very expensive, and is often required to fully realize their value. In this paper, we propose a novel and effective model editing approach, \textsc{MENT}, to patch LLMs in coding tasks. Based on the mechanism of generative LLMs, \textsc{MENT} enables model editing in next-token predictions, and further supports common coding tasks. \textsc{MENT} is effective, efficient, and reliable. It can correct a neural model by patching 1 or 2 neurons. As the pioneer work on neuron-level model editing of generative models, we formalize the editing process and introduce the involved concepts. Besides, we also introduce new measures to evaluate its generalization ability, and build a benchmark for further study. Our approach is evaluated on three coding tasks, including API-seq recommendation, line-level code generation, and pseudocode-to-code transaction. It outperforms the state-of-the-art by a significant margin on both effectiveness and efficiency measures. In addition, we demonstrate the usages of \textsc{MENT} for LLM reasoning in software engineering. By editing the LLM knowledge with \textsc{MENT}, the directly or indirectly dependent behaviors in the chain-of-thought change accordingly and automatically.
Towards Top-Down Deep Code Generation in Limited Scopes
Sep 04, 2022


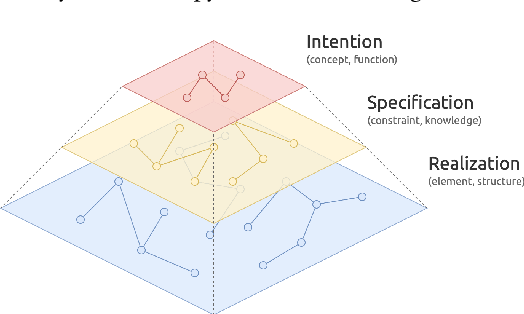
Deep code generation is a topic of deep learning for software engineering (DL4SE), which adopts neural models to generate code for the intended functions. Since end-to-end neural methods lack the awareness of domain knowledge and software hierarchy, the results often require manual correction. To systematically explore the potential improvements of code generation, we let it participate in the whole top-down development from intentions to realizations, which is possible in limited scopes. In the process, it benefits from massive samples, features, and knowledge. As the foundation, we suggest building a taxonomy on code data, namely code taxonomy, leveraging the categorization of code information. Moreover, we introduce a three-layer semantic pyramid (SP) to associate text data and code data. It identifies the information of different abstraction levels, and thus introduces the domain knowledge on development and reveals the hierarchy of software. Furthermore, we propose a semantic pyramid framework (SPF) as the approach, focusing on softwares of high modularity and low complexity. SPF divides the code generation process into stages and reserves spots for potential interactions. Eventually, we conceived application scopes for SPF.
