 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection in High-Dimensional Bank Account Balances via Robust Methods
Nov 14, 2025



Detecting point anomalies in bank account balances is essential for financial institutions, as it enables the identification of potential fraud, operational issues, or other irregularities. Robust statistics is useful for flagging outliers and for providing estimates of the data distribution parameters that are not affected by contaminated observations. However, such a strategy is often less efficient and computationally expensive under high dimensional setting. In this paper, we propose and evaluate empirically several robust approaches that may be computationally efficient in medium and high dimensional datasets, with high breakdown points and low computational time. Our application deals with around 2.6 million daily records of anonymous users' bank account balances.
HEnRY: A Multi-Agent System Framework for Multi-Domain Contexts
Oct 16, 2024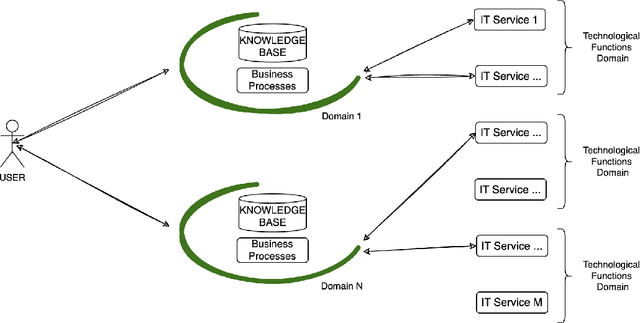
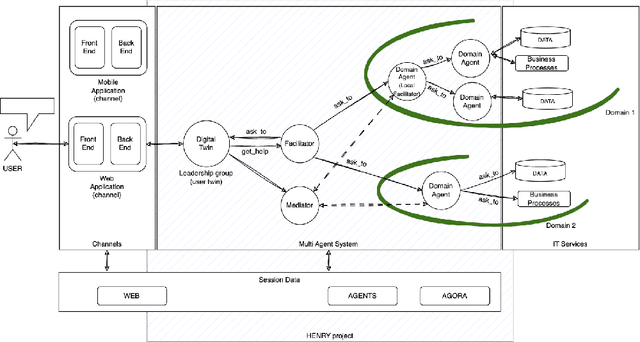
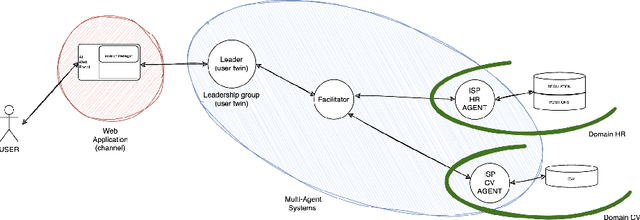
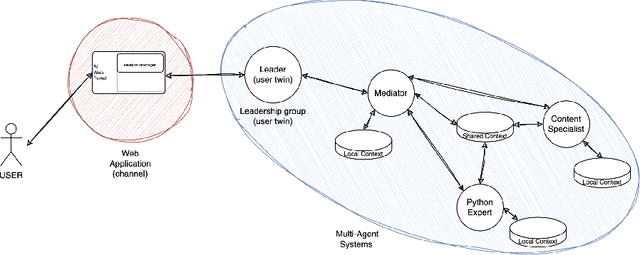
This project, named HEnRY, aims to introduce a Multi-Agent System (MAS) into Intesa Sanpaolo. The name HEnRY summarizes the project's core principles: the Hierarchical organization of agents in a layered structure for efficient resource management; Efficient optimization of resources and operations to enhance overall performance; Reactive ability of agents to quickly respond to environmental stimuli; and Yielding adaptability and flexibility of agents to handle unexpected situations. The discussion covers two distinct research paths: the first focuses on the system architecture, and the second on the collaboration between agents. This work is not limited to the specific structure of the Intesa Sanpaolo context; instead, it leverages existing research in MAS to introduce a new solution. Since Intesa Sanpaolo is organized according to a model that aligns with international corporate governance best practices, this approach could also be relevant to similar scenarios.
