 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCF-CAM: Gradient Perturbation Mitigation and Feature Stabilization for Reliable Interpretability
Mar 31, 2025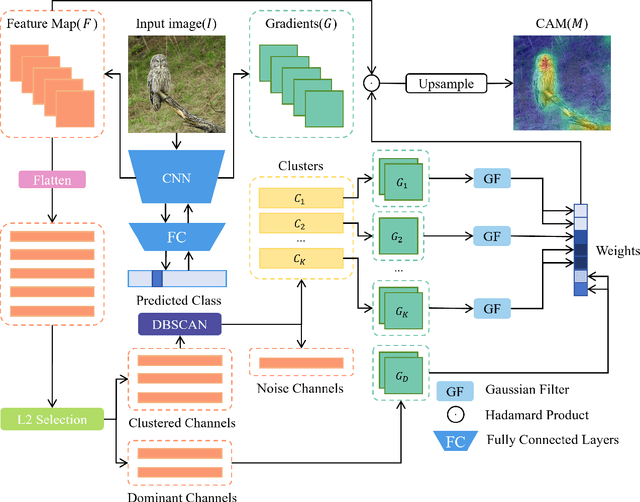

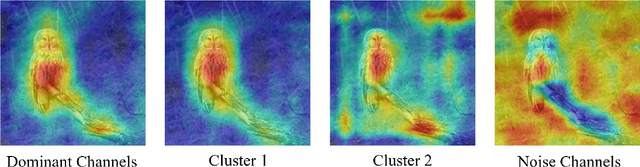
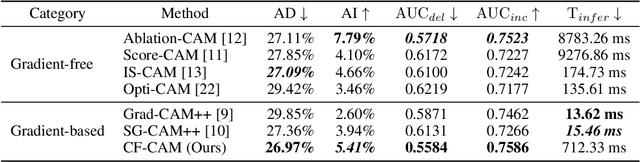
As deep learning continues to advance, the opacity of neural network decision-making remains a critical challenge, limiting trust and applicability in high-stakes domains. Class Activation Mapping (CAM) techniques have emerged as a key approach to visualizing model decisions, yet existing methods face inherent trade-offs. Gradient-based CAM variants suffer from sensitivity to gradient perturbations, leading to unstable and unreliable explanations. Conversely, gradient-free approaches mitigate gradient instability but incur significant computational overhead and inference latency. To address these limitations, we propose Cluster Filter Class Activation Map (CF-CAM), a novel framework that reintroduces gradient-based weighting while enhancing robustness against gradient noise. CF-CAM employs a hierarchical importance weighting strategy to balance discriminative feature preservation and noise elimination. A density-aware channel clustering via Density-Based Spatial Clustering of Applications with Noise (DBSCAN) groups semantically relevant feature channels and discard noise-prone activations. Additionally, cluster-conditioned gradient filtering leverages bilateral filters to refine gradient signals, preserving edge-aware localization while suppressing noise impact. Experiment results demonstrate that CF-CAM achieves superior interpretability performance while maintaining resilience to gradient perturbations, outperforming state-of-the-art CAM methods in faithfulness and robustness. By effectively mitigating gradient instability without excessive computational cost, CF-CAM provides a reliable solution for enhancing the interpretability of deep neural networks in critical applications such as medical diagnosis and autonomous driving.
Self-supervised Noise2noise Method Utilizing Corrupted Images with a Modular Network for LDCT Denoising
Aug 13, 2023Deep learning is a very promising technique for low-dose computed tomography (LDCT) image denoising. However, traditional deep learning methods require paired noisy and clean datasets, which are often difficult to obtain. This paper proposes a new method for performing LDCT image denoising with only LDCT data, which means that normal-dose CT (NDCT) is not needed. We adopt a combination including the self-supervised noise2noise model and the noisy-as-clean strategy. First, we add a second yet similar type of noise to LDCT images multiple times. Note that we use LDCT images based on the noisy-as-clean strategy for corruption instead of NDCT images. Then, the noise2noise model is executed with only the secondary corrupted images for training. We select a modular U-Net structure from several candidates with shared parameters to perform the task, which increases the receptive field without increasing the parameter size. The experimental results obtained on the Mayo LDCT dataset show the effectiveness of the proposed method compared with that of state-of-the-art deep learning methods. The developed code is available at https://github.com/XYuan01/Self-supervised-Noise2Noise-for-LDCT.
