 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Responsible AI in Banking: Addressing Bias for Fair Decision-Making
Jan 13, 2024In an era characterized by the pervasive integration of artificial intelligence into decision-making processes across diverse industries, the demand for trust has never been more pronounced. This thesis embarks on a comprehensive exploration of bias and fairness, with a particular emphasis on their ramifications within the banking sector, where AI-driven decisions bear substantial societal consequences. In this context, the seamless integration of fairness, explainability, and human oversight is of utmost importance, culminating in the establishment of what is commonly referred to as "Responsible AI". This emphasizes the critical nature of addressing biases within the development of a corporate culture that aligns seamlessly with both AI regulations and universal human rights standards, particularly in the realm of automated decision-making systems. Nowadays, embedding ethical principles into the development, training, and deployment of AI models is crucial for compliance with forthcoming European regulations and for promoting societal good. This thesis is structured around three fundamental pillars: understanding bias, mitigating bias, and accounting for bias. These contributions are validated through their practical application in real-world scenarios, in collaboration with Intesa Sanpaolo. This collaborative effort not only contributes to our understanding of fairness but also provides practical tools for the responsible implementation of AI-based decision-making systems. In line with open-source principles, we have released Bias On Demand and FairView as accessible Python packages, further promoting progress in the field of AI fairness.
Evaluative Item-Contrastive Explanations in Rankings
Dec 14, 2023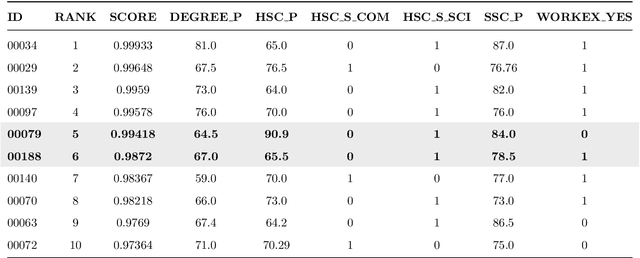
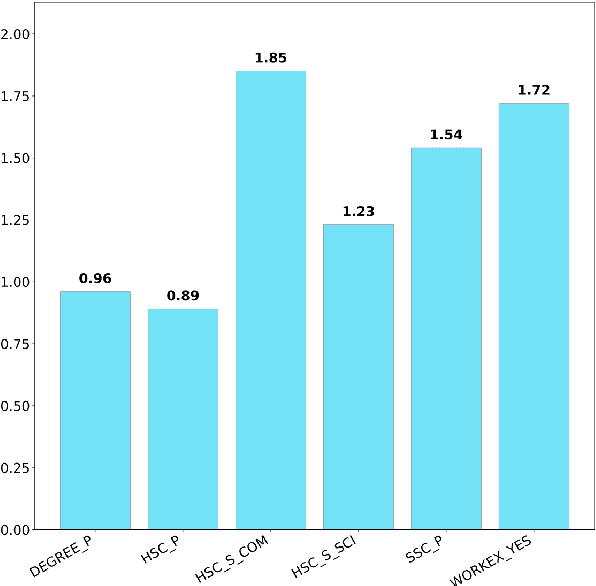
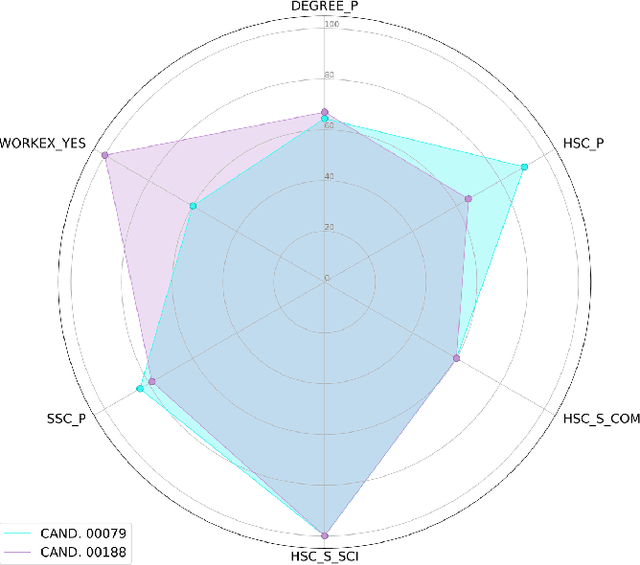
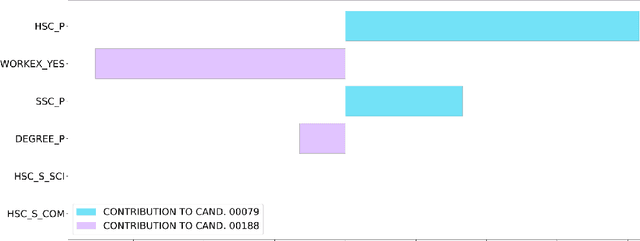
