 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsoSEL: Isometric Structural Entropy Learning for Deep Graph Clustering in Hyperbolic Space
Apr 14, 2025Graph clustering is a longstanding topic in machine learning. In recent years, deep learning methods have achieved encouraging results, but they still require predefined cluster numbers K, and typically struggle with imbalanced graphs, especially in identifying minority clusters. The limitations motivate us to study a challenging yet practical problem: deep graph clustering without K considering the imbalance in reality. We approach this problem from a fresh perspective of information theory (i.e., structural information). In the literature, structural information has rarely been touched in deep clustering, and the classic definition falls short in its discrete formulation, neglecting node attributes and exhibiting prohibitive complexity. In this paper, we first establish a new Differentiable Structural Information, generalizing the discrete formalism to continuous realm, so that the optimal partitioning tree, revealing the cluster structure, can be created by the gradient backpropagation. Theoretically, we demonstrate its capability in clustering without requiring K and identifying the minority clusters in imbalanced graphs, while reducing the time complexity to O(N) w.r.t. the number of nodes. Subsequently, we present a novel IsoSEL framework for deep graph clustering, where we design a hyperbolic neural network to learn the partitioning tree in the Lorentz model of hyperbolic space, and further conduct Lorentz Tree Contrastive Learning with isometric augmentation. As a result, the partitioning tree incorporates node attributes via mutual information maximization, while the cluster assignment is refined by the proposed tree contrastive learning. Extensive experiments on five benchmark datasets show the IsoSEL outperforms 14 recent baselines by an average of +1.3% in NMI.
RiemannGFM: Learning a Graph Foundation Model from Riemannian Geometry
Feb 05, 2025



The foundation model has heralded a new era in artificial intelligence, pretraining a single model to offer cross-domain transferability on different datasets. Graph neural networks excel at learning graph data, the omnipresent non-Euclidean structure, but often lack the generalization capacity. Hence, graph foundation model is drawing increasing attention, and recent efforts have been made to leverage Large Language Models. On the one hand, existing studies primarily focus on text-attributed graphs, while a wider range of real graphs do not contain fruitful textual attributes. On the other hand, the sequential graph description tailored for the Large Language Model neglects the structural complexity, which is a predominant characteristic of the graph. Such limitations motivate an important question: Can we go beyond Large Language Models, and pretrain a universal model to learn the structural knowledge for any graph? The answer in the language or vision domain is a shared vocabulary. We observe the fact that there also exist shared substructures underlying graph domain, and thereby open a new opportunity of graph foundation model with structural vocabulary. The key innovation is the discovery of a simple yet effective structural vocabulary of trees and cycles, and we explore its inherent connection to Riemannian geometry. Herein, we present a universal pretraining model, RiemannGFM. Concretely, we first construct a novel product bundle to incorporate the diverse geometries of the vocabulary. Then, on this constructed space, we stack Riemannian layers where the structural vocabulary, regardless of specific graph, is learned in Riemannian manifold offering cross-domain transferability. Extensive experiments show the effectiveness of RiemannGFM on a diversity of real graphs.
Spiking Graph Neural Network on Riemannian Manifolds
Oct 23, 2024


Graph neural networks (GNNs) have become the dominant solution for learning on graphs, the typical non-Euclidean structures. Conventional GNNs, constructed with the Artificial Neuron Network (ANN), have achieved impressive performance at the cost of high computation and energy consumption. In parallel, spiking GNNs with brain-like spiking neurons are drawing increasing research attention owing to the energy efficiency. So far, existing spiking GNNs consider graphs in Euclidean space, ignoring the structural geometry, and suffer from the high latency issue due to Back-Propagation-Through-Time (BPTT) with the surrogate gradient. In light of the aforementioned issues, we are devoted to exploring spiking GNN on Riemannian manifolds, and present a Manifold-valued Spiking GNN (MSG). In particular, we design a new spiking neuron on geodesically complete manifolds with the diffeomorphism, so that BPTT regarding the spikes is replaced by the proposed differentiation via manifold. Theoretically, we show that MSG approximates a solver of the manifold ordinary differential equation. Extensive experiments on common graphs show the proposed MSG achieves superior performance to previous spiking GNNs and energy efficiency to conventional GNNs.
