 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffgrasp: Whole-Body Grasping Synthesis Guided by Object Motion Using a Diffusion Model
Dec 30, 2024



Generating high-quality whole-body human object interaction motion sequences is becoming increasingly important in various fields such as animation, VR/AR, and robotics. The main challenge of this task lies in determining the level of involvement of each hand given the complex shapes of objects in different sizes and their different motion trajectories, while ensuring strong grasping realism and guaranteeing the coordination of movement in all body parts. Contrasting with existing work, which either generates human interaction motion sequences without detailed hand grasping poses or only models a static grasping pose, we propose a simple yet effective framework that jointly models the relationship between the body, hands, and the given object motion sequences within a single diffusion model. To guide our network in perceiving the object's spatial position and learning more natural grasping poses, we introduce novel contact-aware losses and incorporate a data-driven, carefully designed guidance. Experimental results demonstrate that our approach outperforms the state-of-the-art method and generates plausible whole-body motion sequences.
Efficient Virtual View Selection for 3D Hand Pose Estimation
Mar 29, 2022
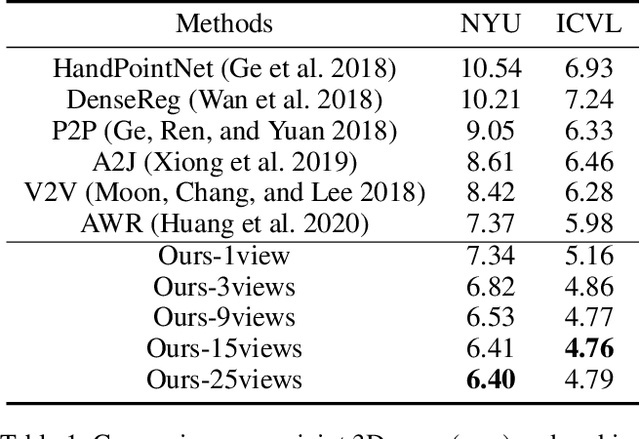
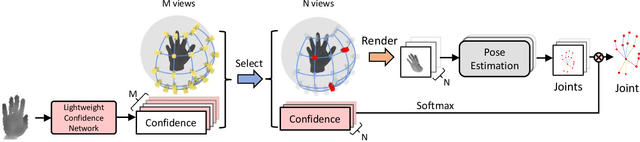
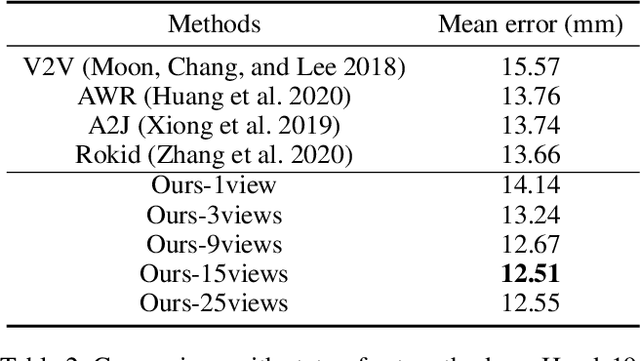
3D hand pose estimation from single depth is a fundamental problem in computer vision, and has wide applications.However, the existing methods still can not achieve satisfactory hand pose estimation results due to view variation and occlusion of human hand. In this paper, we propose a new virtual view selection and fusion module for 3D hand pose estimation from single depth.We propose to automatically select multiple virtual viewpoints for pose estimation and fuse the results of all and find this empirically delivers accurate and robust pose estimation. In order to select most effective virtual views for pose fusion, we evaluate the virtual views based on the confidence of virtual views using a light-weight network via network distillation. Experiments on three main benchmark datasets including NYU, ICVL and Hands2019 demonstrate that our method outperforms the state-of-the-arts on NYU and ICVL, and achieves very competitive performance on Hands2019-Task1, and our proposed virtual view selection and fusion module is both effective for 3D hand pose estimation.