NL-CS Net: Deep Learning with Non-Local Prior for Image Compressive Sensing
May 06, 2023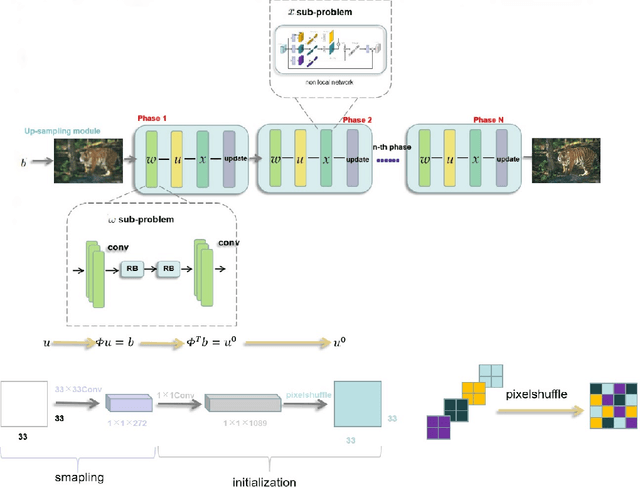

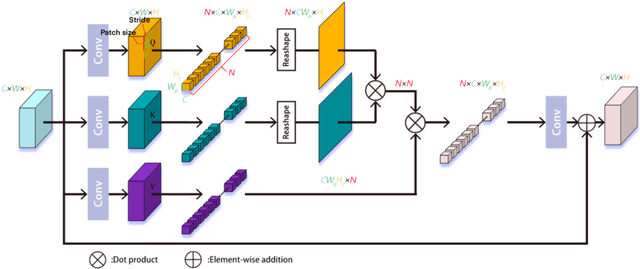
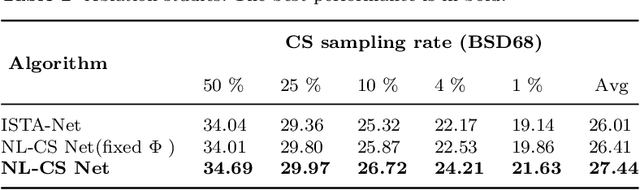
Deep learning has been applied to compressive sensing (CS) of images successfully in recent years. However, existing network-based methods are often trained as the black box, in which the lack of prior knowledge is often the bottleneck for further performance improvement. To overcome this drawback, this paper proposes a novel CS method using non-local prior which combines the interpretability of the traditional optimization methods with the speed of network-based methods, called NL-CS Net. We unroll each phase from iteration of the augmented Lagrangian method solving non-local and sparse regularized optimization problem by a network. NL-CS Net is composed of the up-sampling module and the recovery module. In the up-sampling module, we use learnable up-sampling matrix instead of a predefined one. In the recovery module, patch-wise non-local network is employed to capture long-range feature correspondences. Important parameters involved (e.g. sampling matrix, nonlinear transforms, shrinkage thresholds, step size, $etc.$) are learned end-to-end, rather than hand-crafted. Furthermore, to facilitate practical implementation, orthogonal and binary constraints on the sampling matrix are simultaneously adopted. Extensive experiments on natural images and magnetic resonance imaging (MRI) demonstrate that the proposed method outperforms the state-of-the-art methods while maintaining great interpretability and speed.
