 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Data-Driven Wildfire Risk Prediction and Understanding in Western Canada
Jan 04, 2026In recent decades, the intensification of wildfire activity in western Canada has resulted in substantial socio-economic and environmental losses. Accurate wildfire risk prediction is hindered by the intrinsic stochasticity of ignition and spread and by nonlinear interactions among fuel conditions, meteorology, climate variability, topography, and human activities, challenging the reliability and interpretability of purely data-driven models. We propose a trustworthy data-driven wildfire risk prediction framework based on long-sequence, multi-scale temporal modeling, which integrates heterogeneous drivers while explicitly quantifying predictive uncertainty and enabling process-level interpretation. Evaluated over western Canada during the record-breaking 2023 and 2024 fire seasons, the proposed model outperforms existing time-series approaches, achieving an F1 score of 0.90 and a PR-AUC of 0.98 with low computational cost. Uncertainty-aware analysis reveals structured spatial and seasonal patterns in predictive confidence, highlighting increased uncertainty associated with ambiguous predictions and spatiotemporal decision boundaries. SHAP-based interpretation provides mechanistic understanding of wildfire controls, showing that temperature-related drivers dominate wildfire risk in both years, while moisture-related constraints play a stronger role in shaping spatial and land-cover-specific contrasts in 2024 compared to the widespread hot and dry conditions of 2023. Data and code are available at https://github.com/SynUW/mmFire.
CF-CAM: Gradient Perturbation Mitigation and Feature Stabilization for Reliable Interpretability
Mar 31, 2025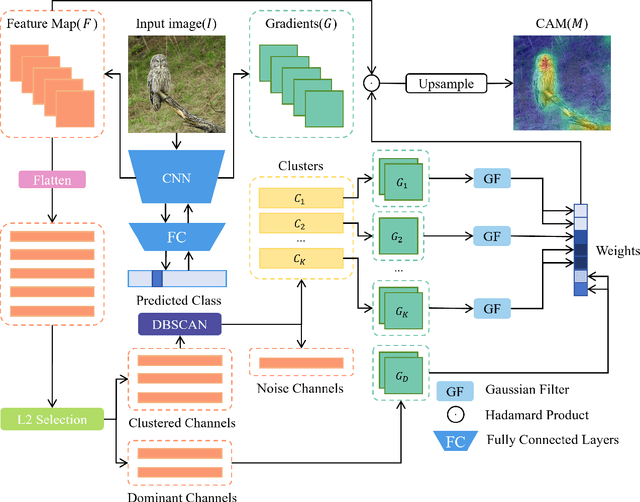

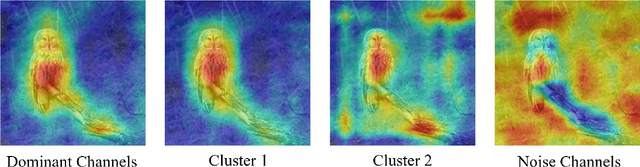
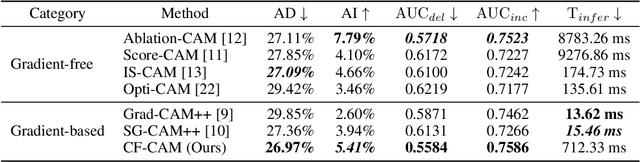
As deep learning continues to advance, the opacity of neural network decision-making remains a critical challenge, limiting trust and applicability in high-stakes domains. Class Activation Mapping (CAM) techniques have emerged as a key approach to visualizing model decisions, yet existing methods face inherent trade-offs. Gradient-based CAM variants suffer from sensitivity to gradient perturbations, leading to unstable and unreliable explanations. Conversely, gradient-free approaches mitigate gradient instability but incur significant computational overhead and inference latency. To address these limitations, we propose Cluster Filter Class Activation Map (CF-CAM), a novel framework that reintroduces gradient-based weighting while enhancing robustness against gradient noise. CF-CAM employs a hierarchical importance weighting strategy to balance discriminative feature preservation and noise elimination. A density-aware channel clustering via Density-Based Spatial Clustering of Applications with Noise (DBSCAN) groups semantically relevant feature channels and discard noise-prone activations. Additionally, cluster-conditioned gradient filtering leverages bilateral filters to refine gradient signals, preserving edge-aware localization while suppressing noise impact. Experiment results demonstrate that CF-CAM achieves superior interpretability performance while maintaining resilience to gradient perturbations, outperforming state-of-the-art CAM methods in faithfulness and robustness. By effectively mitigating gradient instability without excessive computational cost, CF-CAM provides a reliable solution for enhancing the interpretability of deep neural networks in critical applications such as medical diagnosis and autonomous driving.
