 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Features Guided Zero-Shot Category-Level Object Pose Estimation
Jan 06, 2025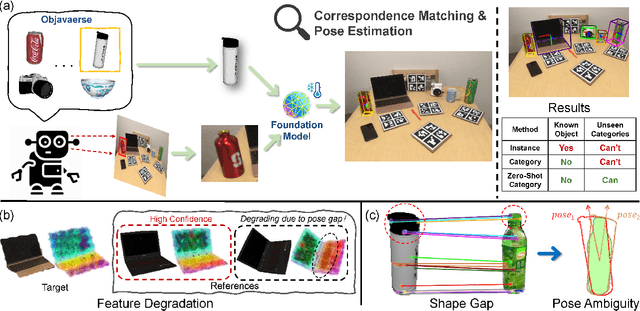
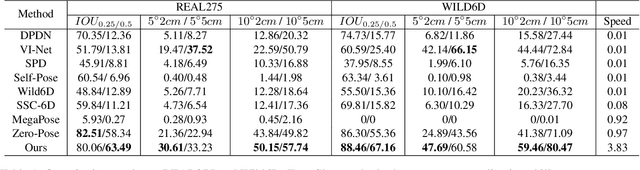
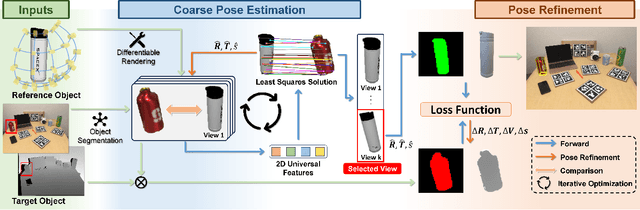

Object pose estimation, crucial in computer vision and robotics applications, faces challenges with the diversity of unseen categories. We propose a zero-shot method to achieve category-level 6-DOF object pose estimation, which exploits both 2D and 3D universal features of input RGB-D image to establish semantic similarity-based correspondences and can be extended to unseen categories without additional model fine-tuning. Our method begins with combining efficient 2D universal features to find sparse correspondences between intra-category objects and gets initial coarse pose. To handle the correspondence degradation of 2D universal features if the pose deviates much from the target pose, we use an iterative strategy to optimize the pose. Subsequently, to resolve pose ambiguities due to shape differences between intra-category objects, the coarse pose is refined by optimizing with dense alignment constraint of 3D universal features. Our method outperforms previous methods on the REAL275 and Wild6D benchmarks for unseen categories.
HOGSA: Bimanual Hand-Object Interaction Understanding with 3D Gaussian Splatting Based Data Augmentation
Jan 06, 2025



Understanding of bimanual hand-object interaction plays an important role in robotics and virtual reality. However, due to significant occlusions between hands and object as well as the high degree-of-freedom motions, it is challenging to collect and annotate a high-quality, large-scale dataset, which prevents further improvement of bimanual hand-object interaction-related baselines. In this work, we propose a new 3D Gaussian Splatting based data augmentation framework for bimanual hand-object interaction, which is capable of augmenting existing dataset to large-scale photorealistic data with various hand-object pose and viewpoints. First, we use mesh-based 3DGS to model objects and hands, and to deal with the rendering blur problem due to multi-resolution input images used, we design a super-resolution module. Second, we extend the single hand grasping pose optimization module for the bimanual hand object to generate various poses of bimanual hand-object interaction, which can significantly expand the pose distribution of the dataset. Third, we conduct an analysis for the impact of different aspects of the proposed data augmentation on the understanding of the bimanual hand-object interaction. We perform our data augmentation on two benchmarks, H2O and Arctic, and verify that our method can improve the performance of the baselines.
Diffgrasp: Whole-Body Grasping Synthesis Guided by Object Motion Using a Diffusion Model
Dec 30, 2024



