 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Privacy-Preserving Code Generation: Differentially Private Code Language Models
Dec 12, 2025Large language models specialized for code (CodeLLMs) have demonstrated remarkable capabilities in generating code snippets, documentation, and test cases. However, despite their promising capabilities, CodeLLMs can inadvertently memorize and reproduce snippets from their training data, which poses risks of privacy breaches and intellectual property violations. These risks restrict the deployment of CodeLLMs in sensitive domains and limit their training datasets to publicly available sources. To mitigate the memorization risk without compromising their task performance, we apply Differential Privacy (DP) to CodeLLMs. To the best of our knowledge, this is the first comprehensive study that systematically evaluates the effectiveness of DP in CodeLLMs. DP adds calibrated noise to the training process to protect individual data points while still allowing the model to learn useful patterns. To this end, we first identify and understand the driving reasons of the memorization behaviour of the CodeLLMs during their fine-tuning. Then, to address this issue, we empirically evaluate the effect of DP on mitigating memorization while preserving code generation capabilities. Our findings show that DP substantially reduces memorization in CodeLLMs across all the tested snippet types. The snippet types most prone to memorization are also the most effectively mitigated by DP. Furthermore, we observe that DP slightly increases perplexity but preserves, and can even enhance, the code generation capabilities of CodeLLMs, which makes it feasible to apply DP in practice without significantly compromising model utility. Finally, we analyze the impact of DP on training efficiency and energy consumption, finding that DP does not significantly affect training time or energy usage, making it a practical choice for privacy-preserving CodeLLMs training.
Towards Top-Down Deep Code Generation in Limited Scopes
Sep 04, 2022


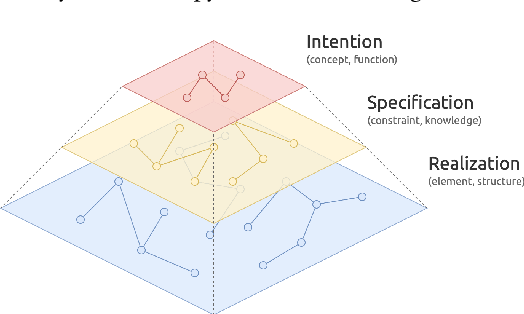
Deep code generation is a topic of deep learning for software engineering (DL4SE), which adopts neural models to generate code for the intended functions. Since end-to-end neural methods lack the awareness of domain knowledge and software hierarchy, the results often require manual correction. To systematically explore the potential improvements of code generation, we let it participate in the whole top-down development from intentions to realizations, which is possible in limited scopes. In the process, it benefits from massive samples, features, and knowledge. As the foundation, we suggest building a taxonomy on code data, namely code taxonomy, leveraging the categorization of code information. Moreover, we introduce a three-layer semantic pyramid (SP) to associate text data and code data. It identifies the information of different abstraction levels, and thus introduces the domain knowledge on development and reveals the hierarchy of software. Furthermore, we propose a semantic pyramid framework (SPF) as the approach, focusing on softwares of high modularity and low complexity. SPF divides the code generation process into stages and reserves spots for potential interactions. Eventually, we conceived application scopes for SPF.
Assemble Foundation Models for Automatic Code Summarization
Jan 13, 2022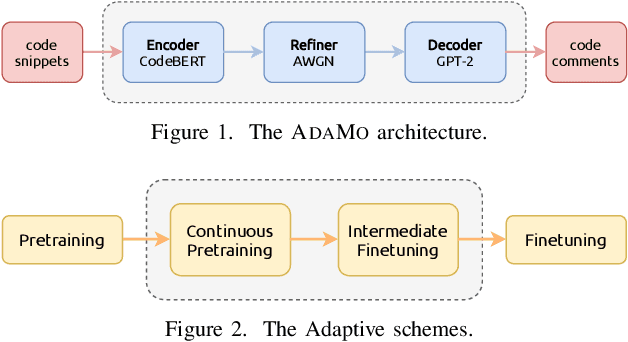
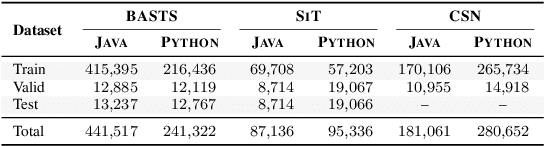
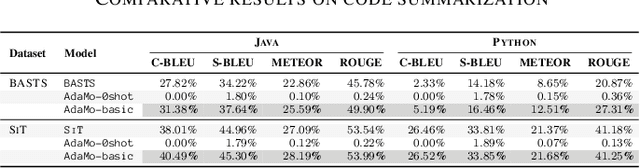
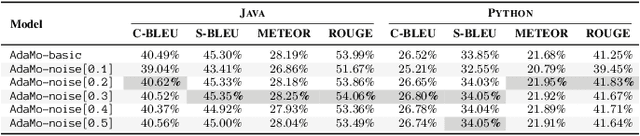
Automatic code summarization is beneficial to software development and maintenance since it reduces the burden of manual tasks. Currently, artificial intelligence is undergoing a paradigm shift. The foundation models pretrained on massive data and finetuned to downstream tasks surpass specially customized models. This trend inspired us to consider reusing foundation models instead of learning from scratch. Based on this, we propose a flexible and robust approach for automatic code summarization based on neural networks. We assemble available foundation models, such as CodeBERT and GPT-2, into a single model named AdaMo. Moreover, we utilize Gaussian noise as the simulation of contextual information to optimize the latent representation. Furthermore, we introduce two adaptive schemes from the perspective of knowledge transfer, namely continuous pretraining and intermediate finetuning, and design intermediate stage tasks for general sequence-to-sequence learning. Finally, we evaluate AdaMo against a benchmark dataset for code summarization, by comparing it with state-of-the-art models.