Denoising ESG: quantifying data uncertainty from missing data with Machine Learning and prediction intervals
Jul 29, 2024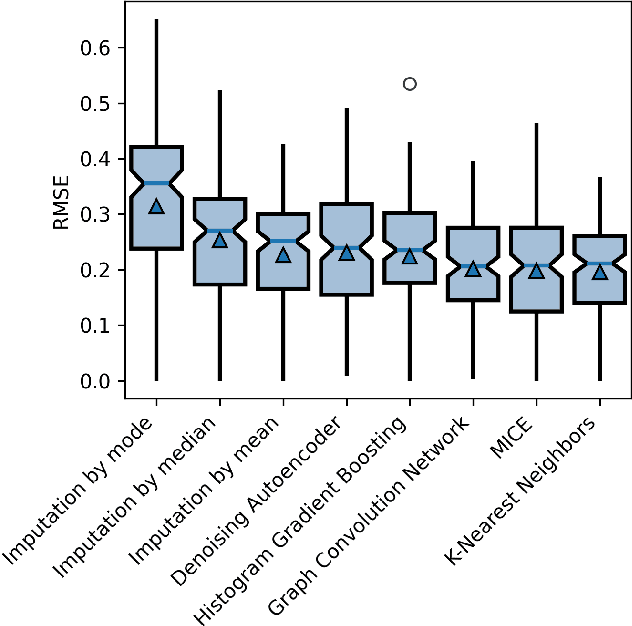


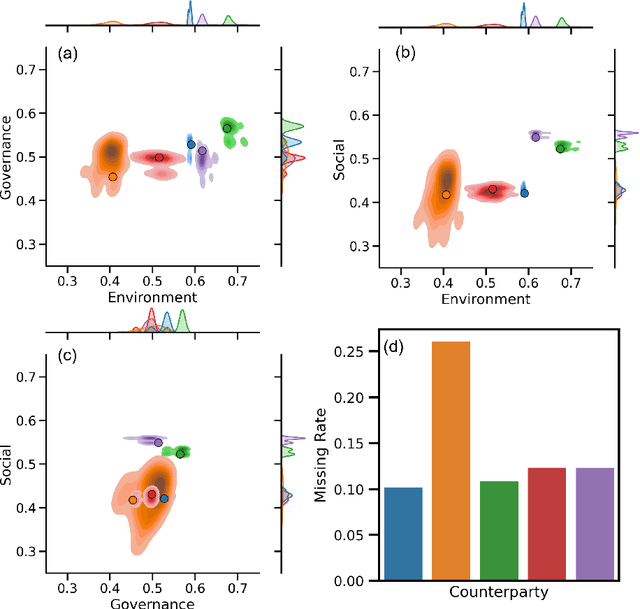
Environmental, Social, and Governance (ESG) datasets are frequently plagued by significant data gaps, leading to inconsistencies in ESG ratings due to varying imputation methods. This paper explores the application of established machine learning techniques for imputing missing data in a real-world ESG dataset, emphasizing the quantification of uncertainty through prediction intervals. By employing multiple imputation strategies, this study assesses the robustness of imputation methods and quantifies the uncertainty associated with missing data. The findings highlight the importance of probabilistic machine learning models in providing better understanding of ESG scores, thereby addressing the inherent risks of wrong ratings due to incomplete data. This approach improves imputation practices to enhance the reliability of ESG ratings.
DTOR: Decision Tree Outlier Regressor to explain anomalies
Mar 19, 2024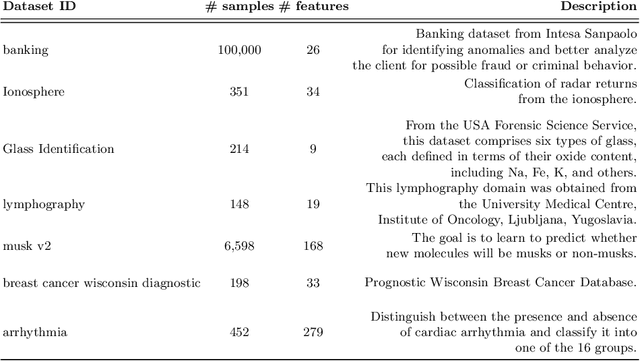
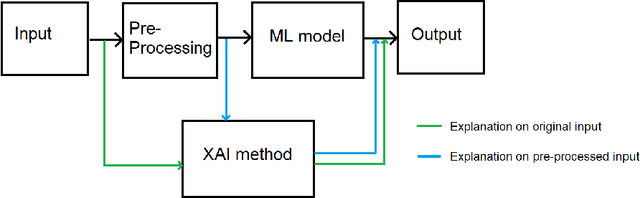
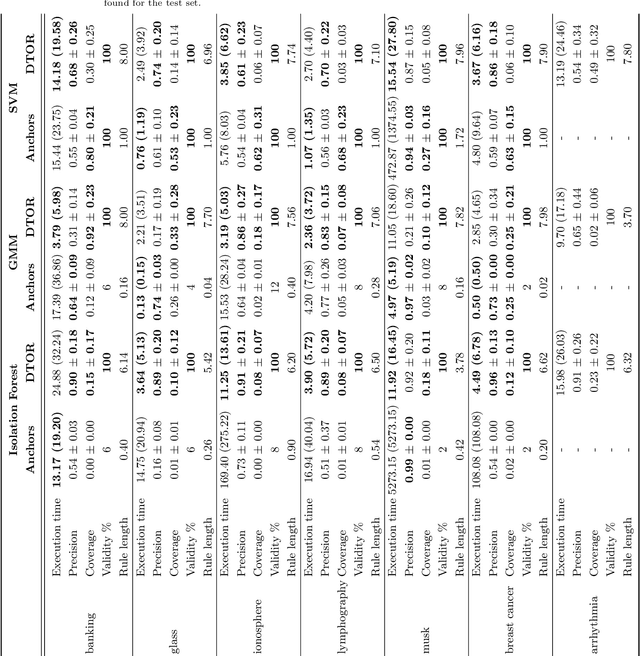
Explaining outliers occurrence and mechanism of their occurrence can be extremely important in a variety of domains. Malfunctions, frauds, threats, in addition to being correctly identified, oftentimes need a valid explanation in order to effectively perform actionable counteracts. The ever more widespread use of sophisticated Machine Learning approach to identify anomalies make such explanations more challenging. We present the Decision Tree Outlier Regressor (DTOR), a technique for producing rule-based explanations for individual data points by estimating anomaly scores generated by an anomaly detection model. This is accomplished by first applying a Decision Tree Regressor, which computes the estimation score, and then extracting the relative path associated with the data point score. Our results demonstrate the