LSEnet: Lorentz Structural Entropy Neural Network for Deep Graph Clustering
May 20, 2024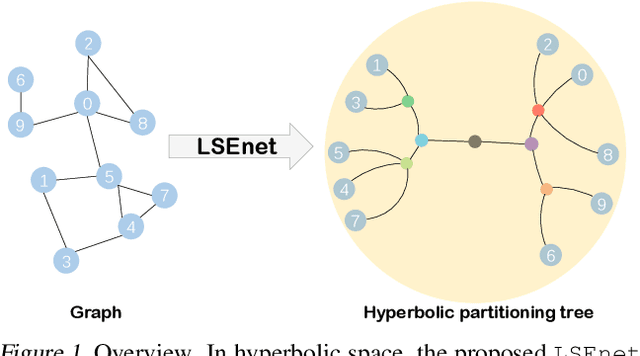
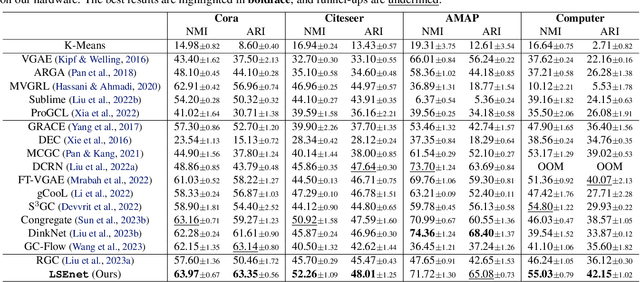
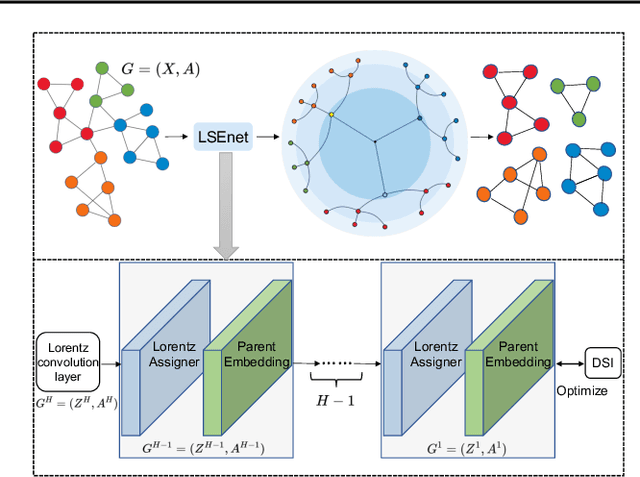
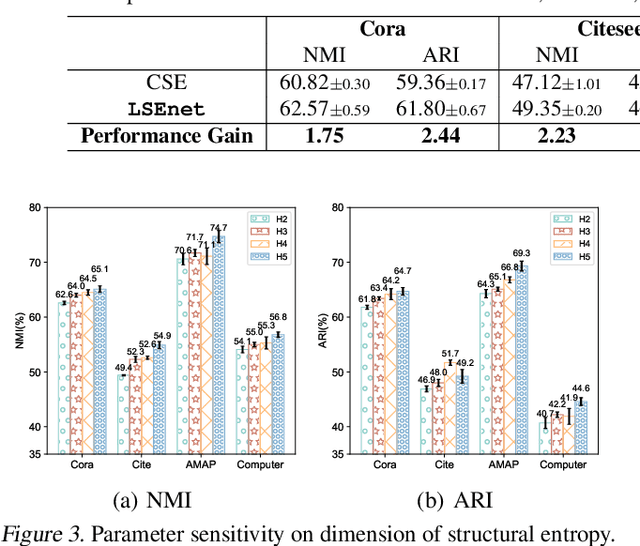
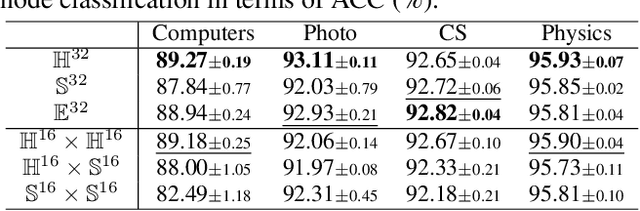
Graph clustering is a fundamental problem in machine learning. Deep learning methods achieve the state-of-the-art results in recent years, but they still cannot work without predefined cluster numbers. Such limitation motivates us to pose a more challenging problem of graph clustering with unknown cluster number. We propose to address this problem from a fresh perspective of graph information theory (i.e., structural information). In the literature, structural information has not yet been introduced to deep clustering, and its classic definition falls short of discrete formulation and modeling node features. In this work, we first formulate a differentiable structural information (DSI) in the continuous realm, accompanied by several theoretical results. By minimizing DSI, we construct the optimal partitioning tree where densely connected nodes in the graph tend to have the same assignment, revealing the cluster structure. DSI is also theoretically presented as a new graph clustering objective, not requiring the predefined cluster number. Furthermore, we design a neural LSEnet in the Lorentz model of hyperbolic space, where we integrate node features to structural information via manifold-valued graph convolution. Extensive empirical results on real graphs show the superiority of our approach.