3D PETCT Tumor Lesion Segmentation via GCN Refinement
Feb 24, 2023Whole-body PET/CT scan is an important tool for diagnosing various malignancies (e.g., malignant melanoma, lymphoma, or lung cancer), and accurate segmentation of tumors is a key part for subsequent treatment. In recent years, CNN-based segmentation methods have been extensively investigated. However, these methods often give inaccurate segmentation results, such as over-segmentation and under-segmentation. Therefore, to address such issues, we propose a post-processing method based on a graph convolutional neural network (GCN) to refine inaccurate segmentation parts and improve the overall segmentation accuracy. Firstly, nnUNet is used as an initial segmentation framework, and the uncertainty in the segmentation results is analyzed. Certainty and uncertainty nodes establish the nodes of a graph neural network. Each node and its 6 neighbors form an edge, and 32 nodes are randomly selected for uncertain nodes to form edges. The highly uncertain nodes are taken as the subsequent refinement targets. Secondly, the nnUNet result of the certainty nodes is used as label to form a semi-supervised graph network problem, and the uncertainty part is optimized through training the GCN network to improve the segmentation performance. This describes our proposed nnUNet-GCN segmentation framework. We perform tumor segmentation experiments on the PET/CT dataset in the MICCIA2022 autoPET challenge. Among them, 30 cases are randomly selected for testing, and the experimental results show that the false positive rate is effectively reduced with nnUNet-GCN refinement. In quantitative analysis, there is an improvement of 2.12 % on the average Dice score, 6.34 on 95 % Hausdorff Distance (HD95), and 1.72 on average symmetric surface distance (ASSD). The quantitative and qualitative evaluation results show that GCN post-processing methods can effectively improve tumor segmentation performance.
QS-ADN: Quasi-Supervised Artifact Disentanglement Network for Low-Dose CT Image Denoising by Local Similarity Among Unpaired Data
Feb 08, 2023Deep learning has been successfully applied to low-dose CT (LDCT) image denoising for reducing potential radiation risk. However, the widely reported supervised LDCT denoising networks require a training set of paired images, which is expensive to obtain and cannot be perfectly simulated. Unsupervised learning utilizes unpaired data and is highly desirable for LDCT denoising. As an example, an artifact disentanglement network (ADN) relies on unparied images and obviates the need for supervision but the results of artifact reduction are not as good as those through supervised learning.An important observation is that there is often hidden similarity among unpaired data that can be utilized. This paper introduces a new learning mode, called quasi-supervised learning, to empower the ADN for LDCT image denoising.For every LDCT image, the best matched image is first found from an unpaired normal-dose CT (NDCT) dataset. Then, the matched pairs and the corresponding matching degree as prior information are used to construct and train our ADN-type network for LDCT denoising.The proposed method is different from (but compatible with) supervised and semi-supervised learning modes and can be easily implemented by modifying existing networks. The experimental results show that the method is competitive with state-of-the-art methods in terms of noise suppression and contextual fidelity. The code and working dataset are publicly available at https://github.com/ruanyuhui/ADN-QSDL.git.
Attentional Ptycho-Tomography (APT) for three-dimensional nanoscale X-ray imaging with minimal data acquisition and computation time
Nov 29, 2022Noninvasive X-ray imaging of nanoscale three-dimensional objects, e.g. integrated circuits (ICs), generally requires two types of scanning: ptychographic, which is translational and returns estimates of complex electromagnetic field through ICs; and tomographic scanning, which collects complex field projections from multiple angles. Here, we present Attentional Ptycho-Tomography (APT), an approach trained to provide accurate reconstructions of ICs despite incomplete measurements, using a dramatically reduced amount of angular scanning. Training process includes regularizing priors based on typical IC patterns and the physics of X-ray propagation. We demonstrate that APT with 12-time reduced angles achieves fidelity comparable to the gold standard with the original set of angles. With the same set of reduced angles, APT also outperforms baseline reconstruction methods. In our experiments, APT achieves 108-time aggregate reduction in data acquisition and computation without compromising quality. We expect our physics-assisted machine learning framework could also be applied to other branches of nanoscale imaging.
