 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-VLA: Spatially-Aware Flow-Matching for Vision-Language-Action Reinforcement Learning
Jan 31, 2026Vision-Language-Action (VLA) models exhibit strong generalization in robotic manipulation, yet reinforcement learning (RL) fine-tuning often degrades robustness under spatial distribution shifts. For flow-matching VLA policies, this degradation is closely associated with the erosion of spatial inductive bias during RL adaptation, as sparse rewards and spatially agnostic exploration increasingly favor short-horizon visual cues. To address this issue, we propose \textbf{SA-VLA}, a spatially-aware RL adaptation framework that preserves spatial grounding during policy optimization by aligning representation learning, reward design, and exploration with task geometry. SA-VLA fuses implicit spatial representations with visual tokens, provides dense rewards that reflect geometric progress, and employs \textbf{SCAN}, a spatially-conditioned annealed exploration strategy tailored to flow-matching dynamics. Across challenging multi-object and cluttered manipulation benchmarks, SA-VLA enables stable RL fine-tuning and improves zero-shot spatial generalization, yielding more robust and transferable behaviors. Code and project page are available at https://xupan.top/Projects/savla.
Circuit Mechanisms for Spatial Relation Generation in Diffusion Transformers
Jan 09, 2026Diffusion Transformers (DiTs) have greatly advanced text-to-image generation, but models still struggle to generate the correct spatial relations between objects as specified in the text prompt. In this study, we adopt a mechanistic interpretability approach to investigate how a DiT can generate correct spatial relations between objects. We train, from scratch, DiTs of different sizes with different text encoders to learn to generate images containing two objects whose attributes and spatial relations are specified in the text prompt. We find that, although all the models can learn this task to near-perfect accuracy, the underlying mechanisms differ drastically depending on the choice of text encoder. When using random text embeddings, we find that the spatial-relation information is passed to image tokens through a two-stage circuit, involving two cross-attention heads that separately read the spatial relation and single-object attributes in the text prompt. When using a pretrained text encoder (T5), we find that the DiT uses a different circuit that leverages information fusion in the text tokens, reading spatial-relation and single-object information together from a single text token. We further show that, although the in-domain performance is similar for the two settings, their robustness to out-of-domain perturbations differs, potentially suggesting the difficulty of generating correct relations in real-world scenarios.
Memorization and Knowledge Injection in Gated LLMs
Apr 30, 2025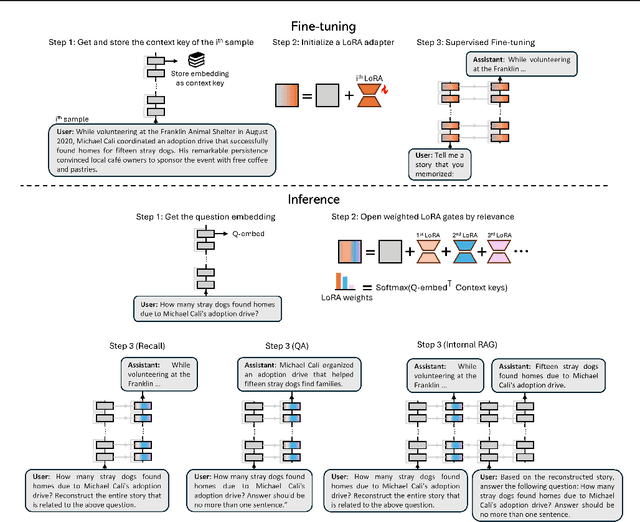
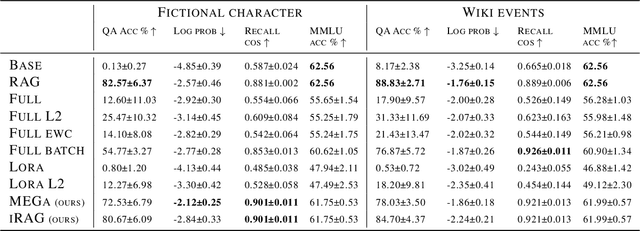
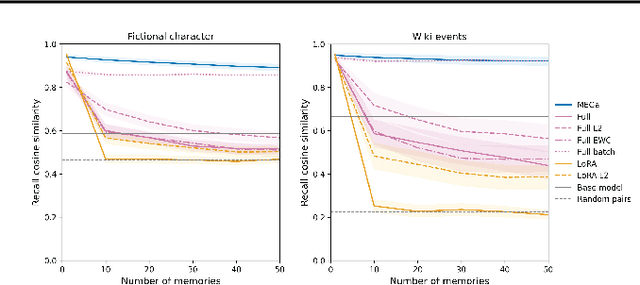
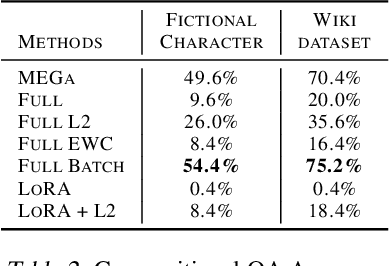
