 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model for All: Multi-Objective Controllable Language Models
Apr 06, 2026Aligning large language models (LLMs) with human preferences is critical for enhancing LLMs' safety, helpfulness, humor, faithfulness, etc. Current reinforcement learning from human feedback (RLHF) mainly focuses on a fixed reward learned from average human ratings, which may weaken the adaptability and controllability of varying preferences. However, creating personalized LLMs requires aligning LLMs with individual human preferences, which is non-trivial due to the scarce data per user and the diversity of user preferences in multi-objective trade-offs, varying from emphasizing empathy in certain contexts to demanding efficiency and precision in others. Can we train one LLM to produce personalized outputs across different user preferences on the Pareto front? In this paper, we introduce Multi-Objective Control (MOC), which trains a single LLM to directly generate responses in the preference-defined regions of the Pareto front. Our approach introduces multi-objective optimization (MOO) principles into RLHF to train an LLM as a preference-conditioned policy network. We improve the computational efficiency of MOC by applying MOO at the policy level, enabling us to fine-tune a 7B-parameter model on a single A6000 GPU. Extensive experiments demonstrate the advantages of MOC over baselines in three aspects: (i) controllability of LLM outputs w.r.t. user preferences on the trade-off among multiple rewards; (ii) quality and diversity of LLM outputs, measured by the hyper-volume of multiple solutions achieved; and (iii) generalization to unseen preferences. These results highlight MOC's potential for real-world applications requiring scalable and customizable LLMs.
TCATSeg: A Tooth Center-Wise Attention Network for 3D Dental Model Semantic Segmentation
Mar 17, 2026Accurate semantic segmentation of 3D dental models is essential for digital dentistry applications such as orthodontics and dental implants. However, due to complex tooth arrangements and similarities in shape among adjacent teeth, existing methods struggle with accurate segmentation, because they often focus on local geometry while neglecting global contextual information. To address this, we propose TCATSeg, a novel framework that combines local geometric features with global semantic context. We introduce a set of sparse yet physically meaningful superpoints to capture global semantic relationships and enhance segmentation accuracy. Additionally, we present a new dataset of 400 dental models, including pre-orthodontic samples, to evaluate the generalization of our method. Extensive experiments demonstrate that TCATSeg outperforms state-of-the-art approaches.
Pareto Multi-Objective Alignment for Language Models
Aug 11, 2025Large language models (LLMs) are increasingly deployed in real-world applications that require careful balancing of multiple, often conflicting, objectives, such as informativeness versus conciseness, or helpfulness versus creativity. However, current alignment methods, primarily based on RLHF, optimize LLMs toward a single reward function, resulting in rigid behavior that fails to capture the complexity and diversity of human preferences. This limitation hinders the adaptability of LLMs to practical scenarios, making multi-objective alignment (MOA) a critical yet underexplored area. To bridge this gap, we propose Pareto Multi-Objective Alignment (PAMA), a principled and computationally efficient algorithm designed explicitly for MOA in LLMs. In contrast to computationally prohibitive multi-objective optimization (MOO) methods, PAMA transforms multi-objective RLHF into a convex optimization with a closed-form solution, significantly enhancing scalability. Traditional MOO approaches suffer from prohibitive O(n^2*d) complexity, where d represents the number of model parameters, typically in the billions for LLMs, rendering direct optimization infeasible. PAMA reduces this complexity to O(n) where n is the number of objectives, enabling optimization to be completed within milliseconds. We provide theoretical guarantees that PAMA converges to a Pareto stationary point, where no objective can be improved without degrading at least one other. Extensive experiments across language models ranging from 125M to 7B parameters demonstrate PAMA's robust and effective MOA capabilities, aligning with its theoretical advantages. PAMA provides a highly efficient solution to the MOA problem that was previously considered intractable, offering a practical and theoretically grounded approach to aligning LLMs with diverse human values, paving the way for versatile and adaptable real-world AI deployments.