The remarkable success of Artificial Intelligence in advancing automated decision-making is evident both in academia and industry. Within the plethora of applications, ranking systems hold significant importance in various domains. This paper advocates for the application of a specific form of Explainable AI -- namely, contrastive explanations -- as particularly well-suited for addressing ranking problems. This approach is especially potent when combined with an Evaluative AI methodology, which conscientiously evaluates both positive and negative aspects influencing a potential ranking. Therefore, the present work introduces Evaluative Item-Contrastive Explanations tailored for ranking systems and illustrates its application and characteristics through an experiment conducted on publicly available data.
Fair Enough? A map of the current limitations of the requirements to have "fair'' algorithms
Nov 21, 2023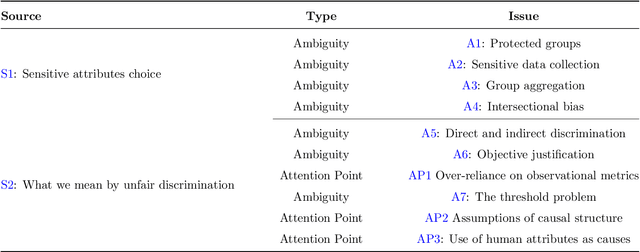
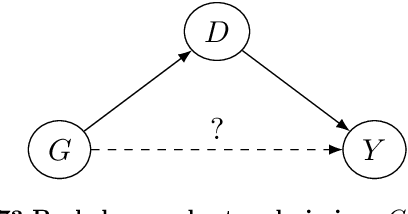

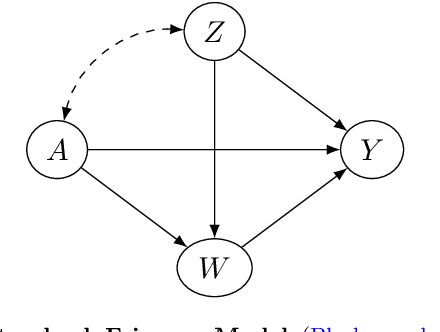
In the recent years, the raise in the usage and efficiency of Artificial Intelligence and, more in general, of Automated Decision-Making systems has brought with it an increasing and welcome awareness of the risks associated with such systems. One of such risks is that of perpetuating or even amplifying bias and unjust disparities present in the data from which many of these systems learn to adjust and optimise their decisions. This awareness has on one side encouraged several scientific communities to come up with more and more appropriate ways and methods to assess, quantify, and possibly mitigate such biases and disparities. On the other hand, it has prompted more and more layers of society, including policy makers, to call for ``fair'' algorithms. We believe that while a lot of excellent and multidisciplinary research is currently being conducted, what is still fundamentally missing is the awareness that having ``fair'' algorithms is per s\'e a nearly meaningless requirement, that needs to be complemented with a lot of additional societal choices to become actionable. Namely, there is a hiatus between what the society is demanding from Automated Decision-Making systems, and what this demand actually means in real-world scenarios. In this work, we outline the key features of such a hiatus, and pinpoint a list of fundamental ambiguities and attention points that we as a society must address in order to give a concrete meaning to the increasing demand of fairness in Automated Decision-Making systems.