Generating high-quality whole-body human object interaction motion sequences is becoming increasingly important in various fields such as animation, VR/AR, and robotics. The main challenge of this task lies in determining the level of involvement of each hand given the complex shapes of objects in different sizes and their different motion trajectories, while ensuring strong grasping realism and guaranteeing the coordination of movement in all body parts. Contrasting with existing work, which either generates human interaction motion sequences without detailed hand grasping poses or only models a static grasping pose, we propose a simple yet effective framework that jointly models the relationship between the body, hands, and the given object motion sequences within a single diffusion model. To guide our network in perceiving the object's spatial position and learning more natural grasping poses, we introduce novel contact-aware losses and incorporate a data-driven, carefully designed guidance. Experimental results demonstrate that our approach outperforms the state-of-the-art method and generates plausible whole-body motion sequences.
Self-supervised Learning of Implicit Shape Representation with Dense Correspondence for Deformable Objects
Aug 24, 2023



Learning 3D shape representation with dense correspondence for deformable objects is a fundamental problem in computer vision. Existing approaches often need additional annotations of specific semantic domain, e.g., skeleton poses for human bodies or animals, which require extra annotation effort and suffer from error accumulation, and they are limited to specific domain. In this paper, we propose a novel self-supervised approach to learn neural implicit shape representation for deformable objects, which can represent shapes with a template shape and dense correspondence in 3D. Our method does not require the priors of skeleton and skinning weight, and only requires a collection of shapes represented in signed distance fields. To handle the large deformation, we constrain the learned template shape in the same latent space with the training shapes, design a new formulation of local rigid constraint that enforces rigid transformation in local region and addresses local reflection issue, and present a new hierarchical rigid constraint to reduce the ambiguity due to the joint learning of template shape and correspondences. Extensive experiments show that our model can represent shapes with large deformations. We also show that our shape representation can support two typical applications, such as texture transfer and shape editing, with competitive performance. The code and models are available at https://iscas3dv.github.io/deformshape
Novel-view Synthesis and Pose Estimation for Hand-Object Interaction from Sparse Views
Aug 22, 2023Hand-object interaction understanding and the barely addressed novel view synthesis are highly desired in the immersive communication, whereas it is challenging due to the high deformation of hand and heavy occlusions between hand and object. In this paper, we propose a neural rendering and pose estimation system for hand-object interaction from sparse views, which can also enable 3D hand-object interaction editing. We share the inspiration from recent scene understanding work that shows a scene specific model built beforehand can significantly improve and unblock vision tasks especially when inputs are sparse, and extend it to the dynamic hand-object interaction scenario and propose to solve the problem in two stages. We first learn the shape and appearance