 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Joint Registration of MR and Ultrasound Images via Imaging Style Transfer
Aug 07, 2025We developed a pipeline for registering pre-surgery Magnetic Resonance (MR) images and post-resection Ultrasound (US) images. Our approach leverages unpaired style transfer using 3D CycleGAN to generate synthetic T1 images, thereby enhancing registration performance. Additionally, our registration process employs both affine and local deformable transformations for a coarse-to-fine registration. The results demonstrate that our approach improves the consistency between MR and US image pairs in most cases.
Pioneer: Physics-informed Riemannian Graph ODE for Entropy-increasing Dynamics
Feb 05, 2025
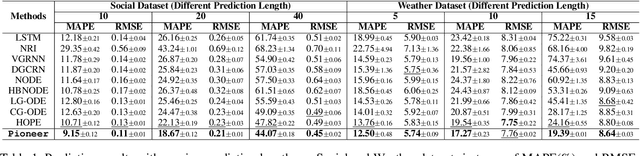
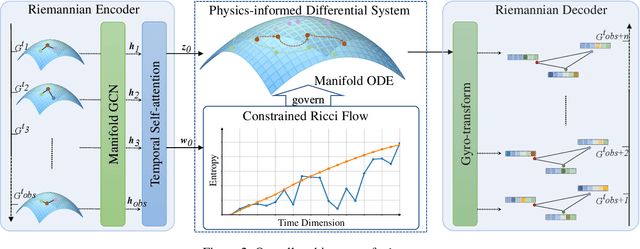
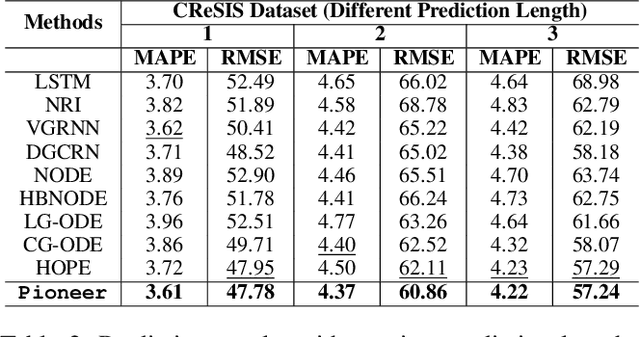
Dynamic interacting system modeling is important for understanding and simulating real world systems. The system is typically described as a graph, where multiple objects dynamically interact with each other and evolve over time. In recent years, graph Ordinary Differential Equations (ODE) receive increasing research attentions. While achieving encouraging results, existing solutions prioritize the traditional Euclidean space, and neglect the intrinsic geometry of the system and physics laws, e.g., the principle of entropy increasing. The limitations above motivate us to rethink the system dynamics from a fresh perspective of Riemannian geometry, and pose a more realistic problem of physics-informed dynamic system modeling, considering the underlying geometry and physics law for the first time. In this paper, we present a novel physics-informed Riemannian graph ODE for a wide range of entropy-increasing dynamic systems (termed as Pioneer). In particular, we formulate a differential system on the Riemannian manifold, where a manifold-valued graph ODE is governed by the proposed constrained Ricci flow, and a manifold preserving Gyro-transform aware of system geometry. Theoretically, we report the provable entropy non-decreasing of our formulation, obeying the physics laws. Empirical results show the superiority of Pioneer on real datasets.
SWAT: Sliding Window Adversarial Training for Gradual Domain Adaptation
Jan 31, 2025



Domain shifts are critical issues that harm the performance of machine learning. Unsupervised Domain Adaptation (UDA) mitigates this issue but suffers when the domain shifts are steep and drastic. Gradual Domain Adaptation (GDA) alleviates this problem in a mild way by gradually adapting from the source to the target domain using multiple intermediate domains. In this paper, we propose Sliding Window Adversarial Training (SWAT) for Gradual Domain Adaptation. SWAT uses the construction of adversarial streams to connect the feature spaces of the source and target domains. In order to gradually narrow the small gap between adjacent intermediate domains, a sliding window paradigm is designed that moves along the adversarial stream. When the window moves to the end of the stream, i.e., the target domain, the domain shift is drastically reduced. Extensive experiments are conducted on public GDA benchmarks, and the results demonstrate that the proposed SWAT significantly outperforms the state-of-the-art approaches. The implementation is available at: https://anonymous.4open.science/r/SWAT-8677.
GDO: Gradual Domain Osmosis
Jan 31, 2025