Investigating Bias with a Synthetic Data Generator: Empirical Evidence and Philosophical Interpretation
Sep 13, 2022
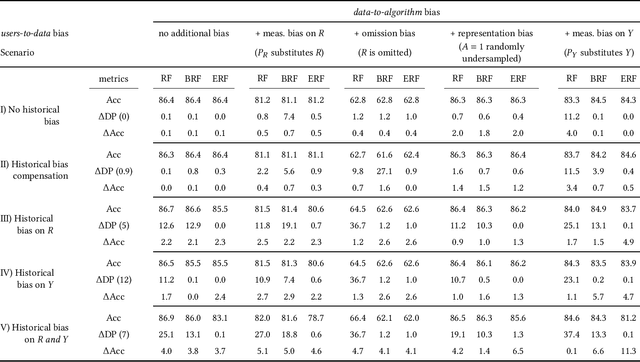
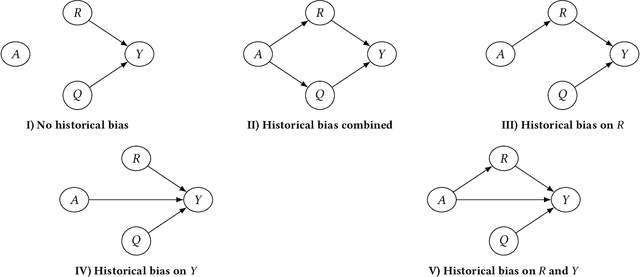
Machine learning applications are becoming increasingly pervasive in our society. Since these decision-making systems rely on data-driven learning, risk is that they will systematically spread the bias embedded in data. In this paper, we propose to analyze biases by introducing a framework for generating synthetic data with specific types of bias and their combinations. We delve into the nature of these biases discussing their relationship to moral and justice frameworks. Finally, we exploit our proposed synthetic data generator to perform experiments on different scenarios, with various bias combinations. We thus analyze the impact of biases on performance and fairness metrics both in non-mitigated and mitigated machine learning models.
Counterfactual Explanations as Interventions in Latent Space
Jun 14, 2021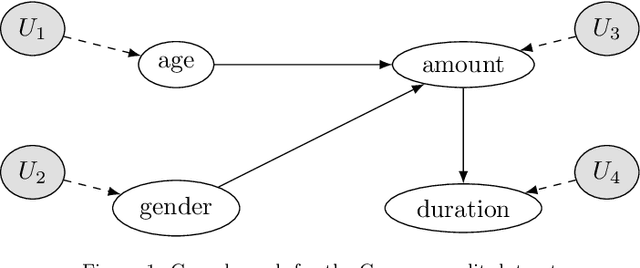
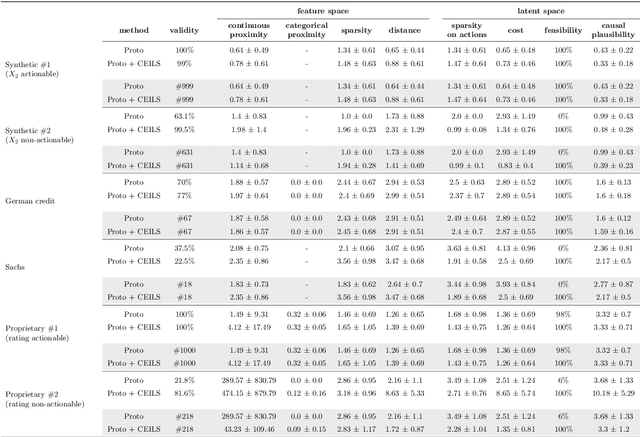
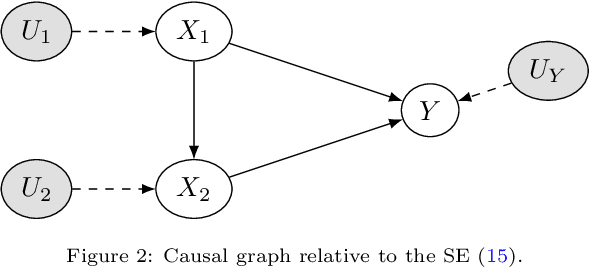
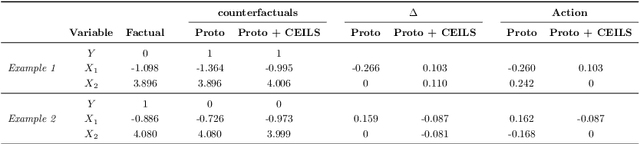
Explainable Artificial Intelligence (XAI) is a set of techniques that allows the understanding of both technical and non-technical aspects of Artificial Intelligence (AI) systems. XAI is crucial to help satisfying the increasingly important demand of \emph{trustworthy} Artificial Intelligence, characterized by fundamental characteristics such as respect of human autonomy, prevention of harm, transparency, accountability, etc. Within XAI techniques, counterfactual explanations aim to provide to end users a set of features (and their corresponding values) that need to be changed in order to achieve a desired outcome. Current approaches rarely take into account the feasibility of actions needed to achieve the proposed explanations, and in particular they fall short of considering the causal impact of such actions. In this paper, we present Counterfactual Explanations as Interventions in Latent Space (CEILS), a methodology to generate counterfactual explanations capturing by design the underlying causal relations from the data, and at the same time to provide feasible recommendations to reach the proposed profile. Moreover, our methodology has the advantage that it can be set on top of existing counterfactuals generator algorithms, thus minimising the complexity of imposing additional causal constrains. We demonstrate the effectiveness of our approach with a set of different experiments using synthetic and real datasets (including a proprietary dataset of the financial domain).