Deep learning at the edge enables real-time streaming ptychographic imaging
Sep 20, 2022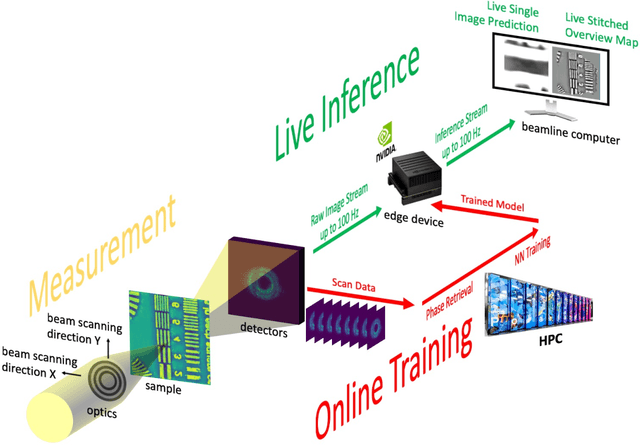
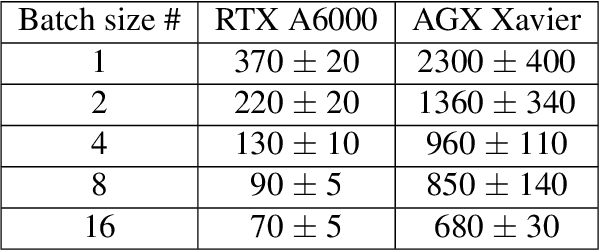
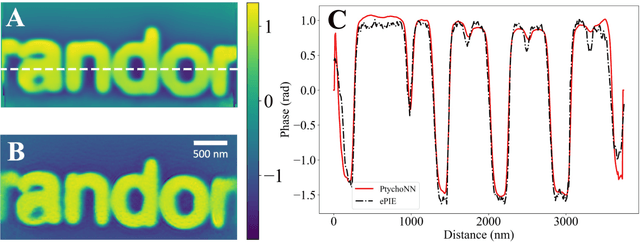

Coherent microscopy techniques provide an unparalleled multi-scale view of materials across scientific and technological fields, from structural materials to quantum devices, from integrated circuits to biological cells. Driven by the construction of brighter sources and high-rate detectors, coherent X-ray microscopy methods like ptychography are poised to revolutionize nanoscale materials characterization. However, associated significant increases in data and compute needs mean that conventional approaches no longer suffice for recovering sample images in real-time from high-speed coherent imaging experiments. Here, we demonstrate a workflow that leverages artificial intelligence at the edge and high-performance computing to enable real-time inversion on X-ray ptychography data streamed directly from a detector at up to 2 kHz. The proposed AI-enabled workflow eliminates the sampling constraints imposed by traditional ptychography, allowing low dose imaging using orders of magnitude less data than required by traditional methods.
Quasi-supervised Learning for Super-resolution PET
Sep 03, 2022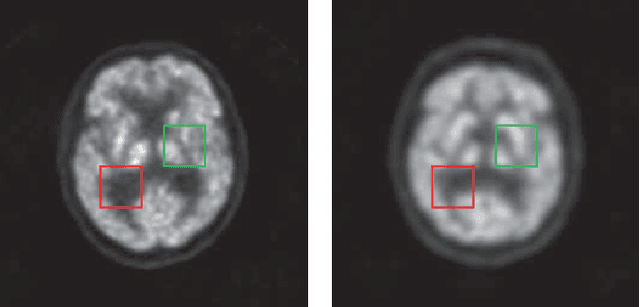
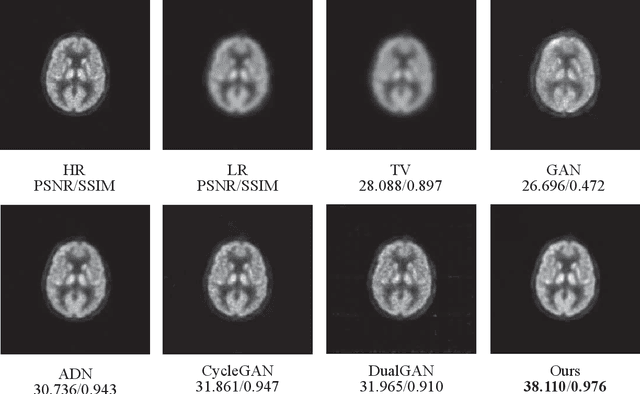
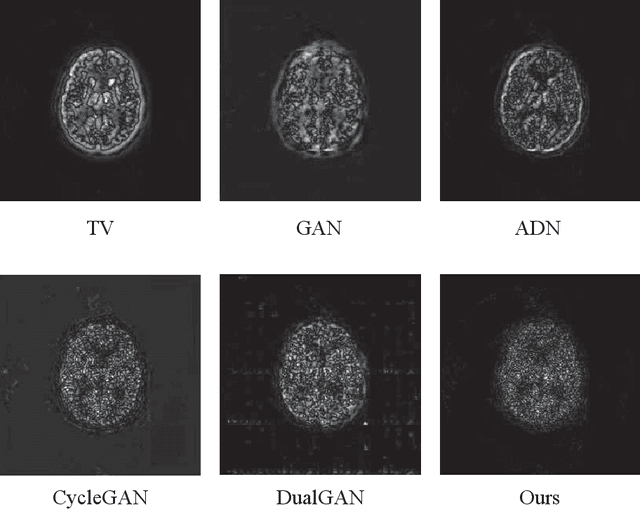
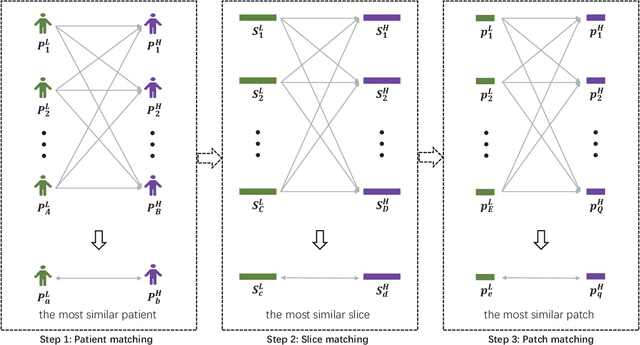
Low resolution of positron emission tomography (PET) limits its diagnostic performance. Deep learning has been successfully applied to achieve super-resolution PET. However, commonly used supervised learning methods in this context require many pairs of low- and