 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do Multi-Agent LLM Systems Fail?
Mar 17, 2025Despite growing enthusiasm for Multi-Agent Systems (MAS), where multiple LLM agents collaborate to accomplish tasks, their performance gains across popular benchmarks remain minimal compared to single-agent frameworks. This gap highlights the need to analyze the challenges hindering MAS effectiveness. In this paper, we present the first comprehensive study of MAS challenges. We analyze five popular MAS frameworks across over 150 tasks, involving six expert human annotators. We identify 14 unique failure modes and propose a comprehensive taxonomy applicable to various MAS frameworks. This taxonomy emerges iteratively from agreements among three expert annotators per study, achieving a Cohen's Kappa score of 0.88. These fine-grained failure modes are organized into 3 categories, (i) specification and system design failures, (ii) inter-agent misalignment, and (iii) task verification and termination. To support scalable evaluation, we integrate MASFT with LLM-as-a-Judge. We also explore if identified failures could be easily prevented by proposing two interventions: improved specification of agent roles and enhanced orchestration strategies. Our findings reveal that identified failures require more complex solutions, highlighting a clear roadmap for future research. We open-source our dataset and LLM annotator.
Dynamic-Attention-based EEG State Transition Modeling for Emotion Recognition
Nov 07, 2024



Electroencephalogram (EEG)-based emotion decoding can objectively quantify people's emotional state and has broad application prospects in human-computer interaction and early detection of emotional disorders. Recently emerging deep learning architectures have significantly improved the performance of EEG emotion decoding. However, existing methods still fall short of fully capturing the complex spatiotemporal dynamics of neural signals, which are crucial for representing emotion processing. This study proposes a Dynamic-Attention-based EEG State Transition (DAEST) modeling method to characterize EEG spatiotemporal dynamics. The model extracts spatiotemporal components of EEG that represent multiple parallel neural processes and estimates dynamic attention weights on these components to capture transitions in brain states. The model is optimized within a contrastive learning framework for cross-subject emotion recognition. The proposed method achieved state-of-the-art performance on three publicly available datasets: FACED, SEED, and SEED-V. It achieved 75.4% accuracy in the binary classification of positive and negative emotions and 59.3% in nine-class discrete emotion classification on the FACED dataset, 88.1% in the three-class classification of positive, negative, and neutral emotions on the SEED dataset, and 73.6% in five-class discrete emotion classification on the SEED-V dataset. The learned EEG spatiotemporal patterns and dynamic transition properties offer valuable insights into neural dynamics underlying emotion processing.
HEnRY: A Multi-Agent System Framework for Multi-Domain Contexts
Oct 16, 2024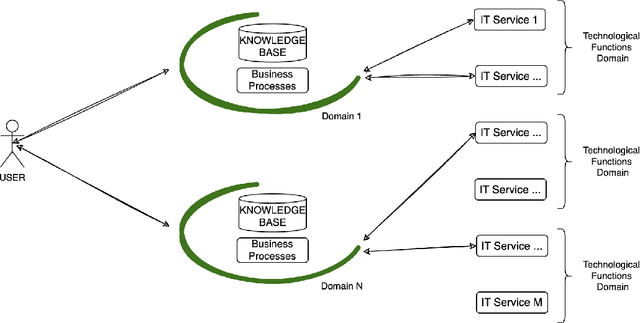
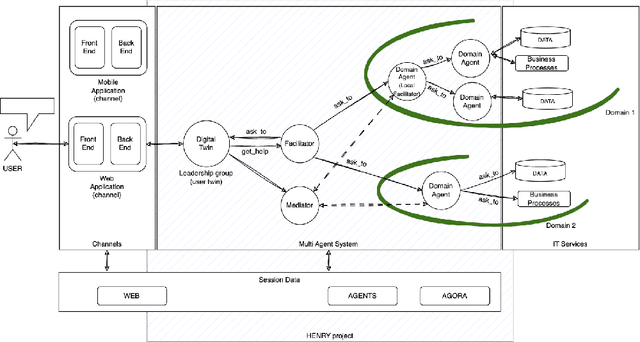
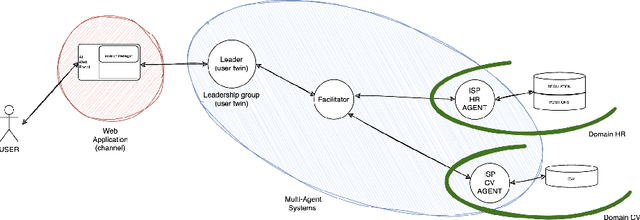
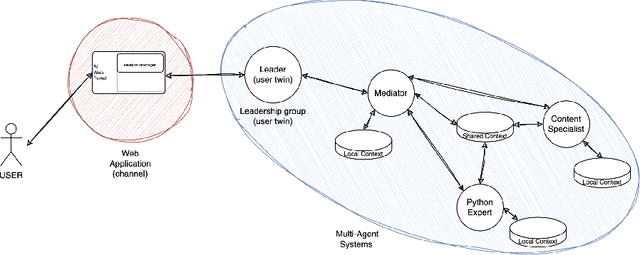
This project, named HEnRY, aims to introduce a Multi-Agent System (MAS) into Intesa Sanpaolo. The name HEnRY summarizes the project's core principles: the Hierarchical organization of agents in a layered structure for efficient resource management; Efficient optimization of resources and operations to enhance overall performance; Reactive ability of agents to quickly respond to environmental stimuli; and Yielding adaptability and flexibility of agents to handle unexpected situations. The discussion covers two distinct research paths: the first focuses on the system architecture, and the second on the collaboration between agents. This work is not limited to the specific structure of the Intesa Sanpaolo context; instead, it leverages existing research in MAS to introduce a new solution. Since Intesa Sanpaolo is organized according to a model that aligns with international corporate governance best practices, this approach could also be relevant to similar scenarios.
A Text-to-Game Engine for UGC-Based Role-Playing Games
Jul 11, 2024