The zoo of Fairness metrics in Machine Learning
Jun 11, 2021
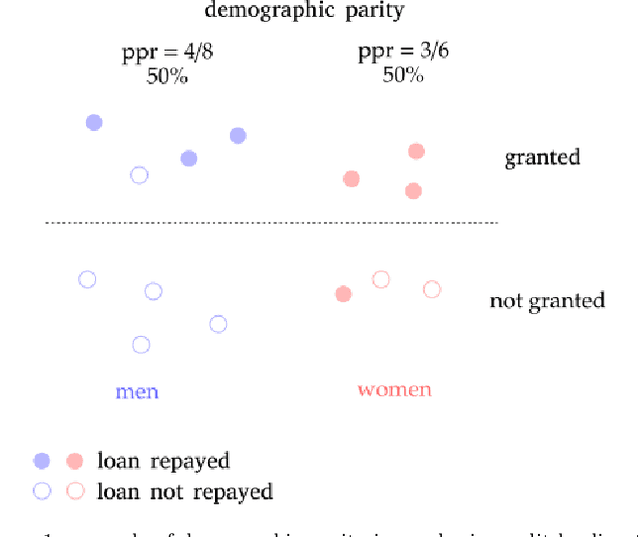
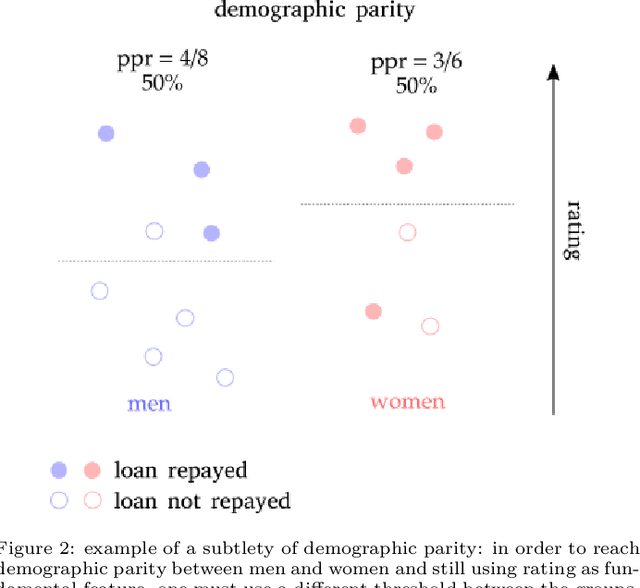
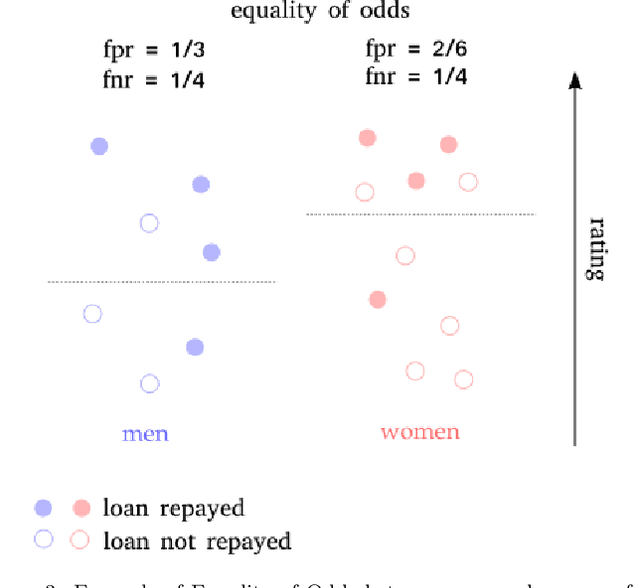
In recent years, the problem of addressing fairness in Machine Learning (ML) and automatic decision-making has attracted a lot of attention in the scientific communities dealing with Artificial Intelligence. A plethora of different definitions of fairness in ML have been proposed, that consider different notions of what is a "fair decision" in situations impacting individuals in the population. The precise differences, implications and "orthogonality" between these notions have not yet been fully analyzed in the literature. In this work, we try to make some order out of this zoo of definitions.