high-resolution (LR and HR) PET images. Although unsupervised learning utilizes unpaired images, the results are not as good as that obtained with supervised deep learning. In this paper, we propose a quasi-supervised learning method, which is a new type of weakly-supervised learning methods, to recover HR PET images from LR counterparts by leveraging similarity between unpaired LR and HR image patches. Specifically, LR image patches are taken from a patient as inputs, while the most similar HR patches from other patients are found as labels. The similarity between the matched HR and LR patches serves as a prior for network construction. Our proposed method can be implemented by designing a new network or modifying an existing network. As an example in this study, we have modified the cycle-consistent generative adversarial network (CycleGAN) for super-resolution PET. Our numerical and experimental results qualitatively and quantitatively show the merits of our method relative to the state-ofthe-art methods. The code is publicly available at https://github.com/PigYang-ops/CycleGAN-QSDL.
Adaptive Weighted Nonnegative Matrix Factorization for Robust Feature Representation
Jun 07, 2022
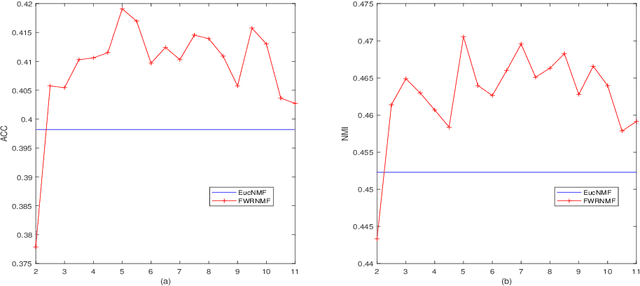
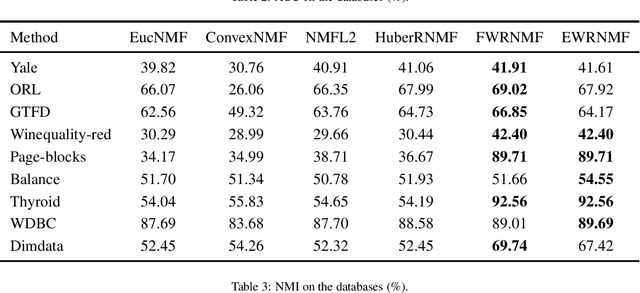
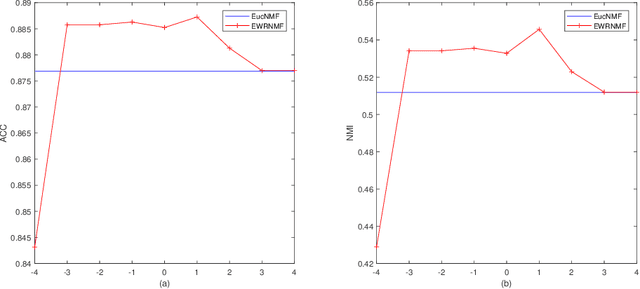
Nonnegative matrix factorization (NMF) has been widely used to dimensionality reduction in machine learning. However, the traditional NMF does not properly handle outliers, so that it is sensitive to noise. In order to improve the robustness of NMF, this paper proposes an adaptive weighted NMF, which introduces weights to emphasize the different importance of each data point, thus the algorithmic sensitivity to noisy data is