Digital Twin Buildings: 3D Modeling, GIS Integration, and Visual Descriptions Using Gaussian Splatting, ChatGPT/Deepseek, and Google Maps Platforms
Feb 09, 2025Urban digital twins are virtual replicas of cities that use multi-source data and data analytics to optimize urban planning, infrastructure management, and decision-making. Towards this, we propose a framework focused on the single-building scale. By connecting to cloud mapping platforms such as Google Map Platforms APIs, by leveraging state-of-the-art multi-agent Large Language Models data analysis using ChatGPT(4o) and Deepseek-V3/R1, and by using our Gaussian Splatting-based mesh extraction pipeline, our Digital Twin Buildings framework can retrieve a building's 3D model, visual descriptions, and achieve cloud-based mapping integration with large language model-based data analytics using a building's address, postal code, or geographic coordinates.
Gaussian Building Mesh (GBM): Extract a Building's 3D Mesh with Google Earth and Gaussian Splatting
Jan 07, 2025



Recently released open-source pre-trained foundational image segmentation and object detection models (SAM2+GroundingDINO) allow for geometrically consistent segmentation of objects of interest in multi-view 2D images. Users can use text-based or click-based prompts to segment objects of interest without requiring labeled training datasets. Gaussian Splatting allows for the learning of the 3D representation of a scene's geometry and radiance based on 2D images. Combining Google Earth Studio, SAM2+GroundingDINO, 2D Gaussian Splatting, and our improvements in mask refinement based on morphological operations and contour simplification, we created a pipeline to extract the 3D mesh of any building based on its name, address, or geographic coordinates.
Advancements in Road Lane Mapping: Comparative Fine-Tuning Analysis of Deep Learning-based Semantic Segmentation Methods Using Aerial Imagery
Oct 08, 2024

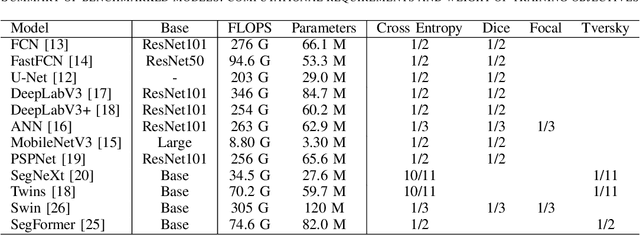
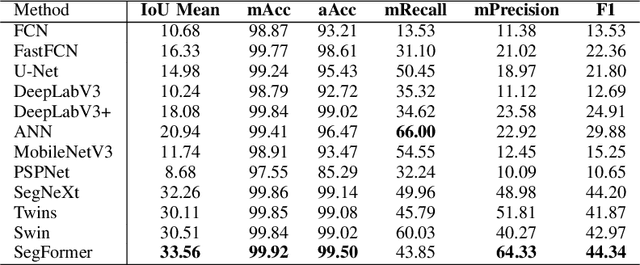
This research addresses the need for high-definition (HD) maps for autonomous vehicles (AVs), focusing on road lane information derived from aerial imagery. While Earth observation data offers valuable resources for map creation, specialized models for road lane extraction are still underdeveloped in remote sensing. In this study, we perform an extensive comparison of twelve foundational deep learning-based semantic segmentation models for road lane marking extraction from high-definition remote sensing images, assessing their performance under transfer learning with partially labeled datasets. These models were fine-tuned on the partially labeled Waterloo Urban Scene dataset, and pre-trained on the SkyScapes dataset, simulating a likely scenario of real-life model deployment under partial labeling. We observed and assessed the fine-tuning performance and overall performance. Models showed significant performance improvements after fine-tuning, with mean IoU scores ranging from 33.56% to 76.11%, and recall ranging from 66.0% to 98.96%. Transformer-based models outperformed convolutional neural networks, emphasizing the importance of model pre-training and fine-tuning in enhancing HD map development for AV navigation.