robustness of DTOR even in datasets with a large number of features. Additionally, in contrast to other rule-based approaches, the generated rules are consistently satisfied by the points to be explained. Furthermore, our evaluation metrics indicate comparable performance to Anchors in outlier explanation tasks, with reduced execution time.
Deep Learning for Gamma-Ray Bursts: A data driven event framework for X/Gamma-Ray analysis in space telescopes
Jan 28, 2024This thesis comprises the first three chapters dedicated to providing an overview of Gamma Ray-Bursts (GRBs), their properties, the instrumentation used to detect them, and Artificial Intelligence (AI) applications in the context of GRBs, including a literature review and future prospects. Considering both the current and the next generation of high X-ray monitors, such as Fermi-GBM and HERMES Pathfinder (an in-orbit demonstration of six 3U nano-satellites), the research question revolves around the detection of long and faint high-energy transients, potentially GRBs, that might have been missed by previous detection algorithms. To address this, two chapters introduce a new data-driven framework, DeepGRB. In Chapter 4, a Neural Network (NN) is described for background count rate estimation for X/gamma-ray detectors, providing a performance evaluation in different periods, including both solar maxima, solar minima periods, and one containing an ultra-long GRB. The application of eXplainable Artificial Intelligence (XAI) is performed for global and local feature importance analysis to better understand the behavior of the NN. Chapter 5 employs FOCuS-Poisson for anomaly detection in count rate observations and estimation from the NN. DeepGRB demonstrates its capability to process Fermi-GBM data, confirming cataloged events and identifying new ones, providing further analysis with estimates for localization, duration, and classification. The chapter concludes with an automated classification method using Machine Learning techniques that incorporates XAI for eventual bias identification.