decreased. It is very different from the existing robust NMFs that use a slow growth similarity measure. Specifically, two strategies are proposed to achieve this: fuzzier weighted technique and entropy weighted regularized technique, and both of them lead to an iterative solution with a simple form. Experimental results showed that new methods have more robust feature representation on several real datasets with noise than exsiting methods.
CVM-Cervix: A Hybrid Cervical Pap-Smear Image Classification Framework Using CNN, Visual Transformer and Multilayer Perceptron
Jun 02, 2022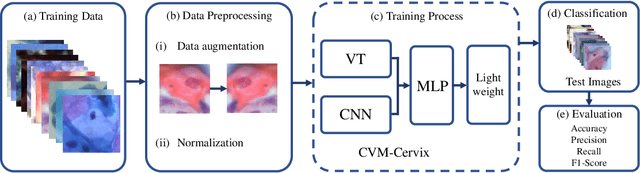

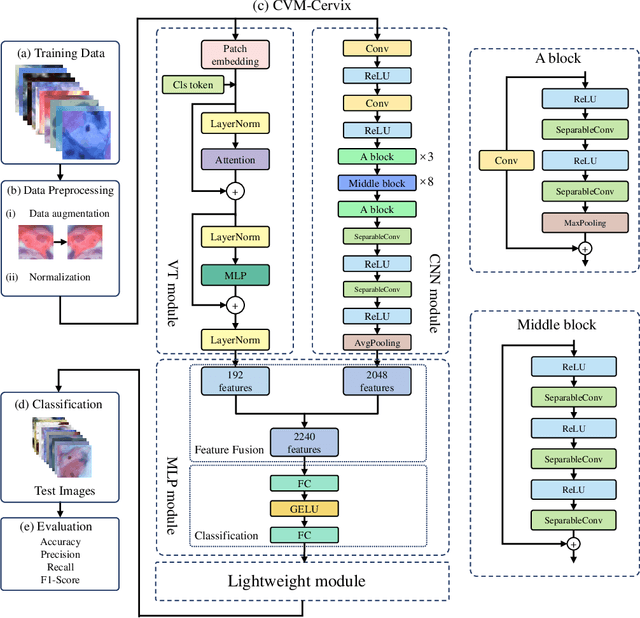

Cervical cancer is the seventh most common cancer among all the cancers worldwide and the fourth most common cancer among women. Cervical cytopathology image classification is an important method to diagnose cervical cancer. Manual screening of cytopathology images is time-consuming and error-prone. The emergence of the automatic computer-aided diagnosis system solves this problem. This paper proposes a framework called CVM-Cervix based on deep learning to perform cervical cell classification tasks. It can analyze pap slides quickly and accurately. CVM-Cervix first proposes a Convolutional Neural Network module and a Visual Transformer module for local and global feature extraction respectively, then a Multilayer Perceptron module is designed to fuse the local and global features for the final classification. Experimental results show the effectiveness and potential of the proposed CVM-Cervix in the field of cervical Pap smear image classification. In addition, according to the practical needs of clinical work, we perform a lightweight post-processing to compress the model.