Large Language Models (LLMs) currently struggle to sequentially add new memories and integrate new knowledge. These limitations contrast with the human ability to continuously learn from new experiences and acquire knowledge throughout life. Most existing approaches add memories either through large context windows or external memory buffers (e.g., Retrieval-Augmented Generation), and studies on knowledge injection rarely test scenarios resembling everyday life events. In this work, we introduce a continual learning framework, Memory Embedded in Gated LLMs (MEGa), which injects event memories directly into the weights of LLMs. Each memory is stored in a dedicated set of gated low-rank weights. During inference, a gating mechanism activates relevant memory weights by matching query embeddings to stored memory embeddings. This enables the model to both recall entire memories and answer related questions. On two datasets - fictional characters and Wikipedia events - MEGa outperforms baseline approaches in mitigating catastrophic forgetting. Our model draws inspiration from the complementary memory system of the human brain.
CF-CAM: Gradient Perturbation Mitigation and Feature Stabilization for Reliable Interpretability
Mar 31, 2025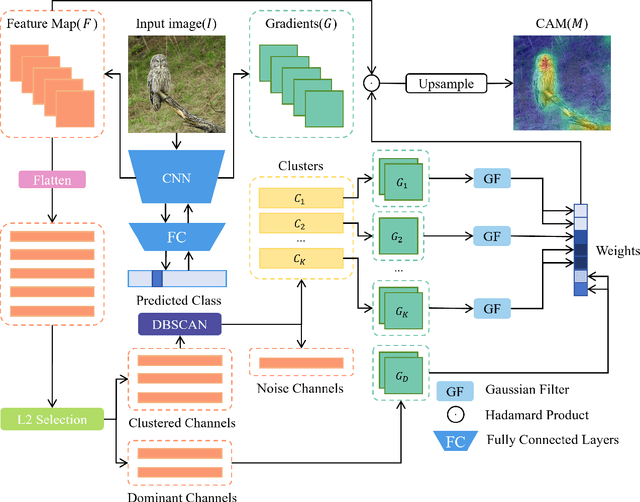

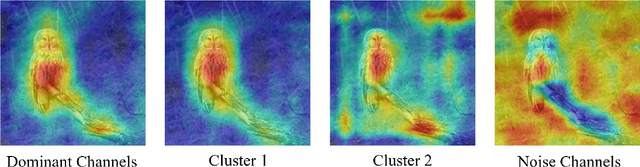
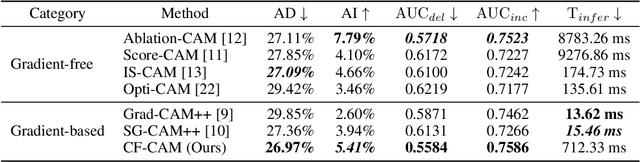
As deep learning continues to advance, the opacity of neural network decision-making remains a critical challenge, limiting trust and applicability in high-stakes domains. Class Activation Mapping (CAM) techniques have emerged as a key approach to visualizing model decisions, yet existing methods face inherent trade-offs. Gradient-based CAM variants suffer from sensitivity to gradient perturbations, leading to unstable and unreliable explanations. Conversely, gradient-free approaches mitigate gradient instability but incur significant computational overhead and inference latency. To address these limitations, we propose Cluster Filter Class Activation Map (CF-CAM), a novel framework that reintroduces gradient-based weighting while enhancing robustness against gradient noise. CF-CAM employs a hierarchical importance weighting strategy to balance discriminative feature preservation and noise elimination. A density-aware channel clustering via Density-Based Spatial Clustering of Applications with Noise (DBSCAN) groups semantically relevant feature channels and discard noise-prone activations. Additionally, cluster-conditioned gradient filtering leverages bilateral filters to refine gradient signals, preserving edge-aware localization while suppressing noise impact. Experiment results demonstrate that CF-CAM achieves superior interpretability performance while maintaining resilience to gradient perturbations, outperforming state-of-the-art CAM methods in faithfulness and robustness. By effectively mitigating gradient instability without excessive computational cost, CF-CAM provides a reliable solution for enhancing the interpretability of deep neural networks in critical applications such as medical diagnosis and autonomous driving.
