 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDI: An adversarial robustness evaluation metric for deep neural networks based on sample clustering features
Apr 16, 2025Deep neural networks (DNNs) are highly susceptible to adversarial samples, raising concerns about their reliability in safety-critical tasks. Currently, methods of evaluating adversarial robustness are primarily categorized into attack-based and certified robustness evaluation approaches. The former not only relies on specific attack algorithms but also is highly time-consuming, while the latter due to its analytical nature, is typically difficult to implement for large and complex models. A few studies evaluate model robustness based on the model's decision boundary, but they suffer from low evaluation accuracy. To address the aforementioned issues, we propose a novel adversarial robustness evaluation metric, Robustness Difference Index (RDI), which is based on sample clustering features. RDI draws inspiration from clustering evaluation by analyzing the intra-class and inter-class distances of feature vectors separated by the decision boundary to quantify model robustness. It is attack-independent and has high computational efficiency. Experiments show that, RDI demonstrates a stronger correlation with the gold-standard adversarial robustness metric of attack success rate (ASR). The average computation time of RDI is only 1/30 of the evaluation method based on the PGD attack. Our open-source code is available at: https://anonymous.4open.science/r/RDI-B1DA.
CubeRobot: Grounding Language in Rubik's Cube Manipulation via Vision-Language Model
Mar 25, 2025



Proving Rubik's Cube theorems at the high level represents a notable milestone in human-level spatial imagination and logic thinking and reasoning. Traditional Rubik's Cube robots, relying on complex vision systems and fixed algorithms, often struggle to adapt to complex and dynamic scenarios. To overcome this limitation, we introduce CubeRobot, a novel vision-language model (VLM) tailored for solving 3x3 Rubik's Cubes, empowering embodied agents with multimodal understanding and execution capabilities. We used the CubeCoT image dataset, which contains multiple-level tasks (43 subtasks in total) that humans are unable to handle, encompassing various cube states. We incorporate a dual-loop VisionCoT architecture and Memory Stream, a paradigm for extracting task-related features from VLM-generated planning queries, thus enabling CubeRobot to independent planning, decision-making, reflection and separate management of high- and low-level Rubik's Cube tasks. Furthermore, in low-level Rubik's Cube restoration tasks, CubeRobot achieved a high accuracy rate of 100%, similar to 100% in medium-level tasks, and achieved an accuracy rate of 80% in high-level tasks.
CLEAR: Cluster-based Prompt Learning on Heterogeneous Graphs
Feb 13, 2025



Prompt learning has attracted increasing attention in the graph domain as a means to bridge the gap between pretext and downstream tasks. Existing studies on heterogeneous graph prompting typically use feature prompts to modify node features for specific downstream tasks, which do not concern the structure of heterogeneous graphs. Such a design also overlooks information from the meta-paths, which are core to learning the high-order semantics of the heterogeneous graphs. To address these issues, we propose CLEAR, a Cluster-based prompt LEARNING model on heterogeneous graphs. We present cluster prompts that reformulate downstream tasks as heterogeneous graph reconstruction. In this way, we align the pretext and downstream tasks to share the same training objective. Additionally, our cluster prompts are also injected into the meta-paths such that the prompt learning process incorporates high-order semantic information entailed by the meta-paths. Extensive experiments on downstream tasks confirm the superiority of CLEAR. It consistently outperforms state-of-the-art models, achieving up to 5% improvement on the F1 metric for node classification.
Optimizing Transformer based on high-performance optimizer for predicting employment sentiment in American social media content
Oct 09, 2024



This article improves the Transformer model based on swarm intelligence optimization algorithm, aiming to predict the emotions of employment related text content on American social media. Through text preprocessing, feature extraction, and vectorization, the text data was successfully converted into numerical data and imported into the model for training. The experimental results show that during the training process, the accuracy of the model gradually increased from 49.27% to 82.83%, while the loss value decreased from 0.67 to 0.35, indicating a significant improvement in the performance of the model on the training set. According to the confusion matrix analysis of the training set, the accuracy of the training set is 86.15%. The confusion matrix of the test set also showed good performance, with an accuracy of 82.91%. The accuracy difference between the training set and the test set is only 3.24%, indicating that the model has strong generalization ability. In addition, the evaluation of polygon results shows that the model performs well in classification accuracy, sensitivity, specificity, and area under the curve (AUC), with a Kappa coefficient of 0.66 and an F-measure of 0.80, further verifying the effectiveness of the model in social media sentiment analysis. The improved model proposed in this article not only improves the accuracy of sentiment recognition in employment related texts on social media, but also has important practical significance. This social media based data analysis method can not only capture social dynamics in a timely manner, but also promote decision-makers to pay attention to public concerns and provide data support for improving employment conditions.
Improved Unet model for brain tumor image segmentation based on ASPP-coordinate attention mechanism
Sep 13, 2024