Efficient Virtual View Selection for 3D Hand Pose Estimation
Mar 29, 2022
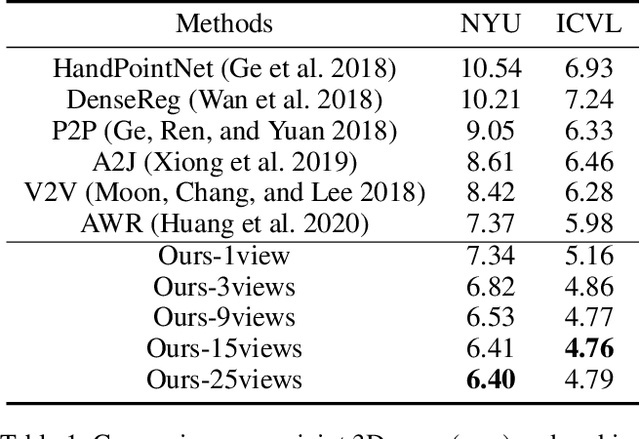
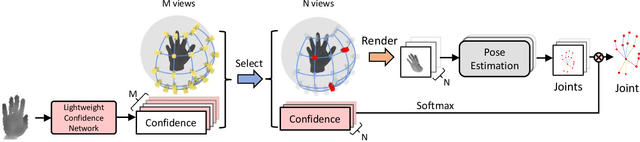
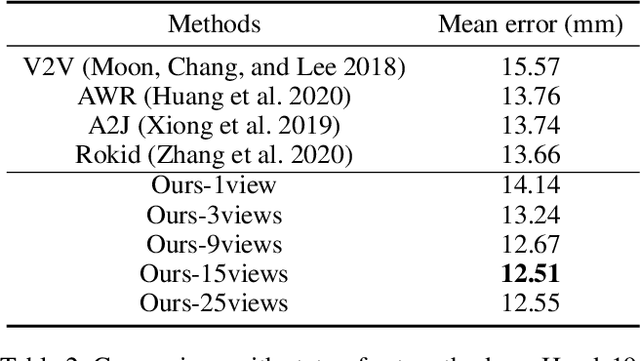
3D hand pose estimation from single depth is a fundamental problem in computer vision, and has wide applications.However, the existing methods still can not achieve satisfactory hand pose estimation results due to view variation and occlusion of human hand. In this paper, we propose a new virtual view selection and fusion module for 3D hand pose estimation from single depth.We propose to automatically select multiple virtual viewpoints for pose estimation and fuse the results of all and find this empirically delivers accurate and robust pose estimation. In order to select most effective virtual views for pose fusion, we evaluate the virtual views based on the confidence of virtual views using a light-weight network via network distillation. Experiments on three main benchmark datasets including NYU, ICVL and Hands2019 demonstrate that our method outperforms the state-of-the-arts on NYU and ICVL, and achieves very competitive performance on Hands2019-Task1, and our proposed virtual view selection and fusion module is both effective for 3D hand pose estimation.
Assemble Foundation Models for Automatic Code Summarization
Jan 13, 2022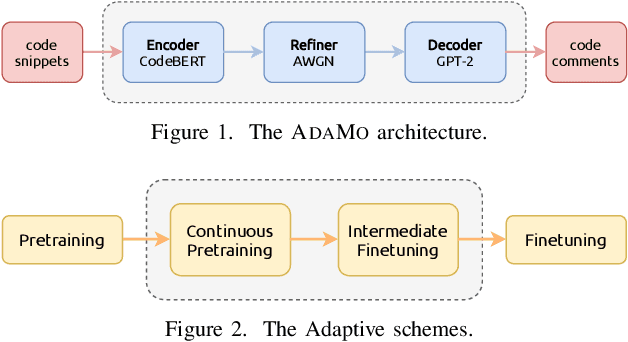
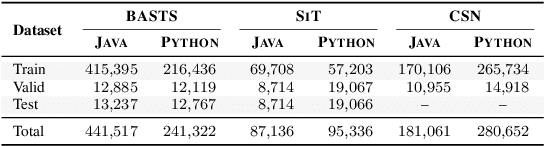
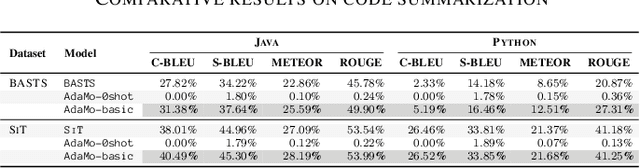
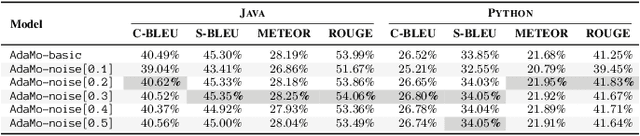
Automatic code summarization is beneficial to software development and maintenance since it reduces the burden of manual tasks. Currently, artificial intelligence is undergoing a paradigm shift. The foundation models pretrained on massive data and finetuned to downstream tasks surpass specially customized models. This trend inspired us to consider reusing foundation models instead of learning from scratch. Based on this, we propose a flexible and robust approach for automatic code summarization based on neural networks. We assemble available foundation models, such as CodeBERT and GPT-2, into a single model named AdaMo. Moreover, we utilize Gaussian noise as the simulation of contextual information to optimize the latent representation. Furthermore, we introduce two adaptive schemes from the perspective of knowledge transfer, namely continuous pretraining and intermediate finetuning, and design intermediate stage tasks for general sequence-to-sequence learning. Finally, we evaluate AdaMo against a benchmark dataset for code summarization, by comparing it with state-of-the-art models.