Evaluative Item-Contrastive Explanations in Rankings
Dec 14, 2023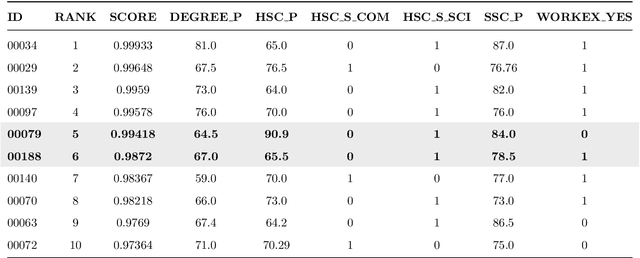
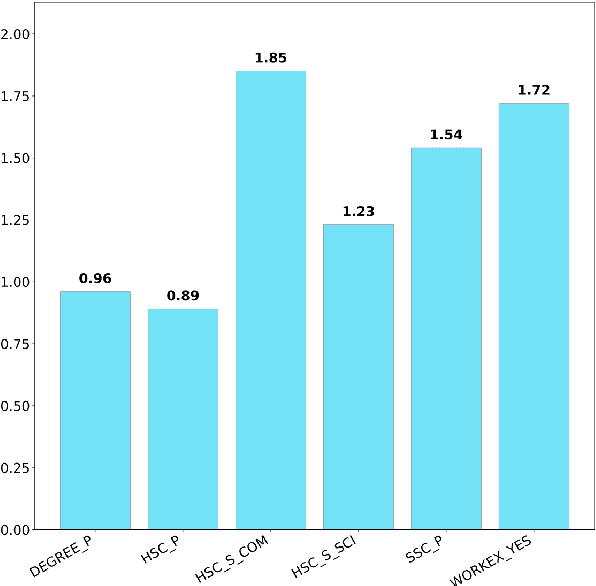
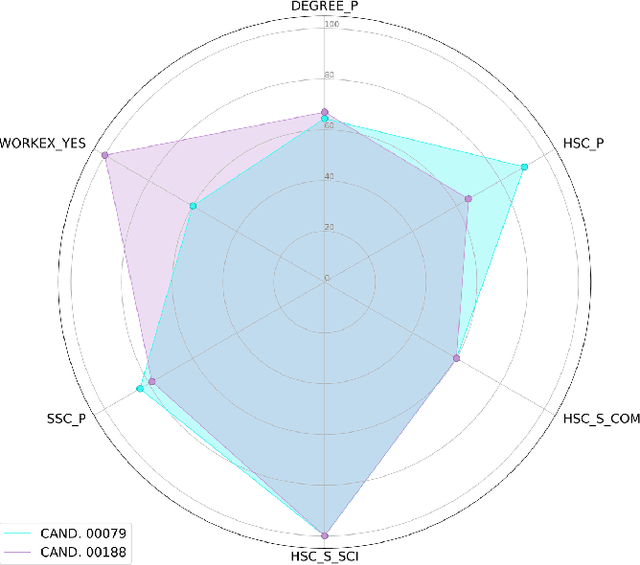
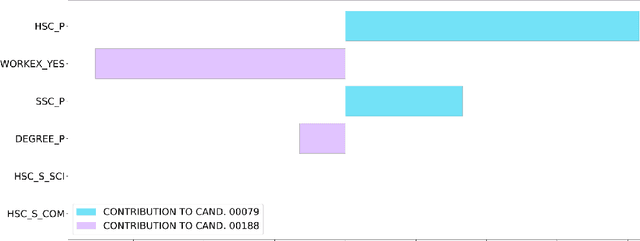
The remarkable success of Artificial Intelligence in advancing automated decision-making is evident both in academia and industry. Within the plethora of applications, ranking systems hold significant importance in various domains. This paper advocates for the application of a specific form of Explainable AI -- namely, contrastive explanations -- as particularly well-suited for addressing ranking problems. This approach is especially potent when combined with an Evaluative AI methodology, which conscientiously evaluates both positive and negative aspects influencing a potential ranking. Therefore, the present work introduces Evaluative Item-Contrastive Explanations tailored for ranking systems and illustrates its application and characteristics through an experiment conducted on publicly available data.
Quantifying Credit Portfolio sensitivity to asset correlations with interpretable generative neural networks
Sep 15, 2023In this research, we propose a novel approach for the quantification of credit portfolio Value-at-Risk (VaR) sensitivity to asset correlations with the use of synthetic financial correlation matrices generated with deep learning models. In previous work Generative Adversarial Networks (GANs) were employed to demonstrate the generation of plausible correlation matrices, that capture the essential characteristics observed in empirical correlation matrices estimated on asset returns. Instead of GANs, we employ Variational Autoencoders (VAE) to achieve a more interpretable latent space representation. Through our analysis, we reveal that the VAE latent space can be a useful tool to capture the crucial factors impacting portfolio diversification, particularly in relation to credit portfolio sensitivity to asset correlations changes.