In this paper, we propose an improved Unet model for brain tumor image segmentation, which combines coordinate attention mechanism and ASPP module to improve the segmentation effect. After the data set is divided, we do the necessary preprocessing to the image and use the improved model to experiment. First, we trained and validated the traditional Unet model. By analyzing the loss curve of the training set and the validation set, we can see that the loss value continues to decline at the first epoch and becomes stable at the eighth epoch. This process shows that the model constantly optimizes its parameters to improve performance. At the same time, the change in the miou (mean Intersection over Union) index shows that the miou value exceeded 0.6 at the 15th epoch, remained above 0.6 thereafter, and reached above 0.7 at the 46th epoch. These results indicate that the basic Unet model is effective in brain tumor image segmentation. Next, we introduce an improved Unet algorithm based on coordinate attention mechanism and ASPP module for experiments. By observing the loss change curves of the training set and the verification set, it is found that the loss value reaches the lowest point at the sixth epoch and then remains relatively stable. At the same time, the miou indicator has stabilized above 0.7 since the 20th epoch and has reached a maximum of 0.76. These results show that the new mechanism introduced significantly improves the segmentation ability of the model. Finally, we apply the trained traditional Unet model and the improved Unet model based on the coordinate attention mechanism and ASPP module to the test set for brain tumor image segmentation prediction. Compared to the traditional Unet, the enhanced model offers superior segmentation and edge accuracy, providing a more reliable method for medical image analysis with the coordinate attention mechanism and ASPP module.
A Text-to-Game Engine for UGC-Based Role-Playing Games
Jul 11, 2024



The shift from professionally generated content (PGC) to user-generated content (UGC) has revolutionized various media formats, from text to video. With the rapid advancements in generative AI, a similar shift is set to transform the game industry, particularly in the realm of role-playing games (RPGs). This paper introduces a new framework for a text-to-game engine that utilizes foundation models to convert simple textual inputs into complex, interactive RPG experiences. The engine dynamically renders the game story in a multi-modal format and adjusts the game character, environment, and mechanics in real-time in response to player actions. Using this framework, we developed the "Zagii" game engine, which has successfully supported hundreds of RPG games across a diverse range of genres and facilitated tens of thousands of online user gameplay instances. This validates the effectiveness of our frame-work. Our work showcases the potential for a more open and democratized gaming paradigm, highlighting the transformative impact of generative AI on the game life cycle.
ADBA:Approximation Decision Boundary Approach for Black-Box Adversarial Attacks
Jun 07, 2024