Task Adaptation from Skills: Information Geometry, Disentanglement, and New Objectives for Unsupervised Reinforcement Learning
Jun 12, 2025Unsupervised reinforcement learning (URL) aims to learn general skills for unseen downstream tasks. Mutual Information Skill Learning (MISL) addresses URL by maximizing the mutual information between states and skills but lacks sufficient theoretical analysis, e.g., how well its learned skills can initialize a downstream task's policy. Our new theoretical analysis in this paper shows that the diversity and separability of learned skills are fundamentally critical to downstream task adaptation but MISL does not necessarily guarantee these properties. To complement MISL, we propose a novel disentanglement metric LSEPIN. Moreover, we build an information-geometric connection between LSEPIN and downstream task adaptation cost. For better geometric properties, we investigate a new strategy that replaces the KL divergence in information geometry with Wasserstein distance. We extend the geometric analysis to it, which leads to a novel skill-learning objective WSEP. It is theoretically justified to be helpful to downstream task adaptation and it is capable of discovering more initial policies for downstream tasks than MISL. We finally propose another Wasserstein distance-based algorithm PWSEP that can theoretically discover all optimal initial policies.
* Spotlight paper at ICLR 2024. This version includes acknowledgments omitted from the ICLR version and indicates the corresponding authors primarily responsible for the work
Over-PINNs: Enhancing Physics-Informed Neural Networks via Higher-Order Partial Derivative Overdetermination of PDEs
Jun 06, 2025Partial differential equations (PDEs) serve as the cornerstone of mathematical physics. In recent years, Physics-Informed Neural Networks (PINNs) have significantly reduced the dependence on large datasets by embedding physical laws directly into the training of neural networks. However, when dealing with complex problems, the accuracy of PINNs still has room for improvement. To address this issue, we introduce the Over-PINNs framework, which leverages automatic differentiation (AD) to generate higher-order auxiliary equations that impose additional physical constraints. These equations are incorporated as extra loss terms in the training process, effectively enhancing the model's ability to capture physical information through an "overdetermined" approach. Numerical results illustrate that this method exhibits strong versatility in solving various types of PDEs. It achieves a significant improvement in solution accuracy without incurring substantial additional computational costs.
Learning from Loss Landscape: Generalizable Mixed-Precision Quantization via Adaptive Sharpness-Aware Gradient Aligning
May 08, 2025Mixed Precision Quantization (MPQ) has become an essential technique for optimizing neural network by determining the optimal bitwidth per layer. Existing MPQ methods, however, face a major hurdle: they require a computationally expensive search for quantization policies on large-scale datasets. To resolve this issue, we introduce a novel approach that first searches for quantization policies on small datasets and then generalizes them to large-scale datasets. This approach simplifies the process, eliminating the need for large-scale quantization fine-tuning and only necessitating model weight adjustment. Our method is characterized by three key techniques: sharpness-aware minimization for enhanced quantization generalization, implicit gradient direction alignment to handle gradient conflicts among different optimization objectives, and an adaptive perturbation radius to accelerate optimization. Both theoretical analysis and experimental results validate our approach. Using the CIFAR10 dataset (just 0.5\% the size of ImageNet training data) for MPQ policy search, we achieved equivalent accuracy on ImageNet with a significantly lower computational cost, while improving efficiency by up to 150% over the baselines.
NuWa: Deriving Lightweight Task-Specific Vision Transformers for Edge Devices
Apr 04, 2025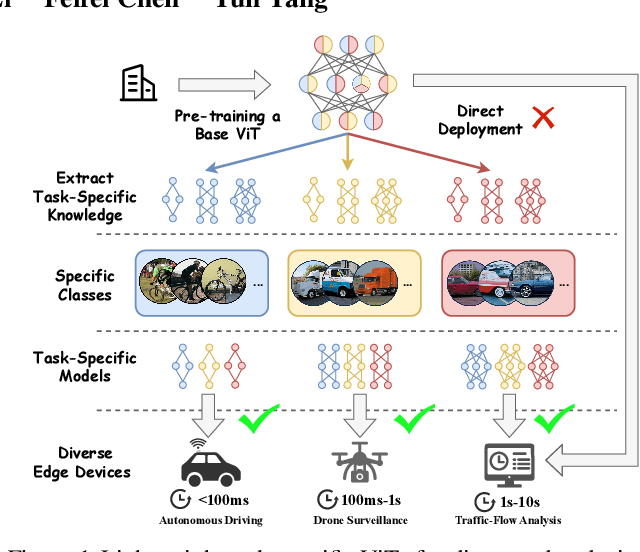



Vision Transformers (ViTs) excel in computer vision tasks but lack flexibility for edge devices' diverse needs. A vital issue is that ViTs pre-trained to cover a broad range of tasks are \textit{over-qualified} for edge devices that usually demand only part of a ViT's knowledge for specific tasks. Their task-specific accuracy on these edge devices is suboptimal. We discovered that small ViTs that focus on device-specific tasks can improve model accuracy and in the meantime, accelerate model inference. This paper presents NuWa, an approach that derives small ViTs from the base ViT for edge devices with specific task requirements. NuWa can transfer task-specific knowledge extracted from the base ViT into small ViTs that fully leverage constrained resources on edge devices to maximize model accuracy with inference latency assurance. Experiments with three base ViTs on three public datasets demonstrate that compared with state-of-the-art solutions, NuWa improves model accuracy by up to $\text{11.83}\%$ and accelerates model inference by 1.29$\times$ - 2.79$\times$. Code for reproduction is available at https://anonymous.4open.science/r/Task_Specific-3A5E.