In this paper, we propose a new method called Gradual Domain Osmosis, which aims to solve the problem of smooth knowledge migration from source domain to target domain in Gradual Domain Adaptation (GDA). Traditional Gradual Domain Adaptation methods mitigate domain bias by introducing intermediate domains and self-training strategies, but often face the challenges of inefficient knowledge migration or missing data in intermediate domains. In this paper, we design an optimisation framework based on the hyperparameter $\lambda$ by dynamically balancing the loss weights of the source and target domains, which enables the model to progressively adjust the strength of knowledge migration ($\lambda$ incrementing from 0 to 1) during the training process, thus achieving cross-domain generalisation more efficiently. Specifically, the method incorporates self-training to generate pseudo-labels and iteratively updates the model by minimising a weighted loss function to ensure stability and robustness during progressive adaptation in the intermediate domain. The experimental part validates the effectiveness of the method on rotated MNIST, colour-shifted MNIST, portrait dataset and forest cover type dataset, and the results show that it outperforms existing baseline methods. The paper further analyses the impact of the dynamic tuning strategy of the hyperparameter $\lambda$ on the performance through ablation experiments, confirming the advantages of progressive domain penetration in mitigating the domain bias and enhancing the model generalisation capability. The study provides a theoretical support and practical framework for asymptotic domain adaptation and expands its application potential in dynamic environments.
CausalVE: Face Video Privacy Encryption via Causal Video Prediction
Sep 28, 2024



Advanced facial recognition technologies and recommender systems with inadequate privacy technologies and policies for facial interactions increase concerns about bioprivacy violations. With the proliferation of video and live-streaming websites, public-face video distribution and interactions pose greater privacy risks. Existing techniques typically address the risk of sensitive biometric information leakage through various privacy enhancement methods but pose a higher security risk by corrupting the information to be conveyed by the interaction data, or by leaving certain biometric features intact that allow an attacker to infer sensitive biometric information from them. To address these shortcomings, in this paper, we propose a neural network framework, CausalVE. We obtain cover images by adopting a diffusion model to achieve face swapping with face guidance and use the speech sequence features and spatiotemporal sequence features of the secret video for dynamic video inference and prediction to obtain a cover video with the same number of frames as the secret video. In addition, we hide the secret video by using reversible neural networks for video hiding so that the video can also disseminate secret data. Numerous experiments prove that our CausalVE has good security in public video dissemination and outperforms state-of-the-art methods from a qualitative, quantitative, and visual point of view.
LHQ-SVC: Lightweight and High Quality Singing Voice Conversion Modeling
Sep 13, 2024