Many machine learning models are susceptible to adversarial attacks, with decision-based black-box attacks representing the most critical threat in real-world applications. These attacks are extremely stealthy, generating adversarial examples using hard labels obtained from the target machine learning model. This is typically realized by optimizing perturbation directions, guided by decision boundaries identified through query-intensive exact search, significantly limiting the attack success rate. This paper introduces a novel approach using the Approximation Decision Boundary (ADB) to efficiently and accurately compare perturbation directions without precisely determining decision boundaries. The effectiveness of our ADB approach (ADBA) hinges on promptly identifying suitable ADB, ensuring reliable differentiation of all perturbation directions. For this purpose, we analyze the probability distribution of decision boundaries, confirming that using the distribution's median value as ADB can effectively distinguish different perturbation directions, giving rise to the development of the ADBA-md algorithm. ADBA-md only requires four queries on average to differentiate any pair of perturbation directions, which is highly query-efficient. Extensive experiments on six well-known image classifiers clearly demonstrate the superiority of ADBA and ADBA-md over multiple state-of-the-art black-box attacks.
Motif-aware Riemannian Graph Neural Network with Generative-Contrastive Learning
Jan 02, 2024Graphs are typical non-Euclidean data of complex structures. In recent years, Riemannian graph representation learning has emerged as an exciting alternative to Euclidean ones. However, Riemannian methods are still in an early stage: most of them present a single curvature (radius) regardless of structural complexity, suffer from numerical instability due to the exponential/logarithmic map, and lack the ability to capture motif regularity. In light of the issues above, we propose the problem of \emph{Motif-aware Riemannian Graph Representation Learning}, seeking a numerically stable encoder to capture motif regularity in a diverse-curvature manifold without labels. To this end, we present a novel Motif-aware Riemannian model with Generative-Contrastive learning (MotifRGC), which conducts a minmax game in Riemannian manifold in a self-supervised manner. First, we propose a new type of Riemannian GCN (D-GCN), in which we construct a diverse-curvature manifold by a product layer with the diversified factor, and replace the exponential/logarithmic map by a stable kernel layer. Second, we introduce a motif-aware Riemannian generative-contrastive learning to capture motif regularity in the constructed manifold and learn motif-aware node representation without external labels. Empirical results show the superiority of MofitRGC.
Contrastive Sequential Interaction Network Learning on Co-Evolving Riemannian Spaces
Jan 02, 2024The sequential interaction network usually find itself in a variety of applications, e.g., recommender system. Herein, inferring future interaction is of fundamental importance, and previous efforts are mainly focused on the dynamics in the classic zero-curvature Euclidean space. Despite the promising results achieved by previous methods, a range of significant issues still largely remains open: On the bipartite nature, is it appropriate to place user and item nodes in one identical space regardless of their inherent difference? On the network dynamics, instead of a fixed curvature space, will the representation spaces evolve when new interactions arrive continuously? On the learning paradigm, can we get rid of the label information costly to acquire? To address the aforementioned issues, we propose a novel Contrastive model for Sequential Interaction Network learning on Co-Evolving RiEmannian spaces, CSINCERE. To the best of our knowledge, we are the first to introduce a couple of co-evolving representation spaces, rather than a single or static space, and propose a co-contrastive learning for the sequential interaction network. In CSINCERE, we formulate a Cross-Space Aggregation for message-passing across representation spaces of different Riemannian geometries, and design a Neural Curvature Estimator based on Ricci curvatures for modeling the space evolvement over time. Thereafter, we present a Reweighed Co-Contrast between the temporal views of the sequential network, so that the couple of Riemannian spaces interact with each other for the interaction prediction without labels. Empirical results on 5 public datasets show the superiority of CSINCERE over the state-of-the-art methods.
FAIR: Frequency-aware Image Restoration for Industrial Visual Anomaly Detection
Sep 13, 2023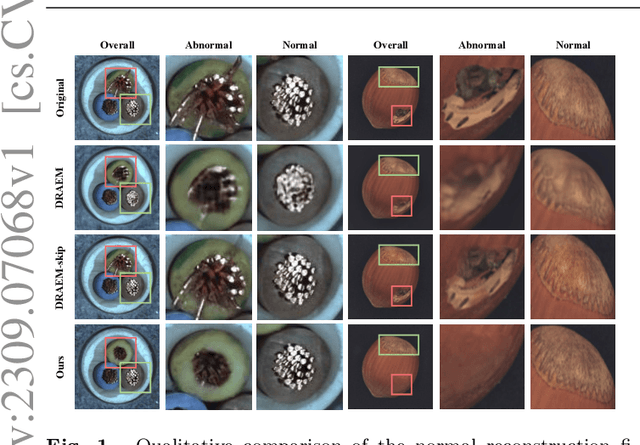
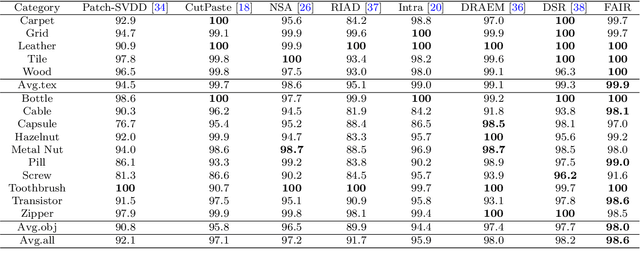
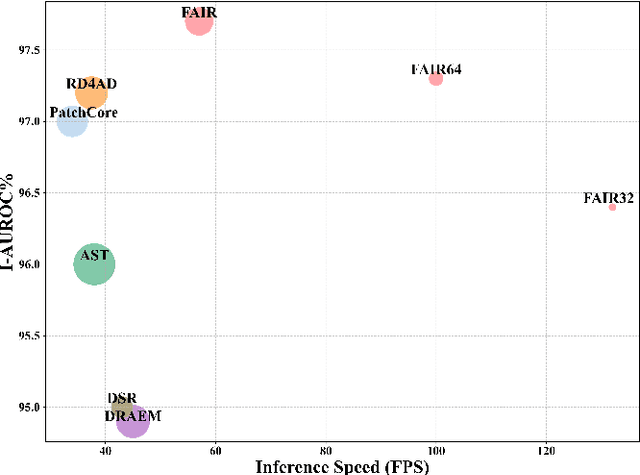
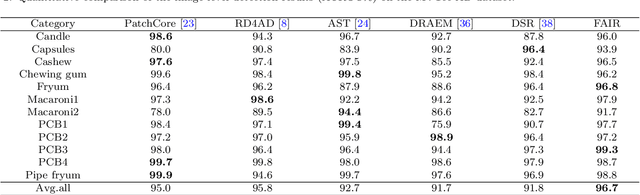
Image reconstruction-based anomaly detection models are widely explored in industrial visual inspection. However, existing models usually suffer from the trade-off between normal reconstruction fidelity and abnormal reconstruction distinguishability, which damages the performance. In this paper, we find that the above trade-off can be better mitigated by leveraging the distinct frequency biases between normal and abnormal reconstruction errors. To this end, we propose Frequency-aware Image Restoration (FAIR), a novel self-supervised image restoration task that restores images from their high-frequency components. It enables precise reconstruction of normal patterns while mitigating unfavorable generalization to anomalies. Using only a simple vanilla UNet, FAIR achieves state-of-the-art performance with higher efficiency on various defect detection datasets. Code: https://github.com/liutongkun/FAIR.