prior knowledge of hands and objects separately with the neural representation at the offline stage. During the online stage, we design a rendering-based joint model fitting framework to understand the dynamic hand-object interaction with the pre-built hand and object models as well as interaction priors, which thereby overcomes penetration and separation issues between hand and object and also enables novel view synthesis. In order to get stable contact during the hand-object interaction process in a sequence, we propose a stable contact loss to make the contact region to be consistent. Experiments demonstrate that our method outperforms the state-of-the-art methods. Code and dataset are available in project webpage https://iscas3dv.github.io/HO-NeRF.
Efficient Virtual View Selection for 3D Hand Pose Estimation
Mar 29, 2022
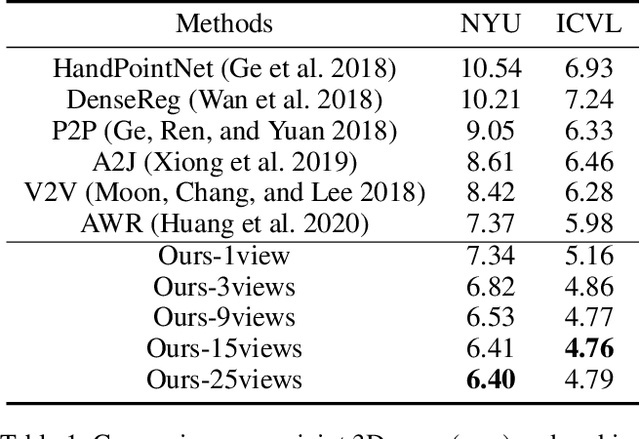
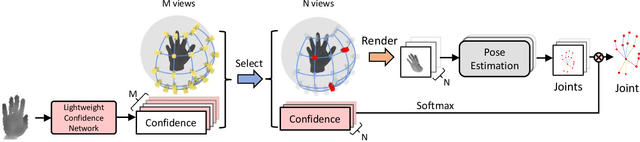
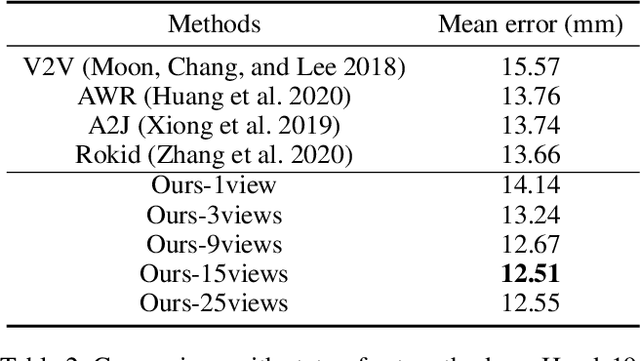
3D hand pose estimation from single depth is a fundamental problem in computer vision, and has wide applications.However, the existing methods still can not achieve satisfactory hand pose estimation results due to view variation and occlusion of human hand. In this paper, we propose a new virtual view selection and fusion module for 3D hand pose estimation from single depth.We propose to automatically select multiple virtual viewpoints for pose estimation and fuse the results of all and find this empirically delivers accurate and robust pose estimation. In order to select most effective virtual views for pose fusion, we evaluate the virtual views based on the confidence of virtual views using a light-weight network via network distillation. Experiments on three main benchmark datasets including NYU, ICVL and Hands2019 demonstrate that our method outperforms the state-of-the-arts on NYU and ICVL, and achieves very competitive performance on Hands2019-Task1, and our proposed virtual view selection and fusion module is both effective for 3D hand pose estimation.
E-ffective: A Visual Analytic System for Exploring the Emotion and Effectiveness of Inspirational Speeches
Oct 29, 2021
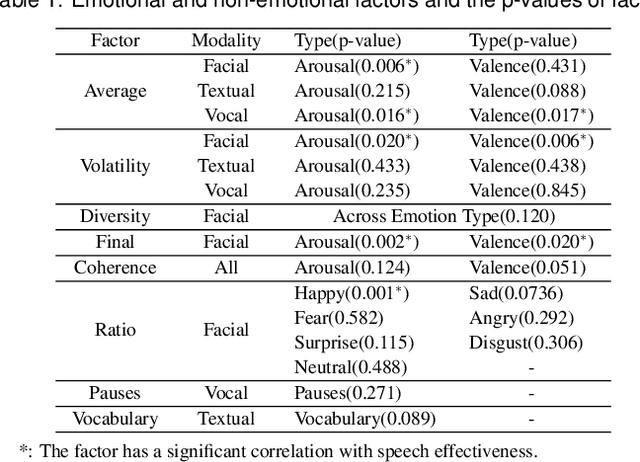


What makes speeches effective has long been a subject for debate, and until today there is broad controversy among public speaking experts about what factors make a speech effective as well as the roles of these factors in speeches. Moreover, there is a lack of quantitative analysis methods to help understand effective speaking strategies. In this paper, we propose E-ffective, a visual analytic system allowing speaking experts and novices to analyze both the role of speech factors and their contribution in effective speeches. From interviews with domain experts and investigating existing literature, we identified important factors to consider in inspirational speeches. We obtained the generated factors from multi-modal data that were then related to effectiveness data. Our system supports rapid understanding of critical factors in inspirational speeches, including the influence of emotions by means of novel visualization methods and interaction. Two novel visualizations include E-spiral (that shows the emotional shifts in speeches in a visually compact way) and E-script (that connects speech content with key speech delivery information). In our evaluation we studied the influence of our system on experts' domain knowledge about speech factors. We further studied the usability of the system by speaking novices and experts on assisting analysis of inspirational speech effectiveness.