BeFair: Addressing Fairness in the Banking Sector
Feb 04, 2021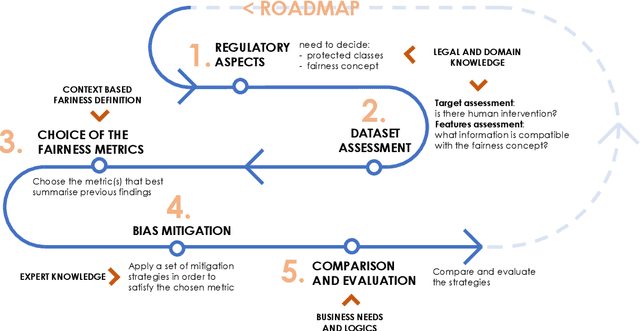
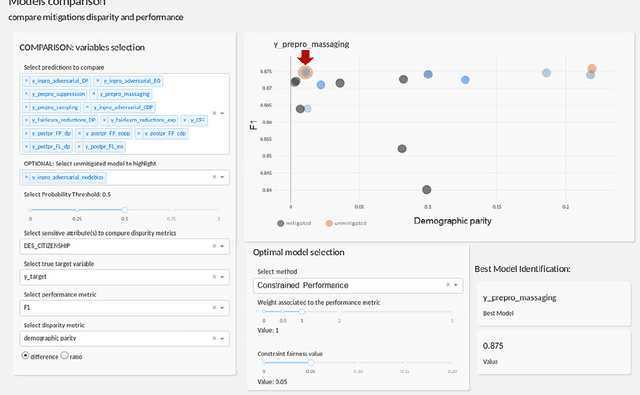
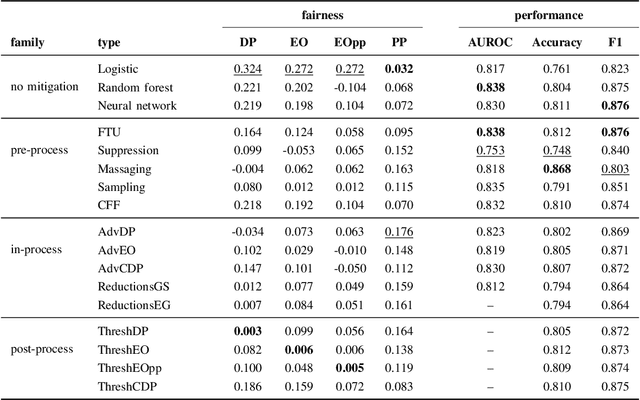
Algorithmic bias mitigation has been one of the most difficult conundrums for the data science community and Machine Learning (ML) experts. Over several years, there have appeared enormous efforts in the field of fairness in ML. Despite the progress toward identifying biases and designing fair algorithms, translating them into the industry remains a major challenge. In this paper, we present the initial results of an industrial open innovation project in the banking sector: we propose a general roadmap for fairness in ML and the implementation of a toolkit called BeFair that helps to identify and mitigate bias. Results show that training a model without explicit constraints may lead to bias exacerbation in the predictions.