The shift from professionally generated content (PGC) to user-generated content (UGC) has revolutionized various media formats, from text to video. With the rapid advancements in generative AI, a similar shift is set to transform the game industry, particularly in the realm of role-playing games (RPGs). This paper introduces a new framework for a text-to-game engine that utilizes foundation models to convert simple textual inputs into complex, interactive RPG experiences. The engine dynamically renders the game story in a multi-modal format and adjusts the game character, environment, and mechanics in real-time in response to player actions. Using this framework, we developed the "Zagii" game engine, which has successfully supported hundreds of RPG games across a diverse range of genres and facilitated tens of thousands of online user gameplay instances. This validates the effectiveness of our frame-work. Our work showcases the potential for a more open and democratized gaming paradigm, highlighting the transformative impact of generative AI on the game life cycle.
Disambiguation of Company names via Deep Recurrent Networks
Mar 07, 2023



Name Entity Disambiguation is the Natural Language Processing task of identifying textual records corresponding to the same Named Entity, i.e. real-world entities represented as a list of attributes (names, places, organisations, etc.). In this work, we face the task of disambiguating companies on the basis of their written names. We propose a Siamese LSTM Network approach to extract -- via supervised learning -- an embedding of company name strings in a (relatively) low dimensional vector space and use this representation to identify pairs of company names that actually represent the same company (i.e. the same Entity). Given that the manual labelling of string pairs is a rather onerous task, we analyse how an Active Learning approach to prioritise the samples to be labelled leads to a more efficient overall learning pipeline. With empirical investigations, we show that our proposed Siamese Network outperforms several benchmark approaches based on standard string matching algorithms when enough labelled data are available. Moreover, we show that Active Learning prioritisation is indeed helpful when labelling resources are limited, and let the learning models reach the out-of-sample performance saturation with less labelled data with respect to standard (random) data labelling approaches.