DeepRicci: Self-supervised Graph Structure-Feature Co-Refinement for Alleviating Over-squashing
Jan 23, 2024Graph Neural Networks (GNNs) have shown great power for learning and mining on graphs, and Graph Structure Learning (GSL) plays an important role in boosting GNNs with a refined graph. In the literature, most GSL solutions either primarily focus on structure refinement with task-specific supervision (i.e., node classification), or overlook the inherent weakness of GNNs themselves (e.g., over-squashing), resulting in suboptimal performance despite sophisticated designs. In light of these limitations, we propose to study self-supervised graph structure-feature co-refinement for effectively alleviating the issue of over-squashing in typical GNNs. In this paper, we take a fundamentally different perspective of the Ricci curvature in Riemannian geometry, in which we encounter the challenges of modeling, utilizing and computing Ricci curvature. To tackle these challenges, we present a self-supervised Riemannian model, DeepRicci. Specifically, we introduce a latent Riemannian space of heterogeneous curvatures to model various Ricci curvatures, and propose a gyrovector feature mapping to utilize Ricci curvature for typical GNNs. Thereafter, we refine node features by geometric contrastive learning among different geometric views, and simultaneously refine graph structure by backward Ricci flow based on a novel formulation of differentiable Ricci curvature. Finally, extensive experiments on public datasets show the superiority of DeepRicci, and the connection between backward Ricci flow and over-squashing. Codes of our work are given in https://github.com/RiemanGraph/.
Motif-aware Riemannian Graph Neural Network with Generative-Contrastive Learning
Jan 02, 2024Graphs are typical non-Euclidean data of complex structures. In recent years, Riemannian graph representation learning has emerged as an exciting alternative to Euclidean ones. However, Riemannian methods are still in an early stage: most of them present a single curvature (radius) regardless of structural complexity, suffer from numerical instability due to the exponential/logarithmic map, and lack the ability to capture motif regularity. In light of the issues above, we propose the problem of \emph{Motif-aware Riemannian Graph Representation Learning}, seeking a numerically stable encoder to capture motif regularity in a diverse-curvature manifold without labels. To this end, we present a novel Motif-aware Riemannian model with Generative-Contrastive learning (MotifRGC), which conducts a minmax game in Riemannian manifold in a self-supervised manner. First, we propose a new type of Riemannian GCN (D-GCN), in which we construct a diverse-curvature manifold by a product layer with the diversified factor, and replace the exponential/logarithmic map by a stable kernel layer. Second, we introduce a motif-aware Riemannian generative-contrastive learning to capture motif regularity in the constructed manifold and learn motif-aware node representation without external labels. Empirical results show the superiority of MofitRGC.
