 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisambiguation of Company names via Deep Recurrent Networks
Mar 07, 2023



Name Entity Disambiguation is the Natural Language Processing task of identifying textual records corresponding to the same Named Entity, i.e. real-world entities represented as a list of attributes (names, places, organisations, etc.). In this work, we face the task of disambiguating companies on the basis of their written names. We propose a Siamese LSTM Network approach to extract -- via supervised learning -- an embedding of company name strings in a (relatively) low dimensional vector space and use this representation to identify pairs of company names that actually represent the same company (i.e. the same Entity). Given that the manual labelling of string pairs is a rather onerous task, we analyse how an Active Learning approach to prioritise the samples to be labelled leads to a more efficient overall learning pipeline. With empirical investigations, we show that our proposed Siamese Network outperforms several benchmark approaches based on standard string matching algorithms when enough labelled data are available. Moreover, we show that Active Learning prioritisation is indeed helpful when labelling resources are limited, and let the learning models reach the out-of-sample performance saturation with less labelled data with respect to standard (random) data labelling approaches.
Investigating Bias with a Synthetic Data Generator: Empirical Evidence and Philosophical Interpretation
Sep 13, 2022
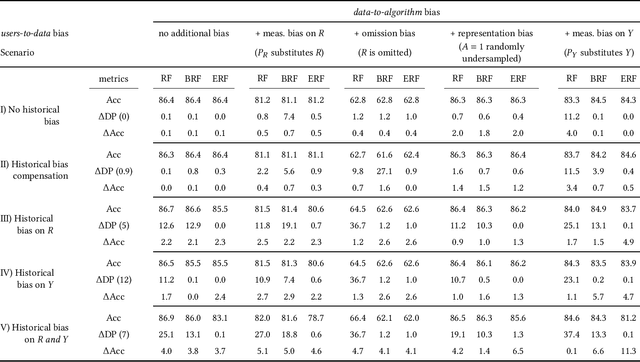
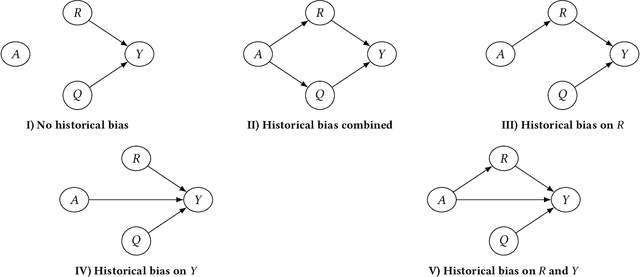
Machine learning applications are becoming increasingly pervasive in our society. Since these decision-making systems rely on data-driven learning, risk is that they will systematically spread the bias embedded in data. In this paper, we propose to analyze biases by introducing a framework for generating synthetic data with specific types of bias and their combinations. We delve into the nature of these biases discussing their relationship to moral and justice frameworks. Finally, we exploit our proposed synthetic data generator to perform experiments on different scenarios, with various bias combinations. We thus analyze the impact of biases on performance and fairness metrics both in non-mitigated and mitigated machine learning models.