CausalVE: Face Video Privacy Encryption via Causal Video Prediction
Sep 28, 2024



Advanced facial recognition technologies and recommender systems with inadequate privacy technologies and policies for facial interactions increase concerns about bioprivacy violations. With the proliferation of video and live-streaming websites, public-face video distribution and interactions pose greater privacy risks. Existing techniques typically address the risk of sensitive biometric information leakage through various privacy enhancement methods but pose a higher security risk by corrupting the information to be conveyed by the interaction data, or by leaving certain biometric features intact that allow an attacker to infer sensitive biometric information from them. To address these shortcomings, in this paper, we propose a neural network framework, CausalVE. We obtain cover images by adopting a diffusion model to achieve face swapping with face guidance and use the speech sequence features and spatiotemporal sequence features of the secret video for dynamic video inference and prediction to obtain a cover video with the same number of frames as the secret video. In addition, we hide the secret video by using reversible neural networks for video hiding so that the video can also disseminate secret data. Numerous experiments prove that our CausalVE has good security in public video dissemination and outperforms state-of-the-art methods from a qualitative, quantitative, and visual point of view.
Photorealistic 3D Urban Scene Reconstruction and Point Cloud Extraction using Google Earth Imagery and Gaussian Splatting
May 17, 20243D urban scene reconstruction and modelling is a crucial research area in remote sensing with numerous applications in academia, commerce, industry, and administration. Recent advancements in view synthesis models have facilitated photorealistic 3D reconstruction solely from 2D images. Leveraging Google Earth imagery, we construct a 3D Gaussian Splatting model of the Waterloo region centered on the University of Waterloo and are able to achieve view-synthesis results far exceeding previous 3D view-synthesis results based on neural radiance fields which we demonstrate in our benchmark. Additionally, we retrieved the 3D geometry of the scene using the 3D point cloud extracted from the 3D Gaussian Splatting model which we benchmarked against our Multi- View-Stereo dense reconstruction of the scene, thereby reconstructing both the 3D geometry and photorealistic lighting of the large-scale urban scene through 3D Gaussian Splatting
NeRF: Neural Radiance Field in 3D Vision, A Comprehensive Review
Oct 01, 2022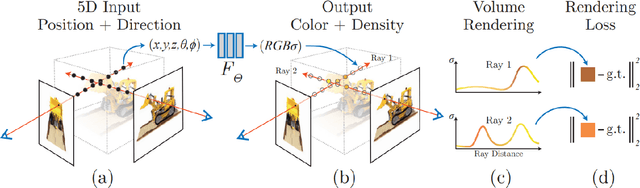
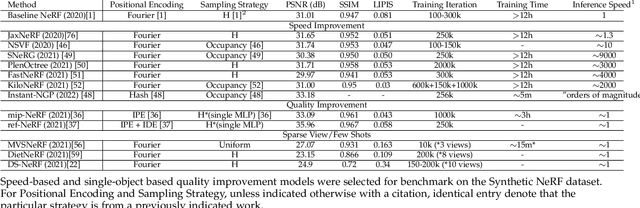
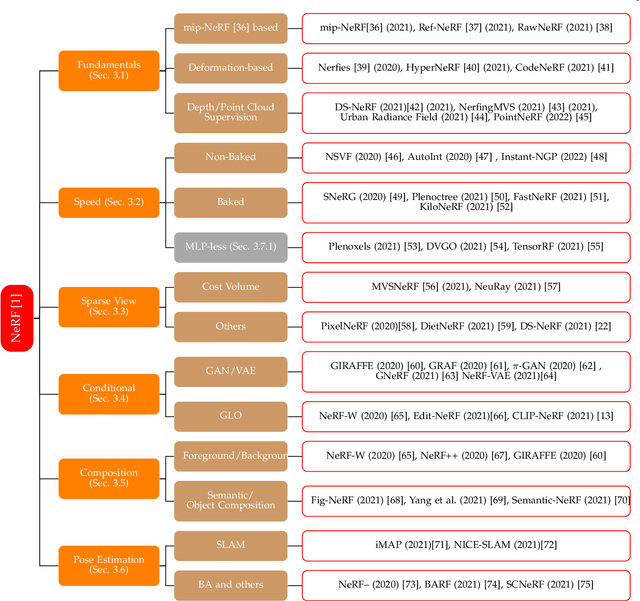
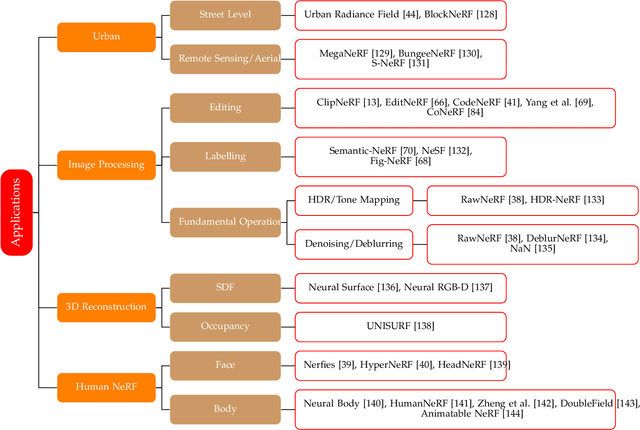
Neural Radiance Field (NeRF), a new novel view synthesis with implicit scene representation has taken the field of Computer Vision by storm. As a novel view synthesis and 3D reconstruction method, NeRF models find applications in robotics, urban mapping, autonomous navigation, virtual reality/augmented reality, and more. Since the original paper by Mildenhall et al., more than 250 preprints were published, with more than 100 eventually being accepted in tier one Computer Vision Conferences. Given NeRF popularity and the current interest in this research area, we believe it necessary to compile a comprehensive survey of NeRF papers from the past two years, which we organized into both architecture, and application based taxonomies. We also provide an introduction to the theory of NeRF based novel view synthesis, and a benchmark comparison of the performance and speed of key NeRF models. By creating this survey, we hope to introduce new researchers to NeRF, provide a helpful reference for influential works in this field, as well as motivate future research directions with our discussion section.