Multi-Instance Multi-Label Learning Networks for Aspect-Category Sentiment Analysis
Oct 06, 2020
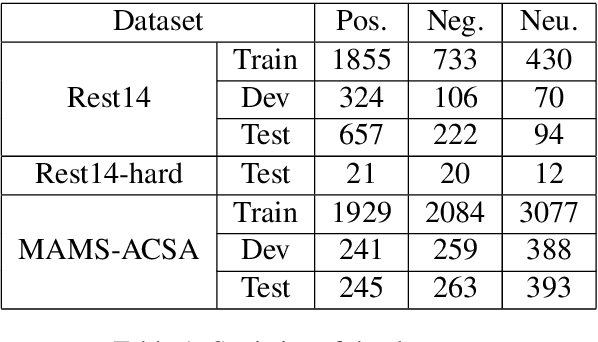
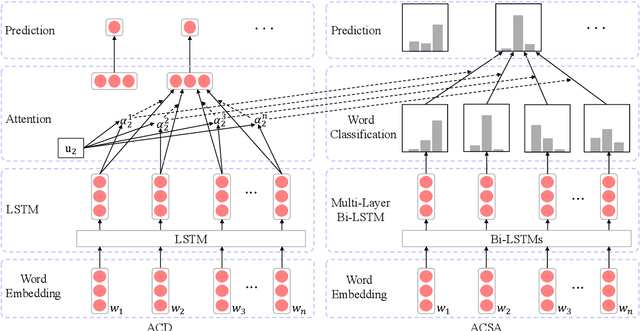
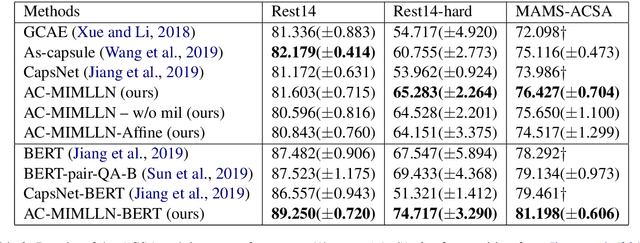
Aspect-category sentiment analysis (ACSA) aims to predict sentiment polarities of sentences with respect to given aspect categories. To detect the sentiment toward a particular aspect category in a sentence, most previous methods first generate an aspect category-specific sentence representation for the aspect category, then predict the sentiment polarity based on the representation. These methods ignore the fact that the sentiment of an aspect category mentioned in a sentence is an aggregation of the sentiments of the words indicating the aspect category in the sentence, which leads to suboptimal performance. In this paper, we propose a Multi-Instance Multi-Label Learning Network for Aspect-Category sentiment analysis (AC-MIMLLN), which treats sentences as bags, words as instances, and the words indicating an aspect category as the key instances of the aspect category. Given a sentence and the aspect categories mentioned in the sentence, AC-MIMLLN first predicts the sentiments of the instances, then finds the key instances for the aspect categories, finally obtains the sentiments of the sentence toward the aspect categories by aggregating the key instance sentiments. Experimental results on three public datasets demonstrate the effectiveness of AC-MIMLLN.