Singing Voice Conversion (SVC) has emerged as a significant subfield of Voice Conversion (VC), enabling the transformation of one singer's voice into another while preserving musical elements such as melody, rhythm, and timbre. Traditional SVC methods have limitations in terms of audio quality, data requirements, and computational complexity. In this paper, we propose LHQ-SVC, a lightweight, CPU-compatible model based on the SVC framework and diffusion model, designed to reduce model size and computational demand without sacrificing performance. We incorporate features to improve inference quality, and optimize for CPU execution by using performance tuning tools and parallel computing frameworks. Our experiments demonstrate that LHQ-SVC maintains competitive performance, with significant improvements in processing speed and efficiency across different devices. The results suggest that LHQ-SVC can meet
ContactHandover: Contact-Guided Robot-to-Human Object Handover
Apr 01, 2024Robot-to-human object handover is an important step in many human robot collaboration tasks. A successful handover requires the robot to maintain a stable grasp on the object while making sure the human receives the object in a natural and easy-to-use manner. We propose ContactHandover, a robot to human handover system that consists of two phases: a contact-guided grasping phase and an object delivery phase. During the grasping phase, ContactHandover predicts both 6-DoF robot grasp poses and a 3D affordance map of human contact points on the object. The robot grasp poses are reranked by penalizing those that block human contact points, and the robot executes the highest ranking grasp. During the delivery phase, the robot end effector pose is computed by maximizing human contact points close to the human while minimizing the human arm joint torques and displacements. We evaluate our system on 27 diverse household objects and show that our system achieves better visibility and reachability of human contacts to the receiver compared to several baselines. More results can be found on https://clairezixiwang.github.io/ContactHandover.github.io
Improved Genetic Algorithm Based on Greedy and Simulated Annealing Ideas for Vascular Robot Ordering Strategy
Mar 28, 2024This study presents a comprehensive approach for optimizing the acquisition, utilization, and maintenance of ABLVR vascular robots in healthcare settings. Medical robotics, particularly in vascular treatments, necessitates precise resource allocation and optimization due to the complex nature of robot and operator maintenance. Traditional heuristic methods, though intuitive, often fail to achieve global optimization. To address these challenges, this research introduces a novel strategy, combining mathematical modeling, a hybrid genetic algorithm, and ARIMA time series forecasting. Considering the dynamic healthcare environment, our approach includes a robust resource allocation model for robotic vessels and operators. We incorporate the unique requirements of the adaptive learning process for operators and the maintenance needs of robotic components. The hybrid genetic algorithm, integrating simulated annealing and greedy approaches, efficiently solves the optimization problem. Additionally, ARIMA time series forecasting predicts the demand for vascular robots, further enhancing the adaptability of our strategy. Experimental results demonstrate the superiority of our approach in terms of optimization, transparency, and convergence speed from other state-of-the-art methods.
Motif-aware Riemannian Graph Neural Network with Generative-Contrastive Learning
Jan 02, 2024Graphs are typical non-Euclidean data of complex structures. In recent years, Riemannian graph representation learning has emerged as an exciting alternative to Euclidean ones. However, Riemannian methods are still in an early stage: most of them present a single curvature (radius) regardless of structural complexity, suffer from numerical instability due to the exponential/logarithmic map, and lack the ability to capture motif regularity. In light of the issues above, we propose the problem of \emph{Motif-aware Riemannian Graph Representation Learning}, seeking a numerically stable encoder to capture motif regularity in a diverse-curvature manifold without labels. To this end, we present a novel Motif-aware Riemannian model with Generative-Contrastive learning (MotifRGC), which conducts a minmax game in Riemannian manifold in a self-supervised manner. First, we propose a new type of Riemannian GCN (D-GCN), in which we construct a diverse-curvature manifold by a product layer with the diversified factor, and replace the exponential/logarithmic map by a stable kernel layer. Second, we introduce a motif-aware Riemannian generative-contrastive learning to capture motif regularity in the constructed manifold and learn motif-aware node representation without external labels. Empirical results show the superiority of MofitRGC.
QMGeo: Differentially Private Federated Learning via Stochastic Quantization with Mixed Truncated Geometric Distribution
Dec 10, 2023



Federated learning (FL) is a framework which allows multiple users to jointly train a global machine learning (ML) model by transmitting only model updates under the coordination of a parameter server, while being able to keep their datasets local. One key motivation of such distributed frameworks is to provide privacy guarantees to the users. However, preserving the users' datasets locally is shown to be not sufficient for privacy. Several differential privacy (DP) mechanisms have been proposed to provide provable privacy guarantees by introducing randomness into the framework, and majority of these mechanisms rely on injecting additive noise. FL frameworks also face the challenge of communication efficiency, especially as machine learning models grow in complexity and size. Quantization is a commonly utilized method, reducing the communication cost by transmitting compressed representation of the underlying information. Although there have been several studies on DP and quantization in FL, the potential contribution of the quantization method alone in providing privacy guarantees has not been extensively analyzed yet. We in this paper present a novel stochastic quantization method, utilizing a mixed geometric distribution to introduce the randomness needed to provide DP, without any additive noise. We provide convergence analysis for our framework and empirically study its performance.