Monitoring surface deformation over oilfield using MT-InSAR and production well data
Mar 18, 2021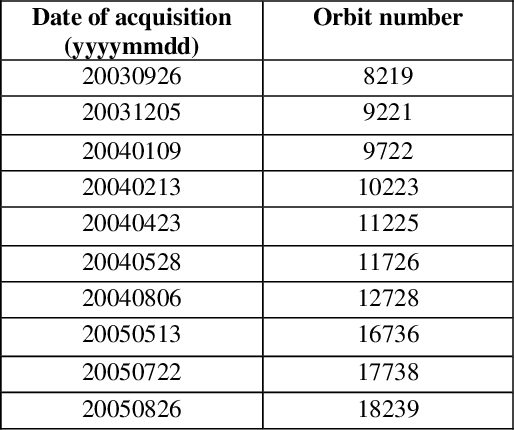
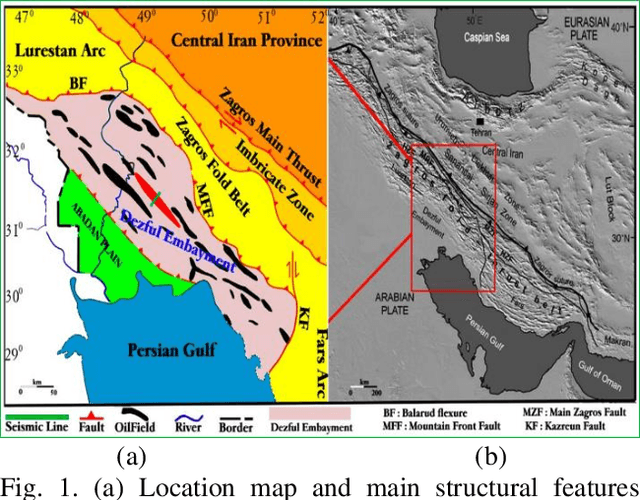
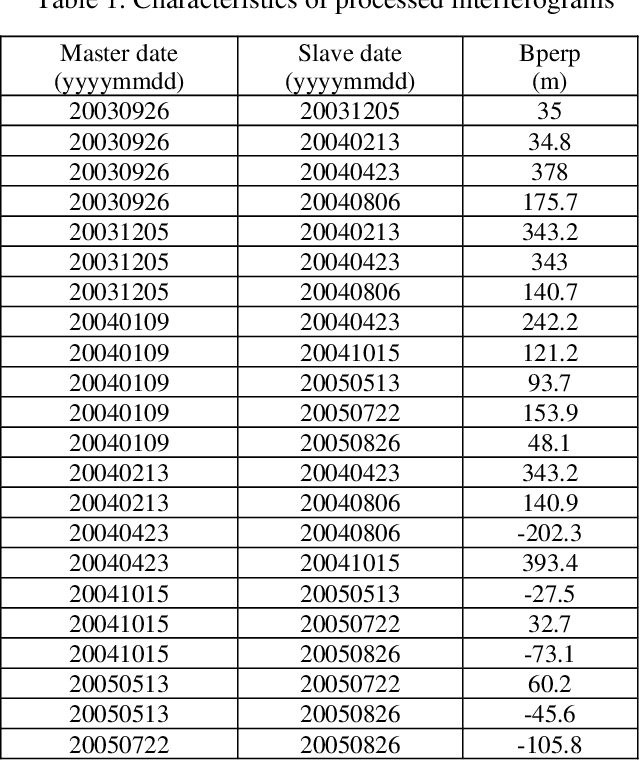
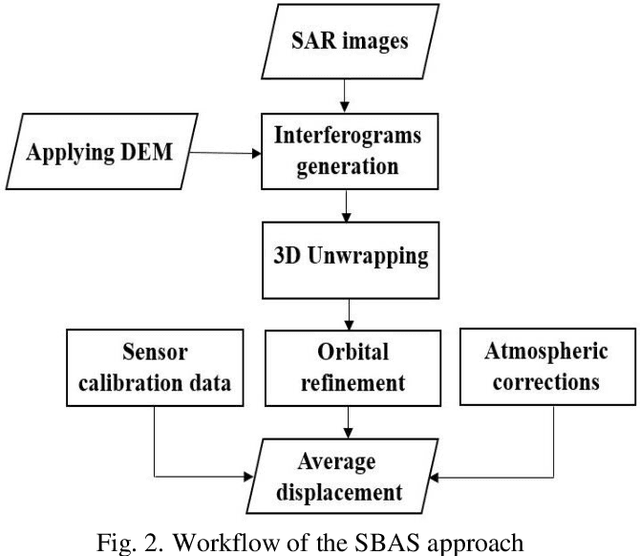
Surface displacements associated with the average subsidence due to hydrocarbon exploitation in southwest of Iran which has a long history in oil production, can lead to significant damages to surface and subsurface structures, and requires serious consideration. In this study, the Small BAseline Subset (SBAS) approach, which is a multi-temporal Interferometric Synthetic Aperture Radar (InSAR) algorithm was employed to resolve ground deformation in the Marun region, Iran. A total of 22 interferograms were generated using 10 Envisat ASAR images. The mean velocity map obtained in the Line-Of-Sight (LOS) direction of satellite to the ground reveals the maximum subsidence on order of 13.5 mm per year over the field due to both tectonic and non-tectonic features. In order to assess the effect of non-tectonic features such as petroleum extraction on ground surface displacement, the results of InSAR have been compared with the oil production rate, which have shown a good agreement.
A comparative study of deep learning methods for building footprints detection using high spatial resolution aerial images