Bayesian Robust Tensor Ring Model for Incomplete Multiway Data
Feb 27, 2022
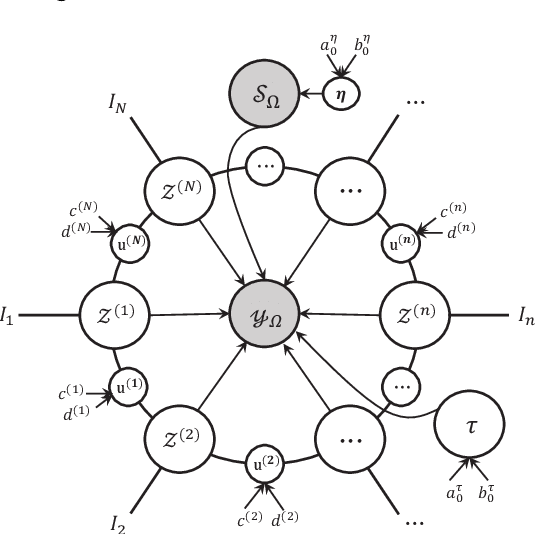
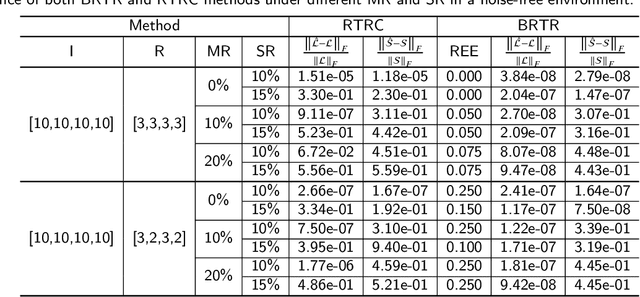
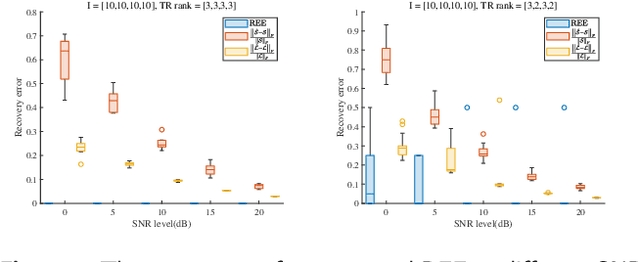
Low-rank tensor completion aims to recover missing entries from the observed data. However, the observed data may be disturbed by noise and outliers. Therefore, robust tensor completion (RTC) is proposed to solve this problem. The recently proposed tensor ring (TR) structure is applied to RTC due to its superior abilities in dealing with high-dimensional data with predesigned TR rank. To avoid manual rank selection and achieve a balance between low-rank component and sparse component, in this paper, we propose a Bayesian robust tensor ring (BRTR) decomposition method for RTC problem. Furthermore, we develop a variational Bayesian (VB) algorithm to infer the probability distribution of posteriors. During the learning process, the frontal slices of previous tensor and horizontal slices of latter tensor shared with the same TR rank with zero components are pruned, resulting in automatic rank determination. Compared with existing methods, BRTR can automatically learn TR rank without manual fine-tuning of parameters. Extensive experiments indicate that BRTR has better recovery performance and ability to remove noise than other state-of-the-art methods.
Efficient Tensor Robust PCA under Hybrid Model of Tucker and Tensor Train
Dec 20, 2021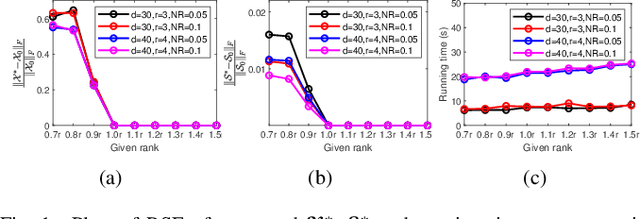

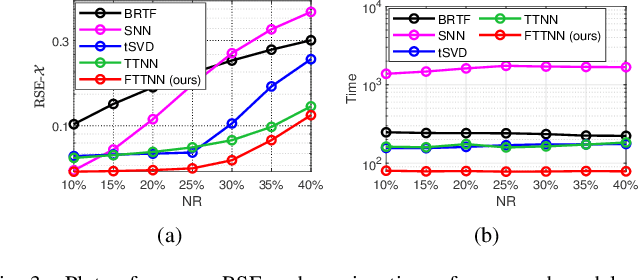
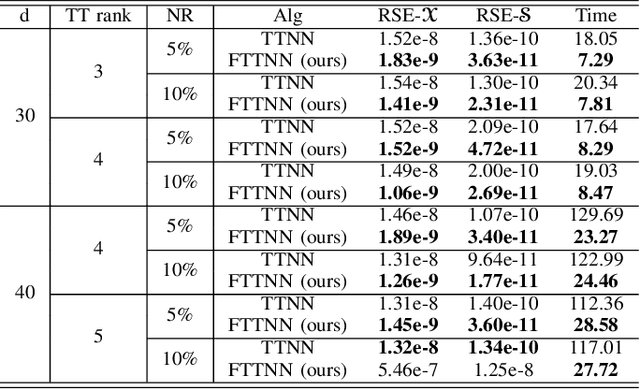
Tensor robust principal component analysis (TRPCA) is a fundamental model in machine learning and computer vision. Recently, tensor train (TT) decomposition has been verified effective to capture the global low-rank correlation for tensor recovery tasks. However, due to the large-scale tensor data in real-world applications, previous TRPCA models often suffer from high computational complexity. In this letter, we propose an efficient TRPCA under hybrid model of Tucker and TT. Specifically, in theory we reveal that TT nuclear norm (TTNN) of the original big tensor can be equivalently converted to that of a much smaller tensor via a Tucker compression format, thereby significantly reducing the computational cost of singular value decomposition (SVD). Numerical experiments on both synthetic and real-world tensor data verify the superiority of the proposed model.