 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Text-to-Game Engine for UGC-Based Role-Playing Games
Jul 11, 2024



The shift from professionally generated content (PGC) to user-generated content (UGC) has revolutionized various media formats, from text to video. With the rapid advancements in generative AI, a similar shift is set to transform the game industry, particularly in the realm of role-playing games (RPGs). This paper introduces a new framework for a text-to-game engine that utilizes foundation models to convert simple textual inputs into complex, interactive RPG experiences. The engine dynamically renders the game story in a multi-modal format and adjusts the game character, environment, and mechanics in real-time in response to player actions. Using this framework, we developed the "Zagii" game engine, which has successfully supported hundreds of RPG games across a diverse range of genres and facilitated tens of thousands of online user gameplay instances. This validates the effectiveness of our frame-work. Our work showcases the potential for a more open and democratized gaming paradigm, highlighting the transformative impact of generative AI on the game life cycle.
Residual Objectness for Imbalance Reduction
Aug 24, 2019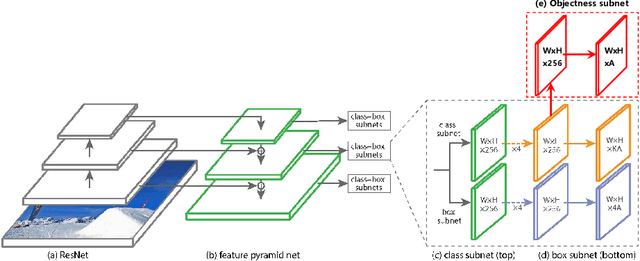
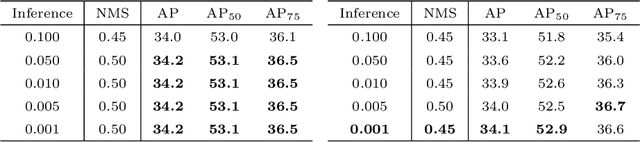
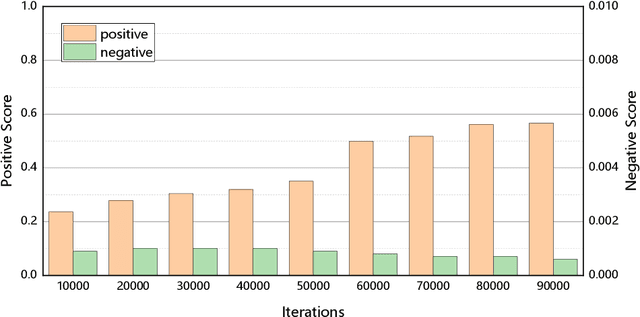
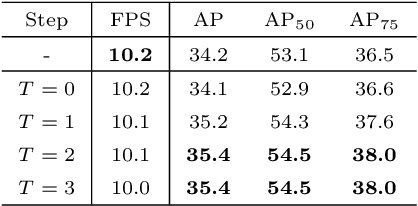
For a long time, object detectors have suffered from extreme imbalance between foregrounds and backgrounds. While several sampling/reweighting schemes have been explored to alleviate the imbalance, they are usually heuristic and demand laborious hyper-parameters tuning, which is hard to achieve the optimality. In this paper, we first reveal that such the imbalance could be addressed in a learning-based manner. Guided by this illuminating observation, we propose a novel Residual Objectness (ResObj) mechanism that addresses the imbalance by end-to-end optimization, while no further hand-crafted sampling/reweighting is required. Specifically, by applying multiple cascaded objectness-related modules with residual connections, we formulate an elegant consecutive refinement procedure for distinguishing the foregrounds from backgrounds, thereby progressively addressing the imbalance. Extensive experiments present the effectiveness of our method, as well as its compatibility and adaptivity for both region-based and one-stage detectors, namely, the RetinaNet-ResObj, YOLOv3-ResObj and FasterRCNN-ResObj achieve relative 3.6%, 3.9%, 3.2% Average Precision (AP) improvements compared with their vanilla models on COCO, respectively.
Flexible End-to-End Dialogue System for Knowledge Grounded Conversation
Sep 13, 2017

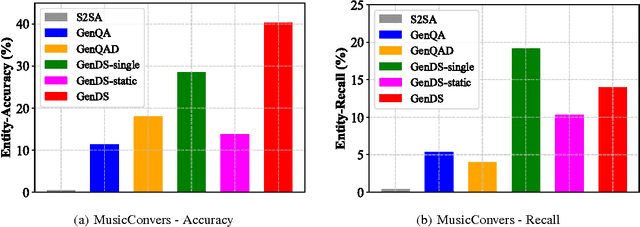

In knowledge grounded conversation, domain knowledge plays an important role in a special domain such as Music. The response of knowledge grounded conversation might contain multiple answer entities or no entity at all. Although existing generative question answering (QA) systems can be applied to knowledge grounded conversation, they either have at most one entity in a response or cannot deal with out-of-vocabulary entities. We propose a fully data-driven generative dialogue system GenDS that is capable of generating responses based on input message and related knowledge base (KB). To generate arbitrary number of answer entities even when these entities never appear in the training set, we design a dynamic knowledge enquirer which selects different answer entities at different positions in a single response, according to different local context. It does not rely on the representations of entities, enabling our model deal with out-of-vocabulary entities. We collect a human-human conversation data (ConversMusic) with knowledge annotations. The proposed method is evaluated on CoversMusic and a public question answering dataset. Our proposed GenDS system outperforms baseline methods significantly in terms of the BLEU, entity accuracy, entity recall and human evaluation. Moreover,the experiments also demonstrate that GenDS works better even on small datasets.