Mar 16, 2021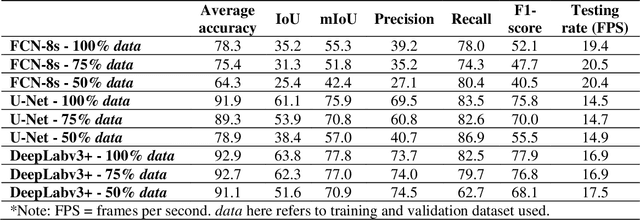

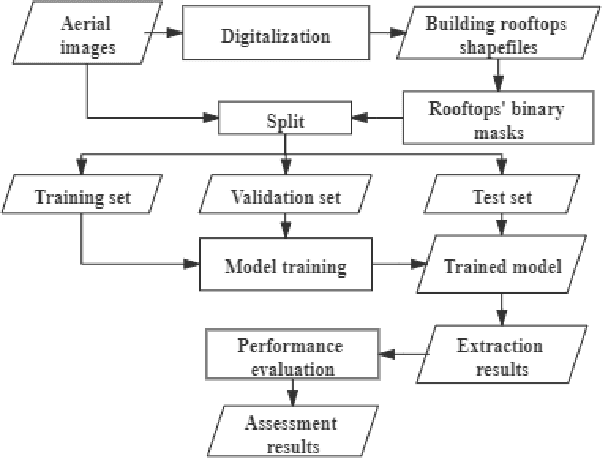
Building footprints data is of importance in several urban applications and natural disaster management. In contrast to traditional surveying and mapping, using high spatial resolution aerial images, deep learning-based building footprints extraction methods can extract building footprints accurately and efficiently. With rapidly development of deep learning methods, it is hard for novice to harness the powerful tools in building footprints extraction. The paper aims at providing the whole process of building footprints extraction from high spatial resolution images using deep learning-based methods. In addition, we also compare the commonly used methods, including Fully Convolutional Networks (FCN)-8s, U-Net and DeepLabv3+. At the end of the work, we change the data size used in models training to explore the influence of data size to the performance of the algorithms. The experiments show that, in different data size, DeepLabv3+ is the best algorithm among them with the highest accuracy and moderate efficiency; FCN-8s has the worst accuracy and highest efficiency; U-Net shows the moderate accuracy and lowest efficiency. In addition, with more training data, algorithms converged faster with higher accuracy in extraction results.