Diffgrasp: Whole-Body Grasping Synthesis Guided by Object Motion Using a Diffusion Model
Dec 30, 2024



Generating high-quality whole-body human object interaction motion sequences is becoming increasingly important in various fields such as animation, VR/AR, and robotics. The main challenge of this task lies in determining the level of involvement of each hand given the complex shapes of objects in different sizes and their different motion trajectories, while ensuring strong grasping realism and guaranteeing the coordination of movement in all body parts. Contrasting with existing work, which either generates human interaction motion sequences without detailed hand grasping poses or only models a static grasping pose, we propose a simple yet effective framework that jointly models the relationship between the body, hands, and the given object motion sequences within a single diffusion model. To guide our network in perceiving the object's spatial position and learning more natural grasping poses, we introduce novel contact-aware losses and incorporate a data-driven, carefully designed guidance. Experimental results demonstrate that our approach outperforms the state-of-the-art method and generates plausible whole-body motion sequences.
Advancing DRL Agents in Commercial Fighting Games: Training, Integration, and Agent-Human Alignment
Jun 03, 2024Deep Reinforcement Learning (DRL) agents have demonstrated impressive success in a wide range of game genres. However, existing research primarily focuses on optimizing DRL competence rather than addressing the challenge of prolonged player interaction. In this paper, we propose a practical DRL agent system for fighting games named Sh\=ukai, which has been successfully deployed to Naruto Mobile, a popular fighting game with over 100 million registered users. Sh\=ukai quantifies the state to enhance generalizability, introducing Heterogeneous League Training (HELT) to achieve balanced competence, generalizability, and training efficiency. Furthermore, Sh\=ukai implements specific rewards to align the agent's behavior with human expectations. Sh\=ukai's ability to generalize is demonstrated by its consistent competence across all characters, even though it was trained on only 13% of them. Additionally, HELT exhibits a remarkable 22% improvement in sample efficiency. Sh\=ukai serves as a valuable training partner for players in Naruto Mobile, enabling them to enhance their abilities and skills.
Adaptive Regularization of Representation Rank as an Implicit Constraint of Bellman Equation
Apr 19, 2024Representation rank is an important concept for understanding the role of Neural Networks (NNs) in Deep Reinforcement learning (DRL), which measures the expressive capacity of value networks. Existing studies focus on unboundedly maximizing this rank; nevertheless, that approach would introduce overly complex models in the learning, thus undermining performance. Hence, fine-tuning representation rank presents a challenging and crucial optimization problem. To address this issue, we find a guiding principle for adaptive control of the representation rank. We employ the Bellman equation as a theoretical foundation and derive an upper bound on the cosine similarity of consecutive state-action pairs representations of value networks. We then leverage this upper bound to propose a novel regularizer, namely BEllman Equation-based automatic rank Regularizer (BEER). This regularizer adaptively regularizes the representation rank, thus improving the DRL agent's performance. We first validate the effectiveness of automatic control of rank on illustrative experiments. Then, we scale up BEER to complex continuous control tasks by combining it with the deterministic policy gradient method. Among 12 challenging DeepMind control tasks, BEER outperforms the baselines by a large margin. Besides, BEER demonstrates significant advantages in Q-value approximation. Our code is available at https://github.com/sweetice/BEER-ICLR2024.