Searching for long faint astronomical high energy transients: a data driven approach
Mar 28, 2023



HERMES (High Energy Rapid Modular Ensemble of Satellites) pathfinder is an in-orbit demonstration consisting of a constellation of six 3U nano-satellites hosting simple but innovative detectors for the monitoring of cosmic high-energy transients. The main objective of HERMES Pathfinder is to prove that accurate position of high-energy cosmic transients can be obtained using miniaturized hardware. The transient position is obtained by studying the delay time of arrival of the signal to different detectors hosted by nano-satellites on low Earth orbits. To this purpose, the goal is to achive an overall accuracy of a fraction of a micro-second. In this context, we need to develop novel tools to fully exploit the future scientific data output of HERMES Pathfinder. In this paper, we introduce a new framework to assess the background count rate of a space-born, high energy detector; a key step towards the identification of faint astrophysical transients. We employ a Neural Network (NN) to estimate the background lightcurves on different timescales. Subsequently, we employ a fast change-point and anomaly detection technique to isolate observation segments where statistically significant excesses in the observed count rate relative to the background estimate exist. We test the new software on archival data from the NASA Fermi Gamma-ray Burst Monitor (GBM), which has a collecting area and background level of the same order of magnitude to those of HERMES Pathfinder. The NN performances are discussed and analyzed over period of both high and low solar activity. We were able to confirm events in the Fermi/GBM catalog and found events, not present in Fermi/GBM database, that could be attributed to Solar Flares, Terrestrial Gamma-ray Flashes, Gamma-Ray Bursts, Galactic X-ray flash. Seven of these are selected and analyzed further, providing an estimate of localisation and a tentative classification.
Disambiguation of Company names via Deep Recurrent Networks
Mar 07, 2023



Name Entity Disambiguation is the Natural Language Processing task of identifying textual records corresponding to the same Named Entity, i.e. real-world entities represented as a list of attributes (names, places, organisations, etc.). In this work, we face the task of disambiguating companies on the basis of their written names. We propose a Siamese LSTM Network approach to extract -- via supervised learning -- an embedding of company name strings in a (relatively) low dimensional vector space and use this representation to identify pairs of company names that actually represent the same company (i.e. the same Entity). Given that the manual labelling of string pairs is a rather onerous task, we analyse how an Active Learning approach to prioritise the samples to be labelled leads to a more efficient overall learning pipeline. With empirical investigations, we show that our proposed Siamese Network outperforms several benchmark approaches based on standard string matching algorithms when enough labelled data are available. Moreover, we show that Active Learning prioritisation is indeed helpful when labelling resources are limited, and let the learning models reach the out-of-sample performance saturation with less labelled data with respect to standard (random) data labelling approaches.
Investigating Bias with a Synthetic Data Generator: Empirical Evidence and Philosophical Interpretation
Sep 13, 2022
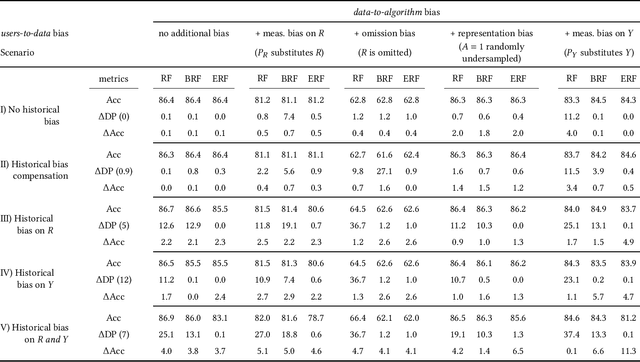
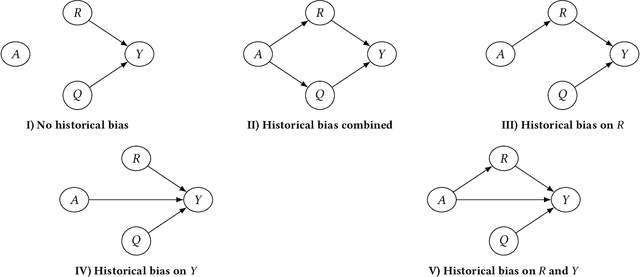
Machine learning applications are becoming increasingly pervasive in our society. Since these decision-making systems rely on data-driven learning, risk is that they will systematically spread the bias embedded in data. In this paper, we propose to analyze biases by introducing a framework for generating synthetic data with specific types of bias and their combinations. We delve into the nature of these biases discussing their relationship to moral and justice frameworks. Finally, we exploit our proposed synthetic data generator to perform experiments on different scenarios, with various bias combinations. We thus analyze the impact of biases on performance and fairness metrics both in non-mitigated and mitigated machine learning models.